




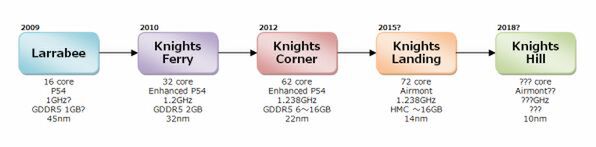
MICアーキテクチャーのロードマップ
Xeonブランドで登場した
Knights Corner
こうした準備期間を経て、2012年にインテルはKnights Cornerベースの製品をXeon Phiとして発売する。
実は2011年のISCの会場で、インテルは単にKnights Ferryの性能をアピールするだけではなく、Knights Cornerのチップのデモや、DGEMM(倍精度の行列演算)で1TFLOPSを超える性能があることをアピールしていた。ただこの時はまだ製品発表には至っていない。
ISCの会場でKnights Cornerを示すRajeeb Hazra氏(General Manager, Intel Technical Computing Group)。画像出典はインテル
製品が発表されたのは2012年6月のことで、この時にはISC 12にあわせてXeon Phiという新しい製品ブランドを発表した。

Xeon Phi発表当時のスライド。ここで初めてMICアーキテクチャーベースの製品がXeonブランドに属することが明かされた
内部の詳細については、同じく2012年8月に開催されたHotChips 24で明らかにされている。といっても、この時点ではまだコア数は50以上というだけで厳密なコア数は示されなかった。
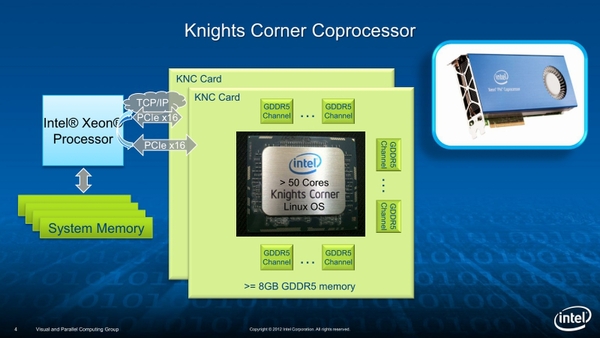
HotChips 24で公開されたXeon Phiの情報。この当時はPCI-Express x16の上でTCP/IPを通すことを考えていたのだろうか?
ただ同時に発表されたKnights Cornerのダイ写真から、最大62コアであることは推察がついた。

Knights Cornerのダイ写真。上3列は1列あたり16コアだが、最下列は14コアとなっており、合計62コアと考えられる
内部構造は相変わらずリングバスを使って相互接続する方式で、コアの内部構造は(プロセス微細化以外は)Knights Ferryと同じこと、Vector ALUは引き続き16-wideの構造になっていることが示されている。
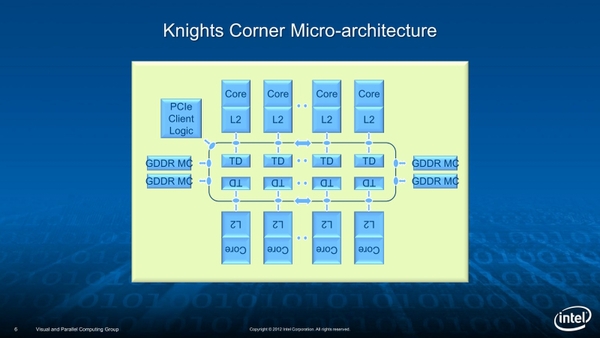
Knights Cornerの内部構造。リングの中にあるTDは、それぞれの2次キャッシュ用のタグ・ディレクトリーである
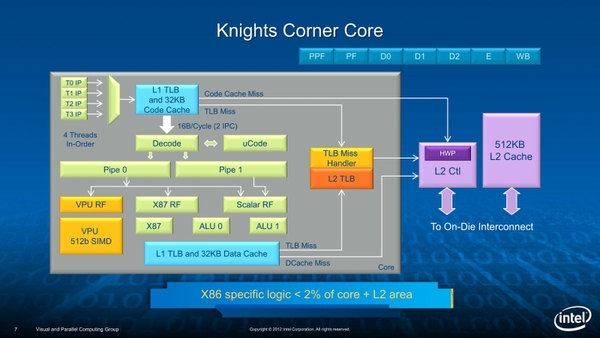
Knights Cornerのコアの内部構造は、Knights Ferryをもう少し細かく示したかたちだ
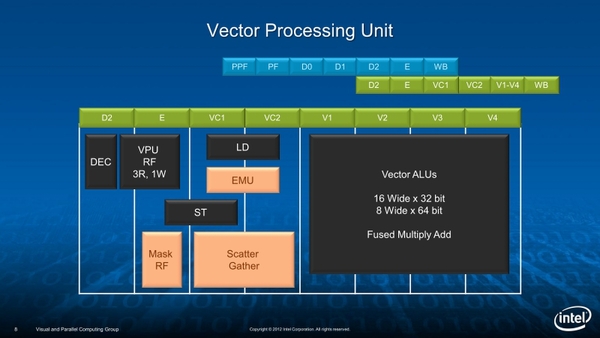
Vector Unitの構造。パイプライン段数はALUだと7段なのが、Vectorでは13段になる
おもしろいのが下の画像で、これは2012年6月のTOP500のリストから、3社のアクセラレーターを使った場合の性能/消費電力比のトップを並べたものである。
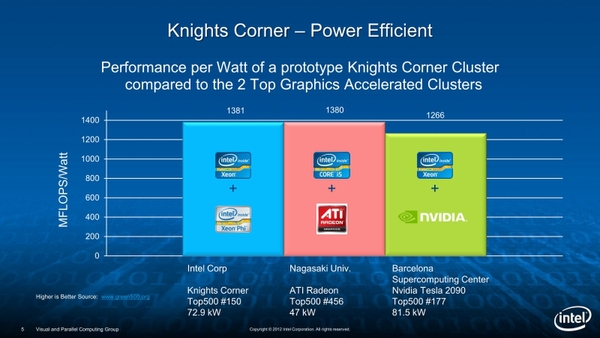
Knights Cornerの価格性能比。もっとも数字だけ見ると「より高い」というよりも「DEGIMAクラスターと同等の」というべきかもしれない
ここでインテルが社内に構築したDiscoveryというシステムは118.6TFLOPSを100.80KWで実現しており、バルセロナ・スーパーコンピューター・センターが構築したBULLX B505ベースのシステムの103.2TFLOPS/81.50KWや、長崎大学のDEGIMA クラスターの64.8TFLOPS/47.05KWと比べても、より高い性能/消費電力比が得られると主張していることだ。
単に性能/消費電力だけでなく、勢力的にも無視できない規模になった。2012年6月のTOP500リストの中には44システムがXeon Phiベースとしてランクインしている。
ただまだこの時点ではXeon Phiの生産がそれほど十分ではなかったのだろう。どのサイトも限られた数のXeon Phiしか搭載しておらず、最高性能を出したシステムは上に出てきたインテルのDiscoveryの150位となっているのは、仕方ないところであろう。
なお、この時点ではまだ公式な意味での出荷は開始されていない。したがってインテルを含む44のシステムは、いずれも正式出荷前の製品をベースにシステムを構築した形だ。正式出荷が始まったのは2012年末のことで、まずはXeon Phi 5110Pが出荷される。

Xeon Phi 5110P
この製品は60コア構成で、動作周波数は1.053GHz、メモリー8GBというもの。コアそのものは全部で62個あるが、うち2つは冗長化した(無効化した)形での出荷となっている。
今もってインテルはKnights Cornerのダイサイズを発表していないのだが、世の中には製品版のXeon Phiを買ってヒートスプレッダーを引っぺがした猛者の方がおられ(関連リンク)、この方の実測によれば720mm2に達するとしている。
これだけ大きければ欠陥が多少生じるのは止むを得ないところで、欠陥がある部位を無効化して出荷することを前提に、多めにコアを用意したと考えれば理解はしやすい。
これに引き続き2013年には57コアとし、その分動作周波数を1.1GHzに引き上げてバランスを取ったXeon Phi 3100シリーズと、本当にハイエンド、要するにTOP500での上位ランキング狙い向けに有効コア数を61とし、さらに動作周波数を1.238GHzまで引き上げたXeon Phi 7100シリーズもラインナップする。

Xeon Phi 3100
ちなみに搭載メモリー量も、Xeon Phi 3100シリーズは6GB、5100シリーズは8GB、7100シリーズは16GBと差がついており、このあたりでラインナップ分けがされている。
2012年11月のTOP500のリストでは、テキサス大のアドバンスド・コンピューティング・センターに納入されたStampedeというシステムが実効性能2.66TFLOPSで7位にランクインしている。
このシステムは当初Xeon Phi 5110Pをベースに構築されていたが、後にXeon Phi 7120Pに入れ替えと増設を行ない、実効性能5.17TFLOPSで2015年6月のリストでも8位にランクインしているシステムだ。
余談だが、テキサス大はこのシステム更新を2012年から2013年にかけて行なったのだが、当時まだインテルは7100シリーズを発表していなかった。このため、このカードはXeon Phi SE10Pという“Special Edition”扱いされている。
また、2013年11月のTOP500では、中国の国防科学技術大学(NUDT)に設置されたTianhe-2(天河二号)は実効性能33.86TFLOPSでTOP500の1位を獲得、以後ずーっと1位の座を占め続けている。このシステムは32000個のIvuBridge-EPベースXeonと、48000枚のXeon Phiカードから構成されている。
2013年11月のリストでは、上位100位のうち9システムがXeon Phiをベースとしており、2014年6月はこれが10システム、2014年11月は11システム、2015年6月は12システムと、ゆっくりと勢力を増やしているのがわかる。
これはあくまで上位100位のシステムの話だから、もっと下位まで調べると変動はもう少し大きくなる。こうした形で、インテルは現在のHPC市場にがっちり食い込むことに成功した、として良いだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































