





Stability AIは4月3日、テキストプロンプトから楽曲を生成できるAI「Stable Audio」の新バージョン「Stable Audio 2.0」を発表した。
最大3分の楽曲を高音質で生成可能
Stable Audio 2.0では、生成可能な楽曲の長さをこれまでの最大45秒から最大3分間に拡大。イントロ、展開、アウトロといった構成も踏まえた本格的なステレオ音声の楽曲を、より手軽に生成できるようになった。
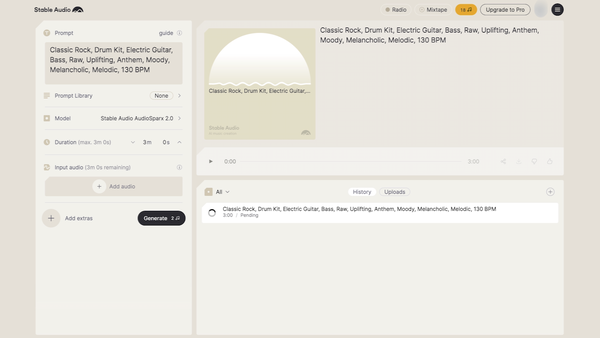
Stable Audio 2.0の操作画面
生成された楽曲ファイルのサンプリングレートは、CDと同じ44.1kHz。無料プランでは不可逆圧縮のMP3か動画のみダウンロード可能だが、有料プランを契約すれば無圧縮の音声ファイル(WAV)も選択できる。
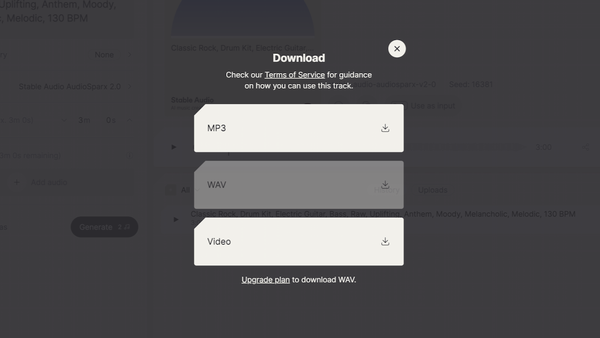
有料プランを契約すればWAV形式でもダウンロード可能
本バージョンでは新機能として、アップロードされた音声サンプルを基に楽曲を生成する「Audio-to-Audio変換」に対応。テキストプロンプトと併用も可能で、より柔軟なアレンジができるようになった。著作権で保護された楽曲素材のアップロードをリアルタイムで防ぐ仕組みも用意されており、コンプライアンスについても一定の配慮がなされている。
ほかにも、バリエーションと効果音の作成や、プロジェクトの特定のスタイルやトーンにあわせた楽曲を生成するスタイル転送機能など、複数の新機能を追加。いずれも無料プラン、有料プランを問わず利用可能だ。
AIの学習データについてはStable Audio 1.0と同様、アーティスト側がAI学習用途への利用可否を選べるAudioSparxのデータを使用。生成された楽曲の商用利用もできるが、こちらは用途に合った有料プランを契約する必要がある。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















