



ロードマップでわかる!当世プロセッサー事情 第861回
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説
2026年02月02日 12時00分更新

設計の最適化により最小電圧を低減
これが性能向上につながる
少し不思議なのは次の画像だ。報道によれば、Snapdragon X EliteはTSMC N4、Snapdragon X2 EliteはTSMC N3での製造になっているのだが、こちらでは5nmと4nmの性能比較になっている。
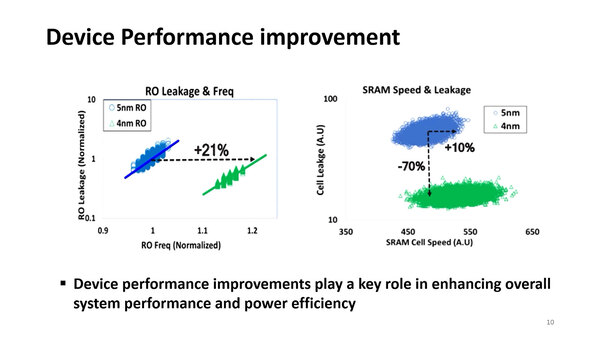
ROはRing Oscillatorの略。ロジック回路の基本的な動作を測定するには妥当な選択だが、さすがに同じリーク電流で21%の高速化がTSMC N5→N4で実現するとは考えにくい
なのだが、TSMC N4は基本TSMC N5をベースに若干の改良(セルライブラリーの高密度化やジオメトリーの手直し)を図った程度で基本そこまで性能が変わらない。ところがロジック回路で最大21%の性能改善、SRAMで10%の性能向上と70%のリーク削減というのは明らかにおかしく、これは5nmと4nmの比較ではなく、4nmと3nmの比較なように思われる。
表現はともかくとして、プロセスの微細化で性能は上がっているわけだが、実はここも細かい話がいくつか不明である。TSMCの場合、N3世代でFinFlexと呼ばれる技術を導入した。これは省電力/高密度と高性能のバランスを取るために、NMOSとCMOSのフィンの数を変更するもので、2-1/2-2/3-2という3種類の構成が用意されているが、今回Qualcommはこの2-1を利用して省電力に思いっきり振ったのかもしれない。
ただCPUに関してはむしろピークの動作周波数が引きあがっているあたりは、CPUはクリティカルパスには3-2のような高性能向けの構成を使うが、NPUは2-1のような高密度/高効率構成を選んだ、という可能性もある。上の画像は2-1構成の場合、と考えると納得はできる。
その構成に関するヒントが下の画像である。FinFlexで言えば、HD cellというのが2-1、HP cellというのが3-2、Multi-WNSというのがおそらく2-2構成である。で、Snapdragon X2 Eliteではこの3種類を組み合わせたハイブリッド・ライブラリーを利用するとしており、これでなるべく性能/消費電力比を高めようとしている。
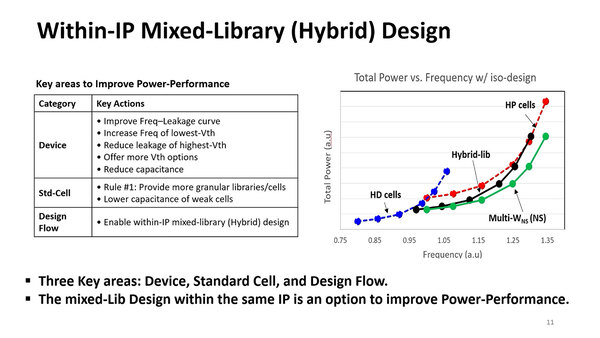
基本はMulti-W、つまり2-2構成であり、一部2-1と3-2を混ぜているという感じである。上の画像の説明ではNPUは2-1が主体か? と書いたが、実際は2-2が主体なのかもしれない。2-1は動作周波数があまり上がらない、L3キャッシュなどに限られるのかもしれない
さて、この論文のタイトルはSystem Optimizationとなっているが、説明として「STCOやDTCO、DPCOといった技法を通じてプロセッサーの設計におけるPPACの大幅な改善を実現した」とある。STCO(System-Technology Co-Optimization)はシステム技術最適化、DTCO(Design-Technology Co-Optimization)は設計技術最適化、DPCO(Design-Process Co-Optimization)は設計プロセス最適化とでも呼ぶべき技術であり、この結果としてPPA(性能、面積、コスト)に加えC(コスト)面での最適化も実現できた、という話である。
最適化、というよりもバランスの問題であり、どのあたりでバランスを取るのがトータルとして一番適切かを見極めるのがこれらの技法である。STCOで、電源電圧をどこまで下げるのが適切かを示したのが下の画像だ。
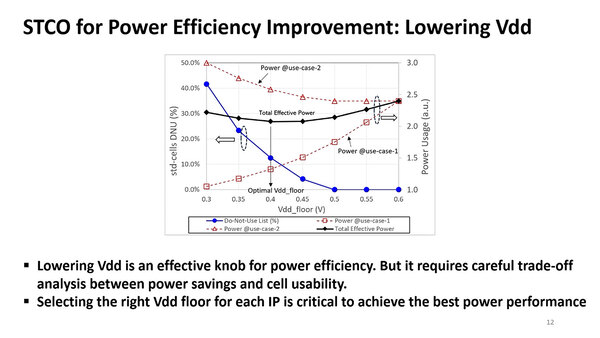
下げすぎると動作しないセルが発生するので、セルの構造に応じてVddをどこまで下げるのか調整が必要という話だ
Total Effective Powerで見れば、0.4Vあたりまで下げるのが一番効果的ではあるのだが、それでは10%以上利用できないセルが出てきてしまう。このあたりを勘案して、Vddをどこまで下げるかを決定したとしている。実際にはセルごとに細かく最適化することで、通常よりも低めに中心値をシフトさせることが可能になったとしている。
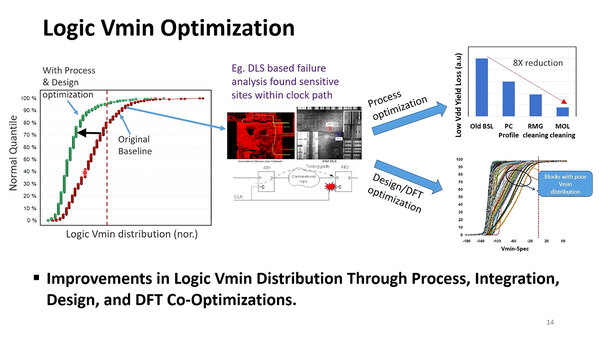
通常の設計技法よりも細かく検証するとともに、DFT(Design For Testing)の技法も使うことで、Vminのばらつきを抑えることに成功した
ロジックだけでなくメモリーに関しても同様の最適化を施すことで、Vminのばらつきをはるかに小さく抑えられた、とする。
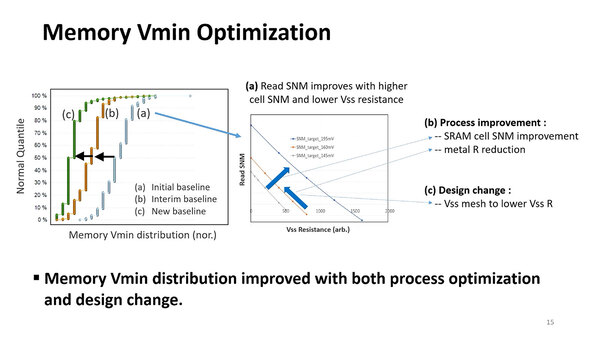
SNM(Static Noise Margin)はSRAMの動作の安定性の指標で、これが大きいほど安定して動作する
また同様の技法でCPUのVminも最大80mVほど低減できた、としている。もっとも右の内訳をみてみると、Design Optimizationによる低減と同じくらい、Gate profile tuningの低減分が大きくなっており、かなりプロセスそのものに手を入れたように見える。
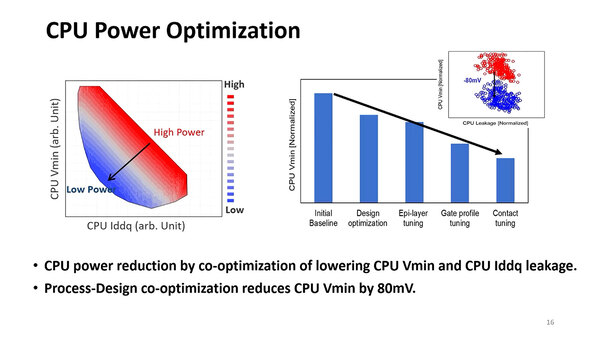
Vminを下げると、CPU待機時の消費電力をそれだけ抑えられる
他にもIDDQ(IDD Quiescent)を機能ブロックごとに低減させたりといった細かい工夫がなされたとする。ちなみにこのケースで言えば、Block-Aは設計値と実際の値が一致しているが、Block-Bでは10%ほど低減させることに成功している。ただ具体的にどんな機能ブロックなら低減できたか、の説明はなかった。
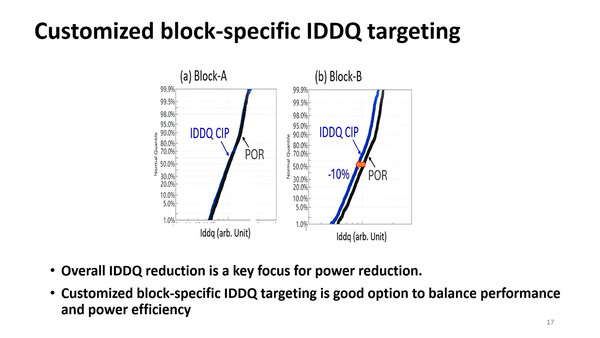
IDDQは回路が静止状態に流れる電流のこと。理屈から言えばゼロにしたいところだが、実際にはゼロにならずわずかに電流が流れる。これをどこまで減らすのかは待機時電力を減らす際に非常に重要になる
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















