



機械翻訳エンジン「Microsoft Translator」の音声翻訳が日本語対応
“方言”も訳せるMSの新翻訳エンジン、APIであらゆるシステムに追加可能
2017年04月11日 07時00分更新

米マイクロソフトは4月7日、機械翻訳エンジン「Microsoft Translator」の音声翻訳で日本語のサポートを開始した。
Microsoft Translatorは従来から日本語テキストの翻訳には対応していたが、今回、同エンジンを搭載する機械翻訳アプリやSkype翻訳で、リアルタイムの日本語音声翻訳が可能になった。日本語音声で入力した言葉を、Microsoft Translatorがすでにサポートする9言語に翻訳して、音声とテキストでアウトプットする。
同社は、日本語音声翻訳対応のMicrosoft Translatorアプリを、Windows 8.1/10、Windows Mobile 10、Android、iOS向けに提供する。Microsoft Translatorアプリに実装された一斉翻訳サービス「ライブ機能」を使うと、それぞれ異なる言語を話す複数人で一斉にリアルタイム音声翻訳による対話が可能だ。例えば、日本語、英語、フランス語を話す3人がMicrosoft Translatorアプリを導入した端末を持ち寄れば、すべての会話が各人の指定した言語に翻訳される。
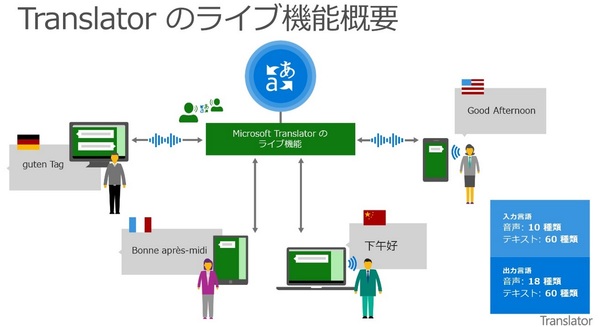
Microsoft Translatorアプリのライブ機能
ライブ機能は、PowerPointに音声翻訳機能を付加する「Microsoft Translator PowerPointアドイン」でも提供。このPowerPointアドインを使うと、PowerPointから直接ライブ機能を起動し、リアルタイムでプレゼンテーションに翻訳字幕を付けることができる。
そのほか、「Skype for Windows」と「Skype Preview for Windows 10」で提供しているSkype翻訳や、Outlookのメール文面を翻訳するアドインでも、日本語音声翻訳対応の新しいエンジンを提供する。「今後、すべてのマイクロソフト製品にこの新しい機械翻訳エンジンを実装していく計画だ」と日本マイクロソフト 執行役員 最高技術責任者(CTO)の榊原彰氏は説明した。
さらに、同エンジンはAzureのCognitive Services APIとしても提供され、あらゆるWebサイトや業務アプリに日本語の音声翻訳機能を追加できるようになっている。

日本マイクロソフト 執行役員 最高技術責任者(CTO)の榊原彰氏(左)、米マイクロソフト AI&リサーチグループディレクター(機械翻訳プロダクト戦略担当)のオリヴィエ・ファンタナ氏(右)
ニューラルネットワークモデルで2つのAIの精度を向上
7日に提供が開始された日本語音声翻訳対応のMicrosoft Translatorだが、新エンジンを搭載した翻訳アプリをさっそく試したユーザーの間で「日本語の“方言”も認識して翻訳する」ことなどが話題になっている。日本語音声の認識率、機械翻訳の精度向上は、「ニューラルネットワーク」と呼ばれる深層学習モデルの適用によるものだ。
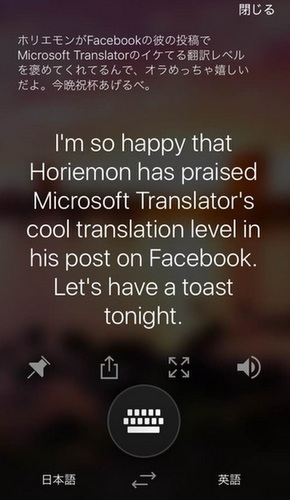
Microsoft Translatorアプリは、榊原CTOが発音した方言も認識して英訳している
マイクロソフトの機械翻訳エンジンでは、これまで「統計的手法による機械翻訳(SMT)」を使っていた。同社 AI&リサーチグループディレクター(機械翻訳プロダクト戦略担当)のオリヴィエ・ファンタナ氏の説明によれば、SMTは「人により翻訳されたデータを活用し、元言語の単語の並び順などのマッチングによって翻訳する」もの。一方、新しい機械翻訳エンジンが採用しているニューラルネットワークモデルでは、「文章全体の文脈を把握して翻訳するため、より精度が高くなる」(ファンタナ氏)。
音声翻訳は、「機械翻訳」と「音声認識」の2つのAIを組み合わせて実現されるシステムだ。Microsoft Translatorでは、音声認識AIの方もニューラルネットワークモデルを採用して精度を高めている。マイクロソフトの研究チームが2016年10月に発表したデータによれば、ニューラルネットワークを採用した同社の深層学習プラットフォーム「Microsoft Cognitive Toolkit」において、音声認識AIの単語誤認識率は5.9%まで精度向上した。人間の誤認識率は4%と言われており、人間に近い精度を達成している。
とはいえ、「Microsoft Translatorの機械翻訳は人間の通訳を置き換えられるほどの性能ではない。また人間の通訳を置き換えることを目的に開発しているわけでもない」と榊原CTO。人間の翻訳の生産性向上のほか、人間による翻訳にコストがかかるケースや翻訳スピードが最も優先されるケースなどでの利用を想定しているという。
「学校内で子供の声を録音しない機能」などプライバシーに配慮
Microsoft Translatorが認識した音声データは、まず、Azure上の「音声認識ニューラルネットワークシステム」へ送られ、テキスト化される。この最初のテキストデータは、日本語の「えーと」や英語の「um」など人が話すときに無意識に発音しているつなぎ言葉(自然言語の専門家が「ディスフルエンシ」と呼ぶもの)を含んでいる。
マイクロソフトは独自技術によりこのディスフルエンシを削除し、完全な文章に必要な大文字化や句読点の追加を行った翻訳しやすいテキスト「TrueText」を作成。次のステップで、TrueTextを機械翻訳システムへ送って翻訳し、最後のステップでテキスト読み上げ機能によってテキストを音声に変換している。
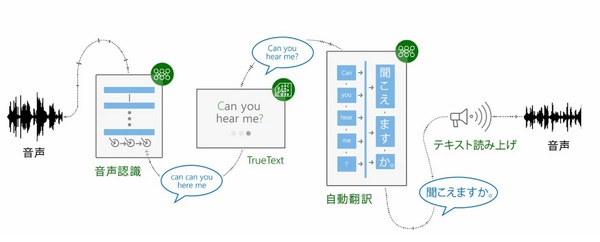
Microsoft Translatorは「音声認識AI」と「機械翻訳AI」の2つで構成されている
このようにMicrosoft Translatorでは、ユーザーが音声やテキストで入力したデータをいったんAzureへ送信し、Azureで処理をした結果をユーザーに返している。入力したデータは、音声認識や機械翻訳の精度向上のためのトレーニングデータにも活用されるが、このデータプライバシーについてファンタナ氏は、「ユーザーが入力したデータは、マイクロソフトデータセンター内の特別な隔離スペースで安全に管理されている」と説明した。
「ユーザーが入力したデータがそのままAIに反映されるわけではない。入力データに対して、マイクロソフト側で正解データを与えることでAIが学習する。また、反社会的な内容や差別的な内容はフィルタリングする」(ファンタナ氏)。
また、法人向けOffice 365などの業務システムや教育機関で扱うデータについては、ユーザー側がデータの取り扱いをコントロールできるようになっているという。「米国では学校の教室で生徒の声を録音することが禁止されている。、Microsoft Translatorには、あらかじめ教育機関での利用時に、子供の声を録音しない機能が搭載されている」(ファンタナ氏)。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



