





NVIDIAの次世代GPU「PASCAL」の実物が公開された
NVIDIAは、3月25日からGPU Technology Conference(GTC)を開催した。初日の基調講演には、創業者でCEO兼社長のジェンセン・ファン氏が行なった。

基調講演を行なったNVIDIA創業者でCEO兼社長のジェンセン・ファン氏
GPUのボトルネックはCPUーGPU間
新たな技術で接続する
ジェンセン氏は、最初にGPUのボトルネックについて話を始める。引用されたのはGPUを用いたスパコン「TSUBAME」で知られる東工大・青木尊之教授の論文だ。ボトルネックはCPUとGPUの接続にあったのだ。それぞれに高速でアクセスできるメモリがあるものの、GPUによる汎用演算では、GPU-CPU間でデータを交換する必要があり、そこがボトルネックになっていたのだという。
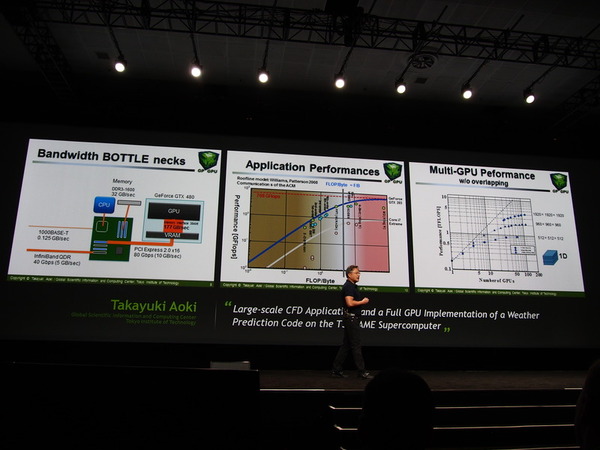
東工大の青木尊之教授がTSUBAMEの動作を詳細に調べたところ、ボトルネックは、CPUとGPUを結ぶPCI Expressであり、その次にメモリアクセス帯域がボトルネックになるという
それに対するNVIDIAの解答がCPUとGPUを直接接続するNVLINKだ。NVLINKは差動回路、埋め込みクロックを使う高速なシリアル接続技術で、最大でPCI Expressの12倍の転送速度があるという。プログラミングモデルとしてはPCI Expressと同じ(つまりほとんどPCIと同じ)であり、OSなどへの対応も容易になるという。

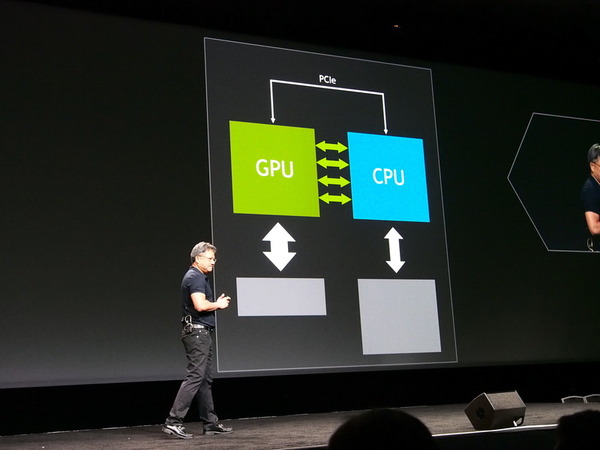
NVLINKは、CPUと直接接続しメモリ内容などを転送し、高速なユニファイドメモリを実現する。現在CUDA6に実装されているユニファイドメモリは、必要なメモリページをCPUとGPU間でコピーすることで実現している
このNVLINKを使うことで、CPUとGPUのメモリを統一して扱う「ユニファイド」メモリが可能となるのだが、第一世代のNVLINKには、キャッシュの一貫性を保つためのプロトコルは含まれず、第二世代での実装になる予定だ。CPUから直接NVLINKを出力することになるため、現時点では、専用のPowerPCプロセッサだけが対応するという。
このNVLINKを使う、MAXWELLの次のGPUアーキテクチャが「PASCAL」だ。PASCALは、GPUーCPU間をNVLINKで接続し、基板上に3次元メモリを搭載したモジュールとして提供される。当初は、TESLAのような科学技術演算などに利用する高性能システム用として使われると思われる。ただし、現時点では、PASCALの内部アーキテクチャに関してはなにも公開されておらず、どのような構成になっているのかは不明だ。一方で性能としては、現在のMAXWELLの1.7倍弱程度だとされている。


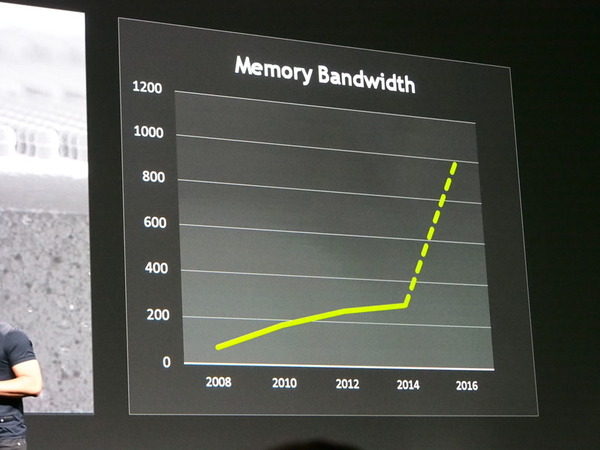
メモリを垂直に重ね、間を縦に接続する3Dメモリを採用することで、メモリ転送帯域を拡大し、メモリアクセス速度によるボトルネックを解消する

単精度浮動小数点の演算による従来GPUアーキテクチャとの比較。MAXWELLに比べて1.6倍以上の性能向上を実現する
次期ハイエンドカード「TITAN Z」を公開
次に発表されたのは、2999ドルのグラフィックスカード「GeFORCE GTX TITAN Z」だ。GK110をデュアルで搭載し、演算コア数は5760個、8テラFLOPSで12ギガバイトのメモリを搭載する。これは、画像認識処理のような汎用演算用やプロフェッショナル向けのグラフィックスでの利用を想定している。

2999ドルのプロフェッショナル用途向けGPUボード「GeFORCE GTX TITAN Z」

TITAN Zによる水面のグラフィックスのデモ

物体に対して空気の流れをシミュレーションするデモアプリケーション。リアルタイムに物体の向きや位置を変更できる

Unreal Engineを使ったデモ動画
さらにレイトレーシングなどにより高度なリアリティを持ったグラフィックスを作成するための「レンダリングアプライアンス」としてIRAY VCAも発表された。これは、Kepler GPUを搭載したモジュールを内部に追加することで性能をスケーリングできる製品。デモでは、実際に撮影した写真と、建築データなどから生成したグラフィックスが提示されたが、簡単には見分けが付かないレベル。両方を並べて、どっちが本物なのかと聞かれると見分けることも不可能ではないとおもうが、グラフィックスのほうだけを見せられたら普通の写真と区別がつかないだろう。


レンダリング専用機IRAY VAC。GPUごとに12ギガバイトのメモリを搭載し、KeplerアーキテクチャのGPUを利用、CUDAコアは最大23040個
この製品は、製品デザインなどにも利用可能で、別のデモでは本田技研の自動車設計のデータをレンダリングしたものが使われた。一見、写真のような画像だが、設計データからのものであるため、たとえばカットモデルのように半分に切った状態にすることもできる。システム価格としては5万ドルである。


左側の画像は、設計データを元にレンダリングを行なった画像。右は実際に建物の中で撮った写真
さらに、NVIDIAのGPU仮想化技術について、VMWare社がこれにHorizon DaaS Plaformで対応することが発表された。Horizon DaaS(Desktop As A Service)は、vCloudサービスの上に構築された仮想デスクトップサービス。簡単にいうと、ネットワークを介して、コンピュータの実行環境(デスクトップ環境)を提供するもの。GPUを利用したアプリケーションをクラウド側で動作させるためにGPU仮想化技術に対応したとのことだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































