




今回のスーパーコンピューターの系譜は前回に続きインテルのアクセラレーターについてである。インテルはLarrabeeの後継をHPC向け製品として提供することを決断、そこから猛然と動き始める。
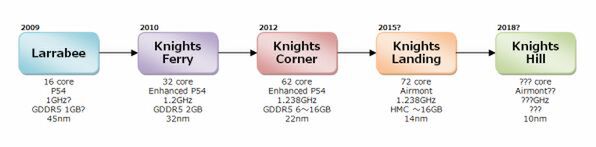
MICアーキテクチャーのロードマップ
HPC向けアクセラレーターに特化した
Knights Ferry
まず2010年に投入されたのが、Knights Ferryである。LarrabeeはまだGPU的な要素を残していたが、Knights FerryではテクスチャーエンジンやラスタライザーなどのGPU的な機能を完全に取り去り、純粋にHPC向けアクセラレーターにした。
この時点でインテルはこれをMIC(Many Integrated Core)アーキテクチャーと呼ぶようになる。
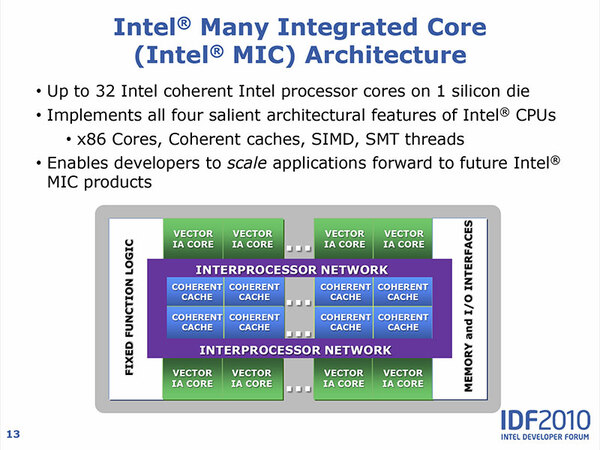
MICアーキテクチャーの概要。基本的な構造はほぼLarrabeeと同じである。IDF 2010における“Architecture Support for HPC Applications”というテクニカルセッションの資料より
これに基づく最初のボードがKnights Ferryであるが、実はインテルは結構なコストをかけてKnights Ferryを開発したものの、製品として販売していない。その代わりにKnights Ferryを将来のMICアーキテクチャーに基づく製品を利用してくれそうなユーザーに配った。

Knights Ferry。このカードの写真は実際のKnights Ferryのものではないと思われる。Larrabeeをベースにした試作カードであろう。というのは、どうみてもバックパネルにディスプレー出力(おそらくDVI)が見えているからだ。しかも外観も異なる
Knights Ferryは最大32コア、同時128スレッドの実行が可能というもので、動作周波数は最大1.2GHzほど。
各々のコアはLarrabeeと同じ16-WideのSIMDエンジンを搭載しており、ピーク性能は614GFLOPSほどになる計算だが、この前年の2009年にNVIDIAはGF100ベースのC2050/C2070をリリースしており、こちらはFloatなら1.3TFLOPSを実現しているので、だいぶ見劣りする。
実際、Larrabeeよりは多少マシではあるものの、厳然たる性能差が存在した。また、この時点ではMICアーキテクチャーを採用したチップが他になく、開発ツールを用意しても、これを使うためのプラットフォームがない状態だった。
CUDAだとG80以降のビデオカードを購入すればそこで実装できるし、AMDのBrook+ではFire Streamが販売されていた。ところがMICに関してはこれがない。一応命令セットこそx86ながら、独自実装された16-wideのSIMDエンジンは他のx86プロセッサーには搭載されていないからだ。
そこでMICアーキテクチャーベースの製品発売に先立って、Knights Ferryを見込み客に配布した形だ。余談ながら、Knights Ferryというのはコアのコード名ではなくカードのコード名であり、コアのコード名はAuburn Isleとなっているが、これは以前Larrabee 2として開発されていたものである。
さて、内部構造であるが、各々のコアの内部を簡単にまとめたのが下の画像だ。コアの左半分は限りなくP54コアに近い。ただし、オリジナルのP54コアはシングルスレッドであり、一方MICでは4スレッドなので、これに対応する形で一部のレジスター類やレジスターファイルなどを4スレッド分用意するといった拡張がされていると思われる。
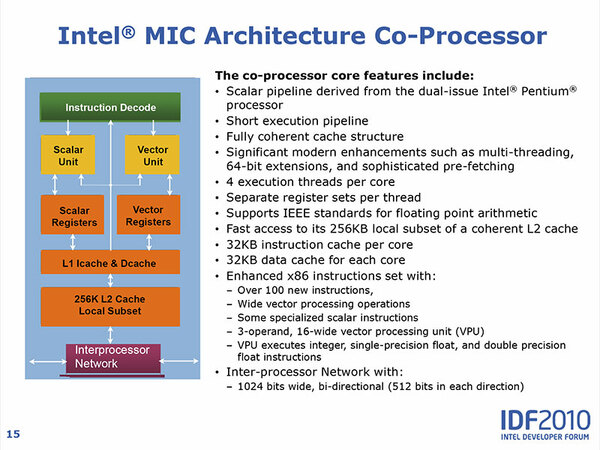
各コアの内部構造。Larrabee自身が4スレッド/コア構造だったかどうかははっきりしない
逆に右半分はLarrabeeで拡張された部分である。連載25回でLRBni(Larrabee New Instructions)の話に少し触れたが、基本的にはこのLRBniをほぼそのまま利用していると思われる。
これも余談だが、LRBniという名前は2009年頃から言われていたものの、肝心のLarrabeeがボツになったためか、公式にはLRBni(あるいはLNI)という用語は使われておらず、上の画像でも“Enhanced x86 instructions set”という表現になっている。
Knighs Ferryの発売時点で、次にKnights Cornerという製品が投入されることが明らかにされている。
このあたりはプロセスを自身で持っている強みで、45nm→32nm→22nmと世代毎にトランジスタ数を倍増できるため、最初はコア数が少なくてもプロセス微細化で簡単に性能を倍増できることになる。
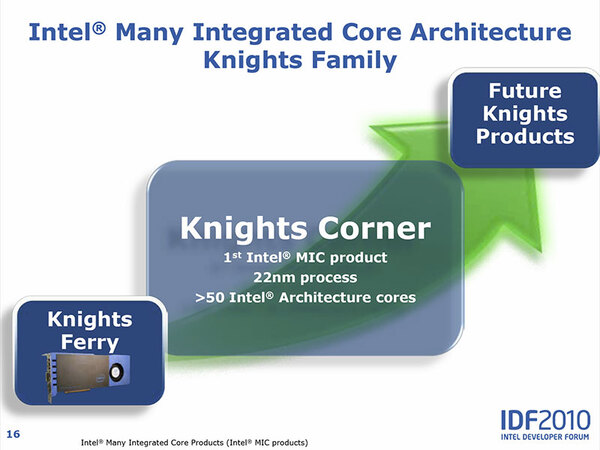
Knights Ferryはあくまでも開発用ボードという位置づけなので、続くKnights Cornerが最初のMICアーキテクチャーに基づく製品となる
2011年のISC 11(International Supercomputing Conference)にあわせ、インテルはKnights Ferryの製品写真やダイ写真を含む情報を公開した。

Knights Ferryの製品写真。バックパネルの開口部が発熱の大きさを物語る。消費電力はおおむね300W

ダイサイズなどは公開されていないが、一説によれば700平方mm近いとのこと。45nmプロセスでLarrabeeの2倍の構成なので、そのくらいあっても不思議ではない
ここで、すでにそれなりの性能が実現できることをアピールした。LU分解(行列式を解く方式の1つ)にXeonとKinghts Ferryを組み合わせて772GFLOPS、同じくXeonとKinghts Ferryを組み合わせたSGEMM(単精度の行列演算)で1TLOPS以上、Knights Ferryを8枚組み合わせたSGEMMで7.4TFLOPSの性能を出したとしている。

ISC 11で、Knights Ferryは性能が実現できることをアピールした
→次のページヘ続く (Xeonブランドで登場したKnights Corner)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































