



アプリ開発/テストや統計分析に“使える”マスクデータを生成する「Insight Data Masking」
インサイト、高品質なデータマスク処理を実現する専用ソフト発売
2020年09月17日 07時00分更新

インサイトテクノロジーは2020年9月16日、自社開発のデータマスキング専用ソフトウェア「Insight Data Masking Ver1.0」を販売開始した。データベース(DB)領域専門のコンサルティングやソフトウェア開発を手がける立場から、従来のマスキングツールにおける「日本語対応」「データの論理的/統計的特性の維持」「処理スピード」といった課題解消を図った新製品。アプリケーション開発/テストやビッグデータ統計分析における、高品質なマスキングデータに対するニーズを見込む。
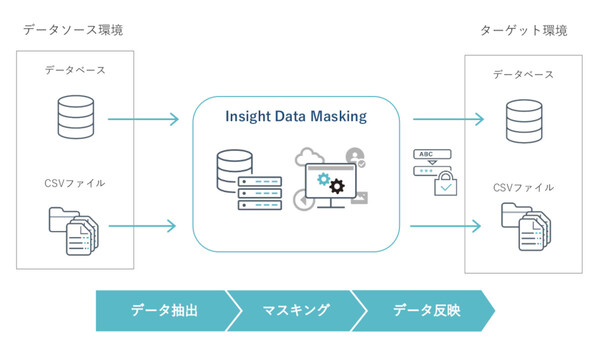
インサイトテクノロジーの新製品「Insight Data Masking」は、データマスク処理専用のソフトウェア
既存のマスキングツール/手法に対する不満から生まれた製品
Insight Data Maskingは、CSVファイルやデータベース(RDBMS)のレコードに含まれる個人情報や機微情報をマスク処理(匿名化/秘匿化、k-匿名化)するためのソフトウェア。
「この製品を開発するきっかけとなったのは、インサイトがDBコンサルティングを行っていたある顧客企業における体験だった」と、阿部氏は説明する。マスキング作業を依頼され、海外製ツールを使って処理をしたところ、処理完了までに1週間もかかってしまい、日本語データの処理にも難があったという。そこから、これまでのマスキング手法/ツールにおける課題を再考していった。
マスキングデータは、アプリケーション開発/テスト用のテストデータとしてよく利用されている。しかし、本番データからマスキングデータを生成するためには、マスキング対象のカラム選択やスクリプト作成などに工数がかかりがちだった。一方で、件数の少ないダミーデータをテストデータに使うと、件数やデータの多様性の観点で不十分なアプリケーションテストに終わってしまい、本番環境への移行後にバグが発生する原因にもなる。
また最近では、統計分析用途でのデータマスキング需要も増えているという。とくに、ビッグデータの統計処理でクラウドDWHサービス(Amazon RedshiftやSnowflakeなど)を使うケースが増えているが、オンプレミスからクラウドにデータを移す前には情報保護ルールに基づいてマスク処理が必要になる。ここでも処理工数の問題が発生するほか、マスキングによってデータ品質が劣化すれば分析結果の精度も低下してしまうことになる。
Insight Data Maskingでは、こうした従来のマスキング手法/ツールにおけるさまざまな課題の解消を図り、「DX(デジタルトランスフォーメーション)推進におけるデータのセキュリティ担保」を実現するとしている。

従来手法/ツールの課題(データ精度/パフォーマンス/対応工数/ユーザビリティ/クラウド対応)と、Insight Data Maskingによる解決策
同製品では4つのエディションをラインアップする計画で、今回はまず「Basic Edition」と「Qlik Replicate Edition」の2つがリリースされた。Basic Editionは、CSVデータに対してマスキングを行うベースエンジンを提供するもので、コマンドライン(CLI)から処理が実行でき、他社ETLツールとの連携処理も想定している。またQlik Replicate Editionは、同社が販売する米クリックテックのレプリケーションツールにアドオンし、レプリケーション処理の中にリアルタイムなマスク処理を組み込めるもの。
今後、さらにOracleなどのRDBMSと直接接続してマスキングを行うStandard Edition、大量データの並列処理機能やマスキング対象とすべきカラムをAIが推奨する機能などを備えるEnterprise Editionもリリースする予定。

Insight Data Maskingで提供される4つのエディションと機能概要
“本当に役立つ”品質の良いマスキングデータを生成する技術
製品開発に携わった同社 取締役 兼 CTOの石川雅也氏は、過去に取り扱ったことのある他社製マスキングツールは、日本語対応や処理スピードの問題のほか、「DB屋としては、出てくるマスキングデータもとても使いづらいデータだった」と振り返る。
たとえば、複数テーブル間の関係性(リレーション)を考慮せずにマスキング処理を行えば、関係性が壊れてアプリケーション開発/テストや統計分析などに“使えない”データになってしまう。また、本番データのカーディナリティ(各カラムが持つ値の種類、分布)が維持されなければ、アプリケーションのテストや性能評価が不十分なものになってしまう。こうした既存の手法/ツールに感じるさまざまな不満を、今回の製品開発に生かしているという。
Insight Data Maskingでは、マスキング機能として「テキストマスキング」「数値マスキング」「セグメントマスキング」「辞書マスキング」の4種類を備え、いずれもデータの品質要件を満たせるアルゴリズムを選択できる。さらに、データベースのID項目に対して、そのユニーク性(単一性)やテーブル間の整合性を維持した形でのマスク処理ができるので、アプリケーションテストなどに“使える”データが提供できる。
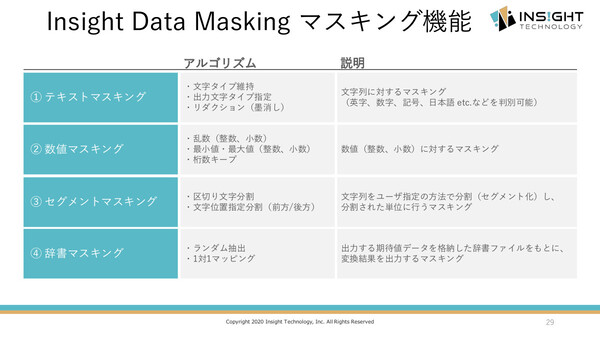
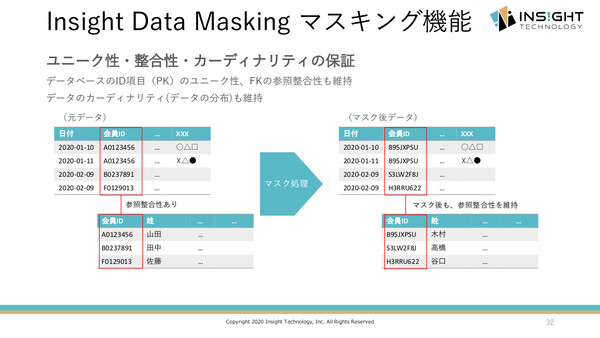
マスキング機能ではさまざまなアルゴリズムを選択でき、さらにデータのユニーク性/整合性/カーディナリティも維持する
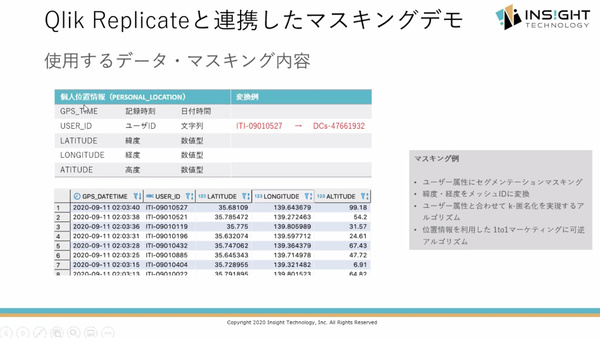
たとえばGPS位置情報を使った人流分析を行う場合、ユーザーIDをマスクするのと同時に、IDのユニーク性を保たなければならない。同製品ではこうした要件に応える(デモ画面より。掲載機能の一部は将来提供予定)
大量データの処理スピードについては、並列処理が可能なアーキテクチャとすることでマスキング高速化を実現している(並列処理機能はEnterprise Editionで提供予定)。AWS環境での性能評価では、8vCPUのインスタンスを使って秒間33万レコードのマスキング処理スピードを実現しているという。

Insight Data Maskingと他社製品の処理スピードの比較(他社製品はDB-DB間のマスキング処理のため参考値)
石川氏は今後の機能開発ロードマップとして、並列マスク処理やAIによるマスク対象カラムのリコメンド機能、k-匿名化やグルーピング、ノイズ/誤差付与、さらに可逆匿名化(暗号化)などを計画していると説明した。
「データのマスキング自体は昔からある、とても一般的な処理。そこで新製品が作れるとは思っていなかったが、顧客の話を聞くうちに『マスキングの世界はまったく進化していない、全然イノベーションが起きていない』ことに気づいた。現在の、たとえば皆が分析基盤をクラウドで構築するような時代にどんなマスキングが必要とされるのかを考えれば、この古い世界にイノベーションを起こせるのではと感じている。(製品開発は)思ったより面白かった」(石川氏)

今後の開発ロードマップ。2021年Q2以降にはSaaS提供も計画している
Insight Data Maskingは仮想アプライアンスとして、年間サブスクリプションの形で販売される。Basic Editionの販売価格は年額100万円(処理対象データ1TBまで、税抜)から。製品単体での販売に加えて、Qlik Replicateなど他のソフトウェア製品やコンサルティングサービスと組み合わせた“DataOpsソリューション”としても販売を進めていくとしている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



