




かつてWindowsでテキストファイルといえばシフトJIS形式のものが大半だった。しかし最近では、UTF-8形式のテキストファイルも普通に見かけるようになってきた。世の中はUTF-8が主流になりつつあると言っていいだろう。
しかし、WindowsでUTF-8を使うと、ちょっと困ったことがある。それは、エクスプローラーの検索欄などで用いるWindows Searchが、UTF-8にはしっかり対応していないのである。正確に言うと、Windows Searchはファイル先頭に「BOM」のあるUTF-8は認識して正確にインデックス化し、ファイルの全文検索が可能になるが、BOMのないUTF-8では正しくインデックス化できず、ファイルの全文検索はASCIIコードのみ可能で、日本語などの非ASCII文字では全文検索ができない。
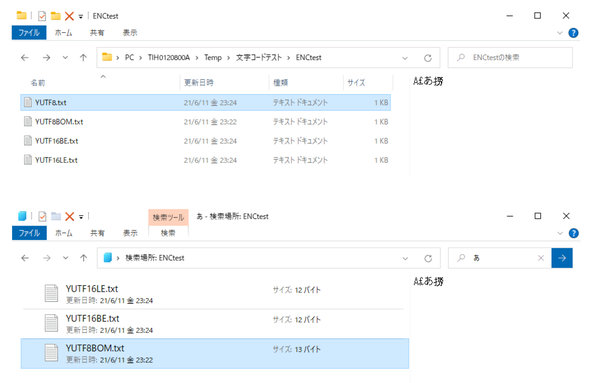
同じ内容のテキストをUTF-8、UTF-8 BOM付き、UTF-16ビッグエンディアン、UTF-16リトルエンディアンでエンコードして4つのファイルにした。どのファイルにも含まれるはずの「あ」で検索すると、UTF-8(BOMなし)のファイルだけが検索結果に入らない
世の中はUTF-8形式が普及しつつあるが、BOMは必須とされていないため、BOMのないUTF-8のデータも少なくない。また、Windowsの「標準テキストエディタ」とでもいうべきメモ帳も、「19H1」(May 2019 Update)からBOMのないUTF-8を標準とするようになった。自分たちがそうしているのに、だ。繰り返しになるが、UTF-8の日本語テキストは、Windows Searchでは日本語で全文検索ができない。全文検索したければ、BOM付きのUTF-8形式でファイルを保存するしかない。このあたり話がややこしいので、今回は少し整理してみたい。
そもそもUTF-8とは?
UTF-8とは、Unicode文字をエンコードする方法の1つだ。Unicodeでは文字に「符号位置」(いわゆるコード)があり、これをファイルなどに格納する場合にどのようなビットパターンにするのかを決めるのが「エンコーディング」である。
Unicodeの「符号位置」は16進数表現を使って「U+3042」などと表す。これをファイルに書き込むとき、どのようなビットパターンにするのかを決める「エンコーディング」には、UTF-8、UTF-16などの形式がある。UTFは、Unicodeでは「Unicode Transformation Format」の略とされている。このほかにもUTF-7やUTF-32もあるが、ファイル形式としてはあまり見かけない。
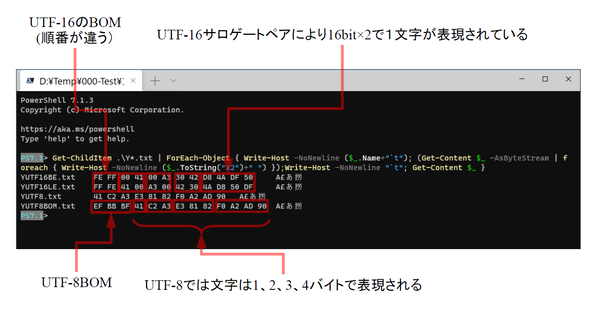
UTF-16BE(ビッグエンディアン)、UTF-16LE(リトルエンディアン)、UTF-8(BOMなし)、UTF-8(BOM付き)のファイルを16進で表示したところ。PowerShell 7.1ではファイルのエンコード自動判定が動くので、どのファイルも正しく内容を表示できる。ちなみにWindows PowerShell 5.1では、BOMなしUTF-8を正しく表示できない
UTF-8とは、符号位置を1~4バイトにエンコードする。このとき、バイト単位でのアクセスを想定し、前方に符号位置の上位桁が来るように並べる。
Windowsでは、内部的にはUTF-16を使っている。UTF-16は1文字をすべて16bitで表現するための方式だが、Unicodeに多数の文字が収録された現在では、一部の文字を16bit文字2つで表現する(これをサロゲートペアという)。
ややこしいことにマイクロソフトは、UTF-16を「Unicode」と呼んでいるのだ(初期のUnicodeは16bitに世界中のすべての文字を入れる計画だった)。UTF-16では、CPUが扱う16bitで文字を表現するため、CPUのエンディアンが影響する。このために必要なのがBOM(Byte Order Mark)となる。
BOMは「U+FEFF」という符号位置をエンコーディングしたものだ。これを見ることで、エンディアンを区別することが可能になる。Windowsでは、リトルエンディアンを基本としているため、UTF-16(Unicode)もリトルエンディアンを使う。Windowsに付属する一部のプログラムは、ビックエンディアンのUTF-16には対応していない。たとえば、エクスプローラーのプレビュー領域では、ビックエンディアンのUTF-16を表示できない(だけど検索はできる)。
UTF-8では、バイト単位でデータを扱えるようにエンコードを決めた物なのでエンディアンの違いは発生しない。仕様上、BOMは禁止されていないが、必須とされているわけでもない。正しくUTF-8に対応しているなら、BOMがあってもなくても問題は発生しないが、ファイルの先頭にBOMが付いていると7bit ASCIIを期待しているプログラムで問題を引き起こす可能性がある。なお、UTF-8のBOMは16進表現で「EF BB BF」である。
日本のシフトJISのようなUnicode以前の2バイト文字コードとUTF-8の区別は困難な場合がある。場合によっては、ファイルを最初から最後まで調べてもどちらか判定できないこともある。おそらくはそれが理由で、ExcelなどMicrosoft系のソフトは、BOM付きのUTF-8を受け付けるのだと思われる。
つまり、テキストファイルの場合は、UTF-8のBOMがあればUTF-8と判定し、そうでなければシフトJISと推定するのであろう。Windows Searchも同様の仕組みになっていると思われる。シフトJISでは、UTF-8のBOMの先頭にある「EF BB」が未割り当てであり、正しいシフトJISの「テキストファイル」ならばこのコードが入ることはないため、UTF-8のBOMと推定することが可能だからだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第521回
PC
Windowsでアプリをインストールしたときに警告が表示する「Defender SmartScreen」と「Smart App Control」 -
第520回
PC
WindowsターミナルのPreview版 v1.25では「操作」設定に専用エディタが導入 -
第519回
PC
「セキュアブート」に「TPM」に「カーネルDMA保護」、Windowsのセキュリティを整理 -
第518回
PC
WindowsにおけるUAC(ユーザーアカウント制御)とは何? 設定は変えない方がいい? -
第517回
PC
Windows 11の付箋アプリはWindowsだけでなく、スマホなどとも共有できる -
第516回
PC
今年のWindows 11には26H2以外に「26H1」がある!? 新種のCPUでのAI対応の可能性 -
第515回
PC
そもそも1キロバイトって何バイトなの? -
第514回
PC
Windows用のPowerToysのいくつかの機能がコマンドラインで制御できるようになった -
第513回
PC
Gmailで外部メール受信不可に! サポートが終わるPOPってそもそも何? -
第512回
PC
WindowsのPowerShellにおけるワイルドカード -
第511回
PC
TFS/ReFS/FAT/FAT32/exFAT/UDF、Windows 11で扱えるファイルシステムを整理する - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























