




最近、HPC業界にも片足を軽く突っ込んでいる知人に「最近の連載、HPC黒歴史化してていいねぇ」と言われて、そう言われみると確かに、と思った。
連載271回の最後で「スーパーコンピューターの世界は、一歩間違うと黒歴史連載になりかねないのだが、今回はそうした趣旨ではない」と書いておきながらこの体たらくかと反省したりもしている。
しかし、HPCの歴史は失敗や敗退したメーカーとその機種の歴史とほぼ等しいだけに、なかなか黒歴史化させないのが難しい。というわけで今回もまたもやそんな製品である。ただしその理由はなかなか斬新である。

KSR-1
メモリーを持たない超並列マシン
KSR-1
1986年、米マサチューセッツ州でKSR(Kendall Square Research)という会社が設立された。Kendall Squareというのは会社がある地名()であり、ボストン市街から川を隔ててすぐのところ、有名なマサチューセッツ工科大学の非常に近くである。
もっともKendall Squareのオフィスは手狭だったためか、1990年になる前に、もう少しボストンから離れたWalthamという場所に移動したが、社名はKSRのままとされた。
創始者はSteven Frank氏とHenry Burkhardt III氏の2人で、このBurkhardt氏はもともとDECでPDP-8の設計に携わり、その後Data GeneralやEncore Computerの設立にも関わった人物である。
さて、そのKSRが1991年に発表した最初のマシンがKSR-1である。最大1088プロセッサー構成で実現されるもので、分類としては超並列マシンにあたると思われる。
まずはシステムの構成だが、Photo01がそのラフな構図である。すべてのプロセッサーノード(図中のP)は、サブキャッシュと呼ばれる256KBの命令/データキャッシュ(1次キャッシュ相当)と、32MBのローカルキャッシュ(2次キャッシュ相当)を持つ。
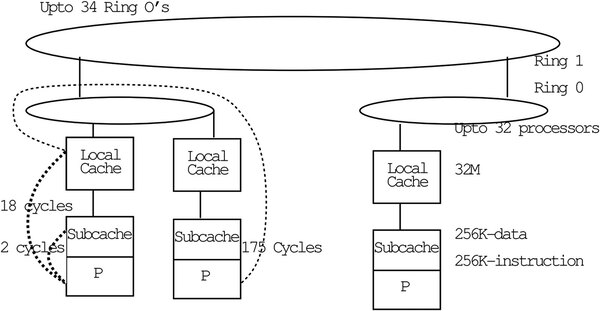
ジョージア工科大のUmakishore Ramachandran氏の“Scalability Study of the KSR-1”という論文より抜粋。この論文のAbstractにある結論を読む限り、やはりALLCACHEアーキテクチャー(後述)は無茶だったという気がする
このノードが32個、1つのリングバス(Ring 0)にぶら下る。この外側に、さらに大きいリングバス(Ring 1)がある形だ。Ring 1にはRing 0を最大34個ぶら下げ可能で、Ring 0にはそれぞれ最大32プロセッサーノードを接続できるので、最大ノード数が32×34=1088となる計算だ。ちなみにKSRではこのプロセッサーノードをCellと称している。
このシステムがユニークなのは、メモリーを持たないことだ。同社はこれを“ALLCACHE”アーキテクチャーと称している。
システム全体で仮想アドレスは共有しており(これをSVA:System Virtual Addressと呼ぶ)、それと個々のCellが持つアドレス(CA:Context Address)を、STT(Segment Translation Table)で変換する仕組みが用意されているが、肝心のメモリーそのものは「ない」という代物である。
メモリーがないのにどうやって動かすかというと、それぞれのCellは、アドレスを指定して書き込み、あるいは読み込みをする場合、その実体はサブキャッシュないしローカルキャッシュに対して実行される。
「最初にどうやってキャッシュに値を埋めるのか」という根本的な問題はあるにせよ、確かにキャッシュが溢れるような使い方をしない限り、以後そのCellは自身のサブキャッシュないしローカルキャッシュだけを相手にしていればプログラムが動作する。
問題は、他のCellに接続されたキャッシュにアクセスする場合だが、結論から言えば直接キャッシュにアクセスすることはできない。それができたらメモリーである。
したがって、他のCellに接続されたキャッシュにアクセスする場合は、ノード間通信という形で、そのCellにリクエストを出し結果を受け取ることになる。
アドレス空間はすべてのノードで決まるが、メモリーそのものは共有しておらず、ただしキャッシュコヒーレンシが保たれる(嘘ではない)ということで、この方式をCC-NUMA(Cache Coherency Non Unified Memory Architecture)と分類されることもある。
「ヘネシー&パターソン コンピュータ アーキテクチャ 定量的アプローチ」(通称:ヘネパタ本)の著者であり、MIPSの創始者、現在はスタンフォード大学の学長であるJohn L. Hennessy博士は、自身の“An Empirical Comparison of the Kendall Square Research KSR-1 and Stanford DASH Multiprocessors”という論文の中で、KSR-1はCOMA(Cache Only Memory Architecture)と分類している(ちなみにStanford DASHはHennessy博士が開発していたCC-NUMAのマシンである)。
なぜこういうアーキテクチャーを考えついたのかはよくわからない。ただ1990年頃は、キャッシュを大量に搭載するという力技が一瞬流行ったことがある。
筆者の記憶では(ベンダーがどこかは思い出せないのだが)MIPSのR3000に16MBの2次キャッシュを組み合わせ、「RTOSがまるごとキャッシュに載るのでリアルタイム処理でも利用できる」という謎のプロセッサーが発表になったこともあった。
実際、ローカルキャッシュの実体そのものはメモリーと大差なく、Tag RAMが搭載されるメモリーをローカルキャッシュと呼んでるような構成だったため、実装そのものはそう難易度は高くなかっただろう。
→次のページヘ続く (1キャビネット以内の構成では性能を発揮)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























