




一週開いてのAIプロセッサーだが、今回はCompute-in-Memoryタイプのプロセッサーの話だ。Compute-in-Memoryというと連載591回で紹介したMythicが出てくるが、ここはフラッシュメモリーをそのままアナログ演算器として使うという、分類としてはアナログコンピューターに分類される(そう分類せざるを得ない)構造で、その意味では他と比較できない製品である。
対して今回紹介するのはもっと力業である。今年2月16日、Samsung Electronicsはプレスリリースを出し、HBM(High Bandwidth Memory:高帯域幅メモリー)にAIプロセッサーを組み込んだHBM-PIM(Processing-In-Memory)を開発したことを発表した。このHBM-PIM、今年のISSCC(International Solid-State Circuits Conference:半導体業界最大級の国際学会)でその概略が紹介されたので、これをもとに説明しよう。

プロセッサーが消費電力を費やすのは
6割が演算で4割がデータアクセス
Mythicの時にも説明したが、現在のプロセッサーにおいて少なくない消費電力を費やしているのは、演算ユニットそのものではなくデータアクセスである。下の画像はArmがEthos-N57の発表に先立ち、まだProject Trilliumとして説明されていたころの説明資料である。
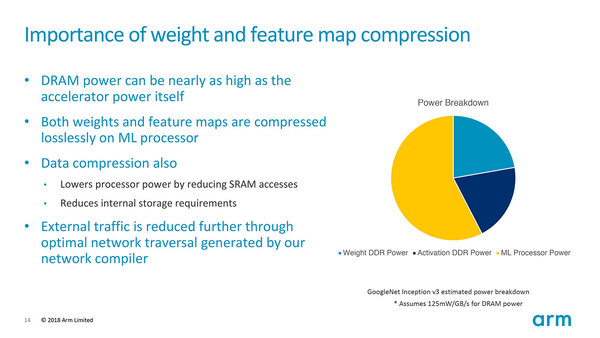
電力の約4割がデータアクセスに費やされる。同じグラフが連載601回にもあるが、細かく前提条件などが載っているこちらの方がわかりやすいだろう
機械学習における推論処理を行なうにあたって、全体の6割がプロセッサーそのもので、2割が重み(Weight)を格納するデータアクセス、残りがアクティベーションのためのアクセスに費やされているとしている。
実はAIプロセッサーの場合、相対的に演算処理の比率が高い。なにせ処理がほぼ固定されており、また演算データ量が相対的に少ない(推論では8bit幅ということも多い)ため効率が上がるという話であり、これが倍精度のFPUなどになると演算処理に費やす消費電力と同等以上をデータアクセスに費やすという報告もあったりする。
これはDRAMから遠い所に演算器があるから悪い、という話でもある。要するにDRAM Cell→DRAMチップ内のI/F→ホストへの配線→ホスト側DRAM I/F→内部バス→プロセッサーのデータキャッシュ→レジスターファイル、という遠い道のりを経てDRAMのデータをプロセサーで扱えるようになるから、それは消費電力が増えるのも無理もない。
ArmのEthosの場合は、このDRAMアクセスへの消費電力の多さ、それとレイテンシーを嫌って大容量のSRAMを突っ込んでカバーした形だ。これはCerebras SystemsのWSEなども同じで、AIプロセッサーとしては定番であるのだが、これの欠点はエリアサイズの肥大化である。
そもそもDRAMの場合、1bitの記録にはトランジスタ1個で済むのに対し、SRAMは最低でも4個(ただ4T SRAMは信頼性などの問題もあるため、通常は6つ以上のトランジスタを使う)必要になる。同じサイズの容量を確保するのに、DRAMに比べて最低4倍(実際には6倍以上)の面積を喰う格好だ。DRAMとSRAMで製造プロセスが異なる(SRAMの方が微細化できる)ことを考えても、まだ2~3倍の差は軽くある。
加えてDRAMの場合は大量生産に特化しているためコストそのものは安いが、SRAMは(特にAIプロセッサー向けの先端プロセスの場合)、結構なコストになる。容量あたりのコストを比較すると、SRAMはDRAMよりもおそらく1桁上がることになるだろう。このコスト面の不利さをどう補うか、がテクニックの見せどころになっていたわけだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ












の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



















