





Stability AIは2月13日、高品質、柔軟性、効率性を重視した新しいテキスト画像変換モデル「Stable Cascade」の研究プレビュー版を、非商用ライセンスの下で公開した。
一般消費者向けハードウェアで実行可能
Stable Cascadeは、「Würstchen(ドイツ語で「ソーセージ」の意味)」と呼ばれるアーキテクチャをベースにした新しいテキスト画像変換モデル。「品質、柔軟性、微調整、および効率性のための新しいベンチマークを設定し、ハードウェアのバリアをさらに排除することに重点を置いた3段階のアプローチにより、一般消費者向けハードウェアでのトレーニングと微調整が簡単にできる」という。
チェックポイントと推論スクリプトだけではなく、微調整、ControlNet、LoRAトレーニング用のスクリプトも公開予定となっており、実現すればStable Diffusionでもお馴染みの様々な手法を試せるようになる。
24x24と極小サイズの潜在空間
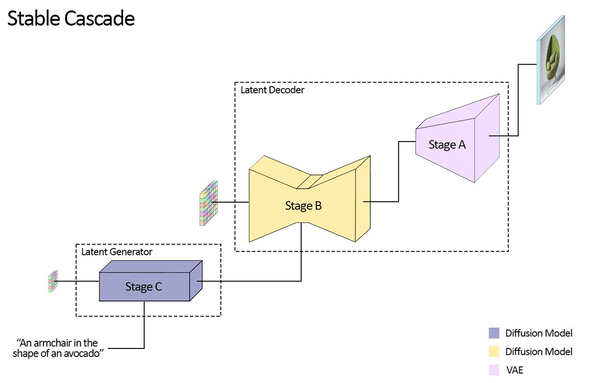
Stable Cascadeは、Stage A、B、Cからなる3つの異なるモデルをパイプラインで繋いだ構成。
最初のステージ(Stage C:Latent Generator)ではユーザーの入力を、Diffusionモデルでわずか24x24という極小サイズの潜在空間に変換する。事前学習、ControlNet、LoRAの学習などはここで処理されるため、通常より乏しいマシンパワーでも可能になるという理屈だろう。
以降は次のステージ(Stage B:Latent Decoder)で、Diffusionモデルを使い、小さい潜在空間から大きい潜在空間へアップスケール。最後のステージ(Stage A:Latent Decoder)でVAE(Variational Auto-Encoder)を使い、潜在空間を画像にデコードするという仕組みだ。
ステージCのパラメーターは1Bと3.6B、ステージBのパラメーターは700Mと1.5Bのものが用意されている。当然大きい方が画像品質は上がるが、必要となるマシンパワーも増大する。
ControlNetも利用可能

Stable Cascadeは通常のText 2 Imageだけではなく、1枚の画像からバリエーションを生成することもできる。

Image 2 Imageにも対応している。左のオリジナル画像にノイズを加え、そこから生成したものが右の4枚だ。
さらに、以下のようなControlNetのコードも公開されるという。

1. インペインティング/アウトペインティング:提供されたテキストプロンプトに従い、画像のマスクされた部分を塗りつぶす。

2. キャニーエッジ:モデルに入力された画像のエッジをたどって新しい画像を生成する。

3. 2倍超解像:ステージCで生成された潜在空間にも使用できる。
SDXL_Turboより優秀?

同社の評価によれば、プロンプトと出力された画像の合致性(アライメント)、そして美的品質の両方において、SDXL Turboを含むほぼすべてのモデルと比べても、Stable Cascadeが最も優れた結果を示したという(※試験でのプロンプトにはparti-promptsとesthetic promptsをミックスしたものを使用。評価は人間による)。

さらに推論速度の比較では、高速生成が売りのモデル「SDXL Turbo」にはさすがに敵わないものの、SDXLとPlayground v2を大幅に上回るとしている。
2月13日12時現在、まだStability.aiのGitHubに該当モデルは確認できないが、「準備ができ次第、Stability AI のGitHubページにあるトレーニングコードと推論コードを公開」するという。
本記事はアフィリエイトプログラムによる収益を得ている場合があります











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")










