





サイバーエージェントは7月9日、日本語と英語に対応した大規模言語モデル「CyberAgentLM3-22B-Chat(以下CALM3-22B-Chat)」を商用利用も可能なライセンスで一般公開した。
オープンな日本語LLMトップクラスの性能
サイバーエージェントは2023年5月に日本語LLM「CyberAgentLM」を一般公開。その後も、2023年11月に「CyberAgentLM2」、2024年6月には画像認識機能を統合したVLM(大規模視覚言語モデル)を公開している。
今回公開されたCALM3-22B-Chatは225億(22B)のパラメータを持ち、2兆トークンで事前学習された言語モデルだ。
様々な日本語処理タスクでLLMの性能を総合的に評価する指標として業界で広く認知されている「Nejumi LLM リーダーボード3」では、700億パラメータのメタ「Llama-3-70B-Instruct」と同等の性能となっており、現時点でオープンな日本語LLMとしてはトップクラスの性能だという。
同モデルは、対話用途に特化して微調整されており、コンテキスト長は1万6384トークン。これにより、複雑な会話や長文の処理が可能となる。
商用利用可能な「Apache License 2.0」のもとで公開されているため、企業や開発者は自社のサービスや製品にこのモデルを組み込むことができる。
デモサイトも公開中
同社は、「Hugging Face」を通じてモデル本体とデモを公開しており、誰でも簡単にアクセスし試すことができる。
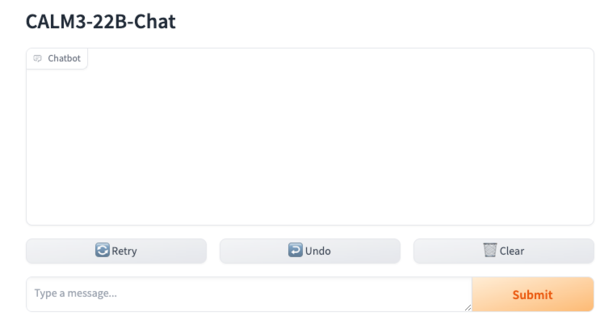
生成された回答の例。読みやすく構造化されており、日本語能力もかなり高いと思われる。生成スピードもかなり速い。
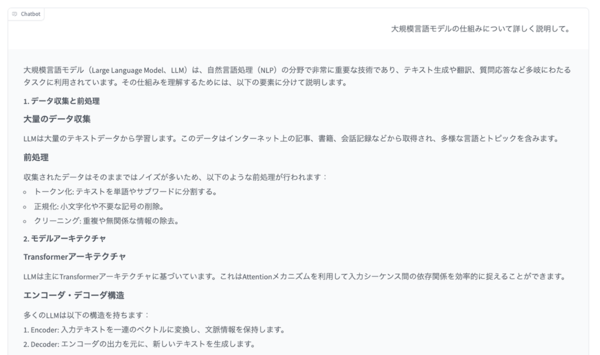
さらに、画面下の「Parameters」をクリックすることで、「最大トークン数」「温度」「Top-p」のパラメーターを調整することも可能だ。

なお「最大トークン数」とは1回の応答で生成するテキストの最大長であり、一度に処理できる入出力の総量である「コンテキスト長」とは異なるので注意が必要だ。
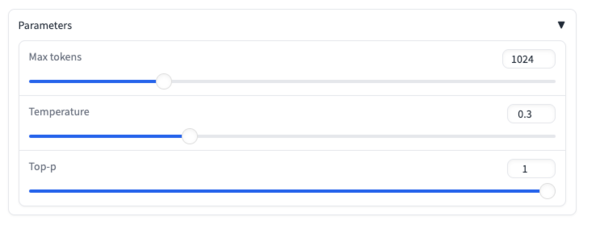
ちなみに「温度」は出力のランダム性や創造性を制御する、「Top-p」は考慮する次のトークンの確率分布を制限するパラメーターだ。
高性能かつ商業利用可能な日本語対応モデルの登場により、国内のAI研究や応用がさらに加速することが期待される。
本記事はアフィリエイトプログラムによる収益を得ている場合があります







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")















