



クラウド時代に考える“ワークロード特化型”インテル® Xeon® プロセッサーの価値
プロセッサーとしての“基礎体力”強化×特定処理の“技術”搭載で大幅なパフォーマンス向上
AI/データ分析ワークロードを「効率的に」処理できる第4世代 インテル® Xeon® スケーラブル・プロセッサー
2023年06月05日 11時00分更新


最新のデータセンター向けCPU「第4世代 インテル® Xeon® スケーラブル・プロセッサー」
あらゆる企業がDX(デジタルトランスフォーメーション)実現に向けた取り組みを進める現在。そのDXの中核をなすのが「データ活用」だ。リアルタイムなデータの分析と可視化によるデータドリブン経営、IoTデータを利用した業務の効率化/自動化、さらには各種AI技術を取り込んだ新サービスの開発など、データ活用は現在のビジネス変革におけるキードライバーとなっている。
ただし、データ活用が拡大することで、データを高速処理できるITインフラの必要性も高まる。たとえば、従来の業務アプリケーションとは比べものにならないほどの大量データをリアルタイムに分析処理するとなると、企業はデータセンター/サーバーインフラそのものを考え直さなければならない。
インテルでは最新のデータセンター向けCPU「第4世代 インテル® Xeon® スケーラブル・プロセッサー」(第4世代 インテル® Xeon® SP)において“ワークロード特化型”という新たなアプローチを取り、高いパフォーマンスと効率性を実現している。データ分析であれば前世代比で「最大3倍」、AIであれば「最大10倍」という、大幅なパフォーマンス向上だ※注。どのようにしてそれが可能になったのか、本記事ではその技術背景や、導入企業におけるメリットについて詳しく見ていこう。
※注:インテル実施のベンチマークテストに基づく(以下、本文中のテスト結果はすべて同様)。
第4世代 インテル® Xeon® SPで“基礎体力”が1.5倍に向上
第4世代 インテル® Xeon® スケーラブル・プロセッサーは、2023年1月に国内発表された最新のデータセンター向けCPUシリーズだ。すでに主要サーバーメーカー各社からは、この最新CPUを搭載したサーバー製品が多数発売されている。
最新アーキテクチャを採用したことで、第4世代 インテル® Xeon® スケーラブル・プロセッサーでは、汎用ワークロードにおけるパフォーマンスそのものが向上している。
たとえば、1ソケットあたりのコア数が最大60コアと拡大されたことに加え、1クロック当たりの命令数を増加させるマイクロアーキテクチャの改良、L2/L3キャッシュの拡大などによって、CPUコアあたりのパフォーマンスが強化された。CPUコア以外のプラットフォーム部分でも、PCIe Gen5、CXL(Compute Express Link)1.1、UPI(Ultra Path Interconnect)2.0といった新世代の高速インタフェースの採用、DDR5やHBM(High Bandwidth Memory)2eメモリへの対応といった強化がなされている。
インテルが前世代プロセッサーと比較するベンチマークテストを行った結果、第4世代 インテル® Xeon® スケーラブル・プロセッサーでは平均53%ものパフォーマンス向上が見られた。いわば“基礎体力”が1.5倍に向上しているわけだ。

第4世代 インテル® Xeon® スケーラブル・プロセッサーが備える特徴的な技術。新アーキテクチャを採用してノード単体性能を向上したほか、サーバーとしてデータセンターに組み込まれた際の運用性能、セキュリティも強化している
インテルが重視する「実環境のワークロード性能」とは?
ただし、第4世代 インテル® Xeon® スケーラブル・プロセッサーの最大の特徴はそこではない。今回の発表においてインテルは、「実環境のワークロード性能を優先させたアーキテクチャー」を採用したことを強調している。さて、この「実環境のワークロード性能を優先させた」とは、一体どういう意味だろうか。
パブリッククラウドの利用が普及した結果、オンプレミスとクラウドのハイブリッド環境を“適材適所”で利用したいというニーズが高まっている。その結果、オンプレミスシステムは特定のワークロード処理を目的に構築されるケースが増えた。ここで、それぞれのワークロード特性に最適化されたシステムが構築できれば、システムの導入価値はさらに高まる。
その他の一般的なワークロードと比較して、データ分析のワークロードにはどんな特性があるだろうか。分析ワークロードでは、データベースやデータレイクに蓄積された大量のデータを収集し、選別/整形したうえで分析処理を実行する。その際には、CPUとストレージの間で大量のI/Oが発生する。最近では超高速なインメモリデータベースも普及しているが、その場合はCPUとメモリの間のI/Oが膨大な量になる。
AIワークロードを考えてみても、AIモデルを作成(学習)するステップではトレーニングデータの収集や選別/整形を行うため、データ分析と同様に大量のストレージI/OやメモリI/Oが発生する。それに加えて、CPUから処理をオフロードするGPUやFPGAとの高速なインタフェースも欠かせない。
このように、ワークロードごとに処理の特性は異なるため、一般的な汎用ワークロード性能だけを考えても見えてこない「実環境のワークロード性能」こそ、重要視すべきものになっているのだ。
新たな一手は特定の処理を効率化する「アクセラレーター」の搭載
前述したとおり、最新の第4世代 インテル® Xeon® スケーラブル・プロセッサーはCPUコア性能を高め、広帯域なストレージI/OやメモリI/Oを備えており、PCIe Gen5、CXLといった次世代のGPU/FPGA接続インタフェースにも対応している。
先ほどはこうした基本性能を“基礎体力”と表現したが、CPU設計技術が極限まで高度化している現在、いきなり基礎体力を数倍伸ばすことは難しい。だが、特定のワークロードにおいて、その“基礎体力”をより効率良く使う“技術”を身につければ、まだ大幅に高速化できる余地がある。最新プロセッサーへのこの“技術”の搭載こそが、インテルが考えた新たな一手である。
具体的に言えば、第4世代 インテル® Xeon® スケーラブル・プロセッサーでは、CPUパッケージの中に特定の処理を効率化するアクセラレーターエンジンが複数内蔵されている。これらを活用することで、データ分析やAI、ネットワーク/5G RAN、HPCなど、性能要件の特に厳しいワークロードにおける処理を効率化し、高速化するわけだ。

第4世代 インテル® Xeon® スケーラブル・プロセッサーでは、特定のワークロード/目的に応じたアクセラレーターを搭載して、より効率的な処理を可能にしている
たとえばデータ分析のワークロード向けには、「インテル® Analytics Engines」と総称されるアクセラレーターやテクノロジーを搭載している。それぞれ次のような役割を持つ。
●インテル® IAA(In-Memory Analytics Accelerator):データベースと分析のワークロードを高速化するアクセラレーター。
●インテル® DSA(Data Streaming Accelerator):ストリーミングデータの移動/変換処理を高速化するアクセラレーター。
●インテル® QAT(Quick Assist Technology):データベースやビッグデータの圧縮、暗号化を高速化するテクノロジー。
これと同じように、AIワークロード向けには「インテル® AI Engines」のテクノロジー群が搭載されている。
●インテル® AMX(Advanced Matrix Extention):行列計算処理を効率化し、ディープラーニングの学習や推論を高速化する命令セット。
●インテル® AVX-512(Advanced Vector Extention 512):機械学習など、演算負荷の高いワークロードを高速化する新たな命令セット。
AIワークロードで10倍、データベース処理で2.9倍の大きな性能向上
さて、こうしたアクセラレーターエンジンやテクノロジーを採用したことで、インテルが重視する「実環境のワークロード性能」はどのくらい向上するのだろうか。
インテルが実施したベンチマークテストによると、AIワークロードでは、PyTorchのトレーニングとリアルタイム推論の処理をインテルAMXが効率化することで、前世代比最大10倍のパフォーマンス向上が実現する。そのほか、自然言語処理モデルBERTのトレーニングで最大4倍、BERTによるリアルタイム推論で最大2.6倍、顔認識で最大2.6倍などの性能も確認されている。
データ分析ワークロードの一部であるデータベース処理でも、インテルIAAによってRocks DBのパフォーマンスは最大2.1倍向上する。インテルDSAなどそのほかのテクノロジーの効果も含め、Rocks DBの総合パフォーマンスは前世代比2.9倍に向上している。
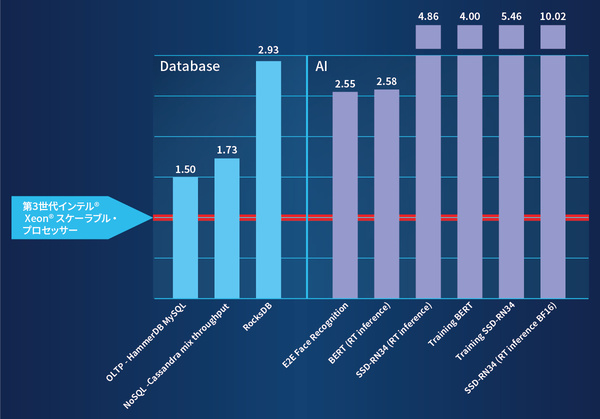
第4世代 インテル® Xeon® スケーラブル・プロセッサーのベンチマークテスト結果(前世代比の性能倍率)
ESG経営などの動きもあり、近年では環境負荷の少ないグリーンITの取り組みが盛んになっている。第4世代 インテル® Xeon® スケーラブル・プロセッサーでは、搭載したアクセラレーターが処理を効率化するため、エネルギー効率(消費電力あたりの処理性能)の向上にもつながっている。前世代プロセッサーと同じワークロードを、より少ないサーバー台数でまかなうことができるのだ。
インテルの試算によると、たとえばデータベース処理(Rocks DB)の場合、前世代プロセッサー搭載サーバーでは50台が必要だった処理を、第4世代 インテル® Xeon® スケーラブル・プロセッサー搭載サーバーではわずか18台でまかなうことができる。これにより消費電力が大きく削減され、4年間で366トンのCO2排出量を抑えられる。電力料金も含めたTCOでは120万ドル、52%の削減効果だ。AIワークロードも同様であり、アクセラレーターが絶大な効果を発揮する。
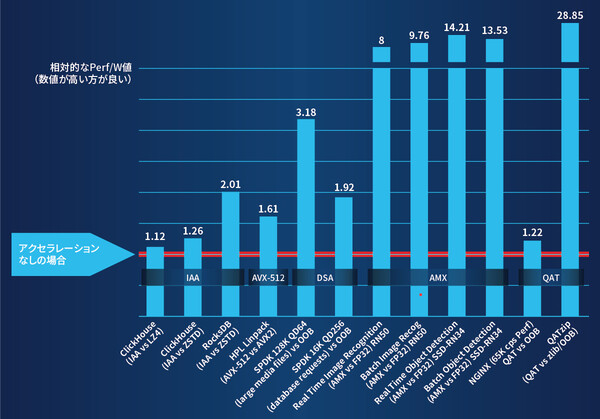
アクセラレーターを使用した場合のエネルギー効率(アクセラレーターを使用しない場合との比較)
第4世代 インテル® Xeon® スケーラブル・プロセッサーは、すでに多くの企業や研究機関から注目され、採用が進んでいる。たとえばビッグデータを用いたデータ化学やAIの研究に⽤いる新システムや、インメモリ/メニーコアで性能がリニアにスケールするRDBの開発に取り組む企業など、第4世代 インテル® Xeon® スケーラブル・プロセッサーにより高い性能が発揮されることが期待されている。
* * *
今回の記事では、最新の第4世代 インテル® Xeon® スケーラブル・プロセッサーを導入することで、データ分析やAIのワークロードがいかに効率良く、高速に処理できるようになるのかを見てきた。
ビジネスにおけるデータ活用がDX実現の鍵を握ると言われるようになって久しいが、ITインフラを選択する視点はその変化に追いついているだろうか。これからのインフラ構築には、プロセッサー分野におけるこうした新しい動きも理解したうえで取り組んでいただきたい。その際にはきっと、第4世代 インテル® Xeon® スケーラブル・プロセッサーが有力な候補として上がるはずだ。
6月19日、20日
技術とビジネスをつなぐ「Intel Connection 2023」開催!
参加登録(無料)受付中

「技術とビジネスをつないで新しいことを始めよう」をメインテーマに、業界の垣根や技術者/経営者の枠を超え、企業間の連携を高めてDcXをさらに推進し、日本の次世代を育て、未来を創るカンファレンスイベントです。
2日間、4つの基調講演と8テーマの分科会(AI、DX、サステナビリティー、教育、自治体の取り組み、デバイスソリューション、データ&インフラストラクチャー、イノベーション)、ソリューション紹介展示を行います。ぜひご来場いただき、新たなビジネスを創出する場としてご活用ください。
・開催日時:2023年6月19日(月)、20日(火)09:30~17:30
・会場:東京ミッドタウン ホール A+B(東京・六本木)
・主催:インテル株式会社
・入場料:無料(事前登録制)
(提供:インテル)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
sponsored
“HPC専用”で性能強化! 広帯域メモリ内蔵のインテル® Xeon® CPU Maxシリーズ -
sponsored
第4世代 インテル® Xeon® SPが5G/ネットワークのイノベーションを加速させる - この連載の一覧へ



