




命令を単純化することで命令セットを完成させる
では具体的にどんな形で実装したか? という設計目標が下の画像だ。

RISC-Vの設計目標。ANDFはArchitecture Neutral Distribution Formatの意味で、アーキテクチャー非依存のCPUの上のレイヤーに位置するもの。例えばAndroidではアプリケーションは仮想マシン上で動作するのでCPUがArmでなくても動作するが、この仮想マシンのフォーマットにあたるものがANDFである
ちなみにこの命令セットを策定するにあたり、8/16bitはサポートから落ちている。この件は後にCalista Redmond氏(RISC-V International CEO)に直接聞いたこともあるのだが、過去にもそういう計画はなかったし今後もない、としていた。
基本的に8/16bitは現時点ではまだ市場はあるものの縮小傾向で、そこにリソースを注ぎ込んでも得られるものは少ないという判断だそうだ。この設計目標を受けての実装の目安が下の画像である。

実装と完全に独立とか、MCUからサーバー向けまで同一命令セットといったあたりはわりと意欲的だとは思う
命令セットのモジュラー化はMIPSやArmでも一時期行なっていた。例えばARM7コアの場合、広く利用されているのはARM7TDMIというものだが、これは以下の意味だった。
T:Thumb命令対応
DM:DSP Multiplier
I:ICE対応
ただこれはむしろ面倒くさいということでCortexの世代からは基本なくなっている。「基本」というのは、例えばMCU向けの場合はFPUやDSP拡張がオプション扱いで、最近ではHeliumというSIMD命令もオプション扱いで提供されるからだ。ただ主要な命令は全部入りになった形になっている。
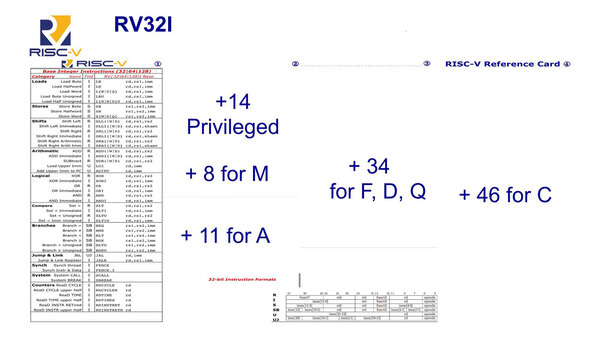
これに対しRISC-Vの場合、基本命令セットは非常に少ない(50命令未満)ため、例えば最小構成のMCU向けでは最低これだけ実装しておけばRISC-Vプロセッサーを実装できる。

RISC-Vの基本命令セット。128bit命令も定義されているのは、先を見越してのことだろう
それ以外に、以下の拡張命令が用意されている。
M:整数乗除算
A:アトミック命令
F:単精度浮動小数点演算
D:倍精度浮動小数点演算
Q:4倍精度浮動小数点演算
ちなみにこのリストにはないが、他にB(ビット操作命令)/C(圧縮命令)/L(10進浮動小数点演算)/V(ベクトル演算命令)などがあるほか、今後の拡張予定としてJ(動的変換命令:Javaなどの仮想マシンに対応したもの)/P(Packed-SIMD命令)/T(トランザクションメモリー命令)などがすでに予約されている。
こうした拡張命令は、それが必要と思う場合に実装すればよいことになっている。これとは別にG(General)が定義されているが、上の画像にあるようにIMAFDの略であり、“RV64IMAFD”とか書かずに“RV64G”と書けば済む、という話である。
この命令の単純化は、ある種の割り切りで実現している。RISC-Vは3オペランドの命令に対応しているので、例えば加算のaddは下のフォーマットになる。
add rd, rs1, rs2
この場合rd = rs1 + rs2という処理がされるのだが、この際に計算がオーバーフローするかどうかのチェックは行なわない。したがって実際には以下の処理が必要になる。
add rd, rs1, rs2
slti rs3, rs2, 0
slt rs4, rd, rs1
bne rs3, rs4, overflow
x86ではadd命令を実行した後にFlag registerをチェックして、OF(Overflow Flag)が立っていたら例外処理に移るので2命令で判断できるわけだが、これが4命令に倍増することになる。
ただこれに対するAsanović教授の考え方は「こういう処理はMacro-Op Fusionを使うことで実質的な処理命令数を減らせる」というものである。
add命令にあれこれオプションを追加するとそれだけ命令数も増えるし実装も大変になる。昨今のアプリケーションプロセッサーは、複数の命令をまとめて処理するMacro-Op Fusionの実装がごく当たり前なので、このメカニズムを使えば実質的な処理性能を引き上げできる。こう割り切ってしまったことで、こと基本命令セットに関しては本当にシンプルになった。
これは32bitのRV32Iだが、64bitのRV64Iも基本同じである
この基本的な命令セットは2011年中に完成する。これを自身の研究の傍らに行なうのはなかなか難易度が高いというか、かなり忙しかっただろうと思うのだが、この後のRISC-V FoundationとSiFiveの設立に向け、Asanović教授はさらに忙しくなっていく。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































