




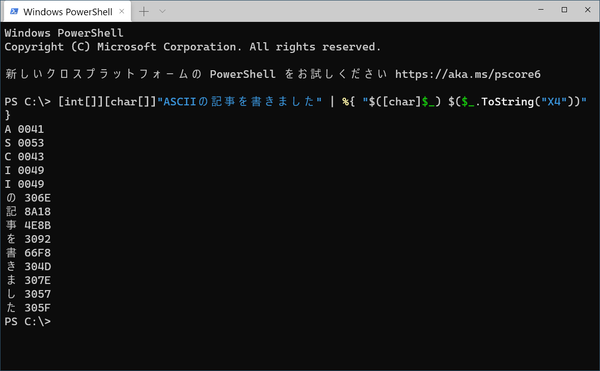
Windows PowerShellを使えば、文字コードを簡単に調べることができる。パターンさえ覚えれば、プログラミングの知識は不要で、アプリを別途インストールする必要もない
コンピュータを使っていると、文字コードを調べなければならないことがある。昔なら文字コードは8bitしかなかったので、ASCIIコード表からすぐだったが、現在は多数の言語の文字を収録したUnicode(ユニコード)が一般的なので、一覧表から調べることは難しい。
文字1つぐらいならインターネット検索でもなんとかなるが、2つ、3つとなると面倒だ。かといって、文字コードを調べるソフトウェアを探してインストールするのもまた面倒。こういうときには、Windowsの標準機能を使うといい。
Windowsには、「文字コード表」というプログラムもあるが、一覧から文字を探して、そのコードを表示することはできるが、文字そのものから直接コードを教えてくれるわけではない。こういうときには、Windows PowerShellが利用できる。ここでは、ブラウザやプログラムが出力した文字をクリップボードなどでコピーして、その文字の文字コードを調べる方法を解説する。
実際に調べる前にちょっとした準備を
Windows PowerShellには、さまざまな文字セットと文字エンコーディングを扱うことができるが、それを動かすコンソールウィンドウが旧式であるため、表示に制限がある。これを解消するには、Windows PowerShellをWindows Terminalで動かす。Windows Terminalは、Microsoftストアから簡単にインストールできるほか、以前解説したwingetを使うことも可能だ(「一般向けの配布も開始されているWindows用のパッケージ管理ツール「winget」がv1.1に」)。
●Windows Terminal
https://www.microsoft.com/ja-jp/p/windows-terminal/9n0dx20hk701?SilentAuth=1&wa=wsignin1.0&activetab=pivot:overviewtab
初めてWindows Terminalをインストールして、起動するとWindows PowerShellが起動してターミナルウィンドウが開くはずである。基本的な使い方はこれで問題ないが、標準状態では、一部の文字が文字化けすることがある(文字化けするのはWindows PowerShellだけでPowerShell 7やプレビューは文字化けしない)。
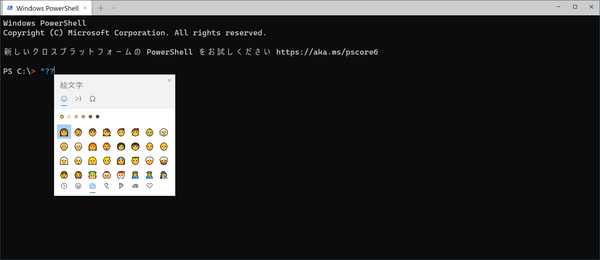
Windows 10/11に付属のWindows PowerShellでは、絵文字を入力しようとすると文字化けしてしまう。なお、表示は化けるが、PowerShellには正しく文字が伝わっている
たとえば、絵文字を入れると正しく表示されず、入力上は「??」となる。ただし、PowerShell側には正しく伝わっており、これは単に表示だけの問題である。解消するには以下のコマンドを入れる(以下のコマンドをコピーしてCtrl+VでWindows Terminalに貼り付ければよい)。
[System.Console]::OutputEncoding=[System.Text.Encoding]::UTF8
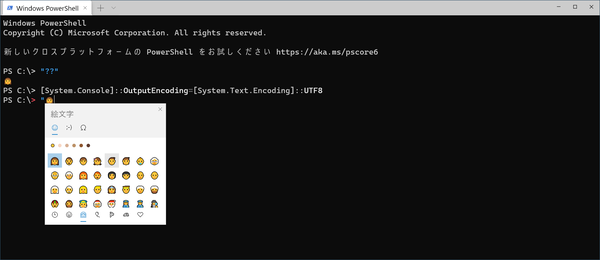
入力文字エンコードを切り替えるコマンドで、文字化けを解消できる。他の実行例でも前提となっている
これで文字入力時に文字化けしなくなる。また、以後の実行例では、この設定をしているのが前提となっている。
文字と文字コード
文字と文字コードは、実は同じデータの表示方法が違うだけだ。メモリの中では、すべて1と0からなるデジタルデータになっている。このデータを文字コードだとして表示させれば文字になるし、整数値だとして表示すれば数字になる(実際には整数値を表す文字列を計算している)。
クリップボードに文字がはいっているとき、それを文字として扱うには、ダブルクオートを両側においてEnterキーを押す。いま、クリップボードには「漢」という文字が入っていると仮定する。PowerShellでは、ダブルクオートで囲まれた部分を文字列という。複数の文字を入れることができるが、ここでは「漢」1文字だけである。
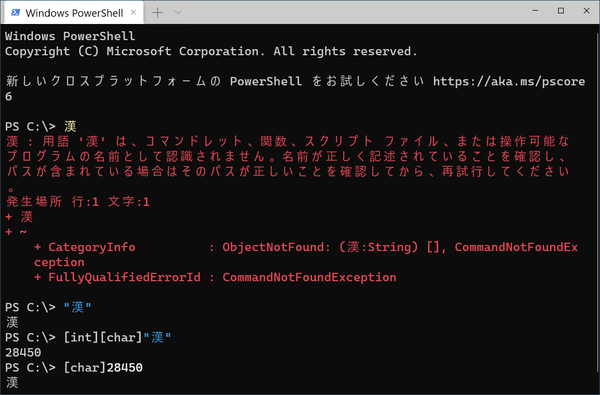
文字をそのまま入力してまうとエラー(赤い字の部分)だが、ダブルクオートでくくれば、文字列データとして認識されて、そのまま表示できる。“[int][char]”をつければ文字コードに、逆に数値に“[char]”を付ければ文字になる
では、その文字コードを表示させてみよう。カーソルキーの上矢印を押せば、さっき入力したコマンド行があらわれる(ヒストリ機能)。ここでHomeキーを押してカーソルを先頭にもっていき、“[int][char]”と入力する。その後Enterキーを押せば、今度は文字ではなく数字が表示される。これが「漢」の文字コードである。
“[int][char]”は、意味としては、文字列を文字(char)として扱い、そのあと整数(int)として扱えという指示である(これをキャストという)。PowerShellの中では、すべてのデータには「型」がある。ダブルクオートで囲まれたものは、すべて文字列型だ。キャストとは「鋳造」の意味で、「別の型にはめる」ことを意味する。
表示された数字が文字コードだが、文字コードといってもいろいろなものがある。文字コードは、「文字セット」と「エンコード」で決まる。文字セットは文字の集合で文字1つ1つにコードを割り当てる。エンコードは、このコードをどのようなビットパターンで表現するのかを決める。このため、同じ文字であっても、エンコードが違うとビットパターンが異なるものになる。
現在のWindowsでは、文字セットに「Unicode」を使い、エンコードには、UTF-16という方式を使う。表示された数字は、Unicodeの文字に割り当てられた番号(Unicodeではコードポイントという)をUTF-16という形式にした場合の数字だ。
逆に文字コードを文字にしてみよう。先ほど表示された文字コードである「28450」を使って「[char]28450」と入力してEnterキーを押してみる。ちゃんと「漢」と表示された。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第520回
PC
WindowsターミナルのPreview版 v1.25では「操作」設定に専用エディタが導入 -
第519回
PC
「セキュアブート」に「TPM」に「カーネルDMA保護」、Windowsのセキュリティを整理 -
第518回
PC
WindowsにおけるUAC(ユーザーアカウント制御)とは何? 設定は変えない方がいい? -
第517回
PC
Windows 11の付箋アプリはWindowsだけでなく、スマホなどとも共有できる -
第516回
PC
今年のWindows 11には26H2以外に「26H1」がある!? 新種のCPUでのAI対応の可能性 -
第515回
PC
そもそも1キロバイトって何バイトなの? -
第514回
PC
Windows用のPowerToysのいくつかの機能がコマンドラインで制御できるようになった -
第513回
PC
Gmailで外部メール受信不可に! サポートが終わるPOPってそもそも何? -
第512回
PC
WindowsのPowerShellにおけるワイルドカード -
第511回
PC
TFS/ReFS/FAT/FAT32/exFAT/UDF、Windows 11で扱えるファイルシステムを整理する -
第510回
PC
PowerShellの「共通パラメーター」を理解する - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























