



「NetApp Insight Xtra Tokyo」基調講演でデータ基盤戦略を語る
「データをナレッジに変える」AI時代の新しいデータ基盤へ ―NetAppクリアンCEO
2026年02月13日 07時00分更新

NetAppは2026年1月29日、都内でイベント「NetApp INSIGHT Xtra Tokyo」を開催した。基調講演に登壇したNetAppのCEO、ジョージ・クリアン氏は、AI時代における企業のデータ活用と、同社が推進する「インテリジェント・データ・インフラストラクチャ」の全体像について語った。

NetApp CEOのジョージ・クリアン(George Kurian)氏
基調講演冒頭、クリアン氏は「NetAppでは、データがナレッジ(知識)の基盤であることを長年にわたり理解してきた」と切り出し、同社の34年の歴史を振り返った。
NetAppの歩みは、ナレッジワーカーが情報を共有できる「ネットワークファイルシステム」の開発から始まった。その後、複数種類のデータを単一の統合ストレージに集約する技術(ユニファイドストレージ)、データセンターの境界を越えるハイブリッドクラウド・データファブリックへと進化した。その間、セキュリティ、ガバナンス、AI Opsといった機能も次々と追加してきた。これらの中核を担うのが、同社のデータ管理OS「NetAoo ONTAP」である。
「これらの取り組みにより、ONTAPは世界で最も信頼され、最も広く導入され、最もインテリジェントなデータインフラストラクチャに進化した」とクリアン氏は語る。
同社の顧客事例として、ローレンス・リバモア国立研究所の核融合点火実験、ドリームワークスのアカデミー賞受賞作「シュレック」の制作、欧州宇宙機関(ESA)による10億個の星のマッピングなどを紹介しながら、クリアン氏は「膨大なデータを短時間で処理し、失敗が許されない局面でNetAppが選ばれている」と胸を張る。中でも、ESAの担当者はメッセージビデオで「20年間、一度もファイルを失ったことがない」とコメントした。「最も重要な瞬間に、最大の課題に応え続けることで信頼を構築してきた」とクリアン氏は述べた。
“AI時代”に適したストレージ、データ管理基盤はどうあるべきか?
“AI時代”を迎えた現在、データの重要性はさらに高まっている。クリアン氏が紹介した大手コンサルティング会社の予測によると、AIによって世界で年間8兆ドル、世界のGDPの約8%相当の生産性向上が実現するという。クリアン氏は「AIはデータの上に構築される」「AIの時代は、同時にデータの時代でもある」と強調する。
ただし、AIが活用できるようにデータを準備し、管理していくことは、多くの組織にとって課題になっている。企業の生データをAI対応データへと変換するには、「データパイプライン」と呼ばれるプロセスが必要となる。具体的には、データの整理・分類、ガバナンスとアクセス制御の実装、文脈や意味を付与する「アクティブメタデータ」の生成、そして大規模言語モデルが解釈可能な形に変換する「ベクトル化(エンベディング)」という、一連のデータ処理の流れだ。
従来、企業はすべてのデータを中央の一カ所にコピーし、集約するアプローチを取ってきた。しかし、クリアン氏はこの方法の限界を指摘する。「これらのステップを一つのデータセットで完了したら、データが変更されるたびに、あるいはモデルを更新する必要があるたびに、繰り返さなければならない」からだ。
クリアン氏によると、この中央集約型モデルは、対象となるデータが比較的小規模で、構造化されている場合には機能する。つまり、データウェアハウスやデータベース、旧来の基幹システムなどが出力するデータには有効だ。しかし「それは企業が保有するデータの15%に過ぎない」と、クリアン氏は指摘する。残りの85%を占める非構造化データに対しては機能しないのだ。
そこで、NetAppは新しいデータ管理のビジョン「Intelligent Data Infrastructure(インテリジェント・データ・インフラストラクチャ)」を提唱している。
インテリジェント・データ・インフラストラクチャの中核をなすのは、データの種類に応じた最適な処理を実行できるアーキテクチャだ。従来型のファイル/ブロック/オブジェクトデータに対する処理、構造化/非構造化/半構造化データを共通言語で統合するメタデータ処理、さらには生成AIやAIエージェントが扱うベクトルデータ、トークン化データの検索処理――、これらすべてを一つの基盤で支える。
これにより、インテリジェント・データ・インフラストラクチャは「企業データをナレッジに変換することができる」とクリアン氏は強調する。
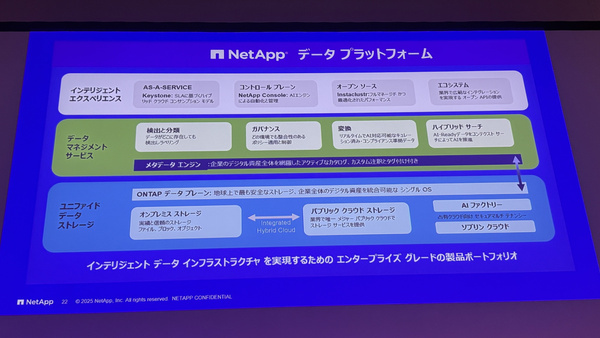
NetAppのインテリジェント・データ・インフラストラクチャ
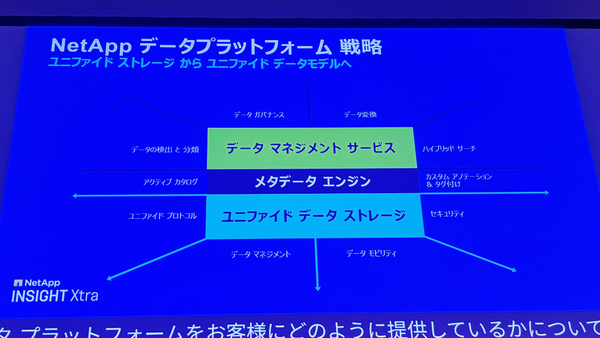
旧来のストレージレイヤーだけでなく、データ変換なども含むデータマネジメントレイヤー(後述するAI Data Engine)まで統合している点が特徴だ



