



ロードマップでわかる!当世プロセッサー事情 第861回
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説
2026年02月02日 12時00分更新

原則としてIEDMはプロセッサー全体をカバーするものではなく、プロセッサーを構成する技術要素にフォーカスを当てた学会なので、プロセッサー全体を対象とした論文は少ない。
そんな中、Session 38(System Optimization and Process Innovation)でQualcommが行なった"Comprehensive Enhancements for AI Mobile Edge Computing: Innovations from Device-Level Advancements to Advanced Packaging and System Optimization"という招待講演は、システム全体をどう最適化するかという観点に立っての議論ということで、珍しくSoC全体を論じていたので、説明したい。

昨年12月にサンフランシスコで開催された、半導体デバイス技術に関する世界最高峰の国際学会「IEDM 2025」
100TOPSの性能を実現するためにNPUの性能を引き上げた
Snapdragon X2 Elite
まず簡単に説明しておけばSnapdragon X2 Eliteは2025年9月にハワイで開催されたSnapdragon Summit 2025で発表されたばかりの、Arm PC向けSoCである。今年(2026年)のCESでも、多くのメーカーがこれを搭載したノートを発表しているので気になっている方も多いだろう。

Snapdragon X2 Elite
さてそんなSnapdragon X2 Eliteであるが、先の記事にもあるようにCPUのコア数が12→18に増強、GPUはAdrenoのままだが新世代になり、フレームレートで言えば前世代と比較して平均2.3倍に強化。NPU性能も前世代比で78%高速な85TOPSに達している。なのだが、Snapdragon X2 Eliteの仕様策定にあたってはまずAI性能が最初に議題に挙がったらしい。
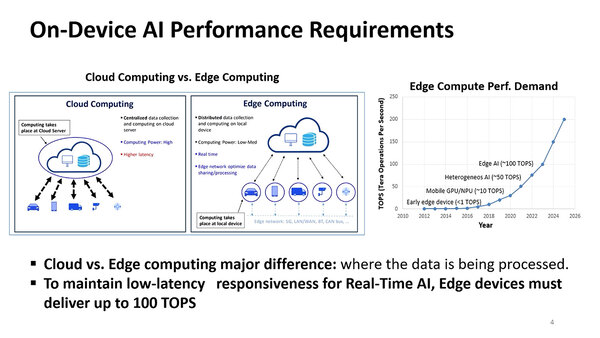
100TOPSがこの世代の目標だったらしい
もっともこの100TOPSはSoC全体、つまりCPU+GPU+NPU全部合わせて、という話である。ただこれ、結構に難しい。下の画像の左側は性能に対するトレンドと実際に実現できる性能を示したもので、CPUとGPUに関して言えば、それほど性能には寄与しえない(縦軸が対数軸であることに注意)ので、性能を達成するためにはやはりNPUの性能を引き上げるのが一番得策である。
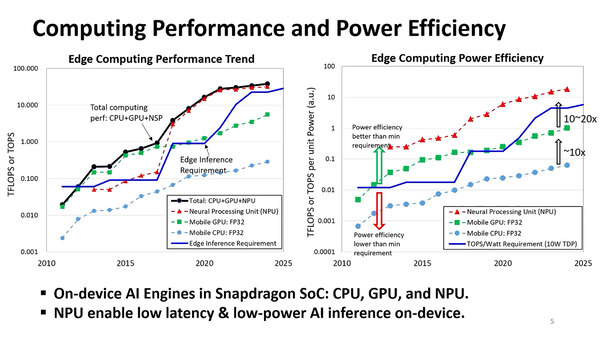
左側は性能に対するトレンドと実際に実現できる性能を示したもの。なぜか右のグラフは"CPU+GPU+NSP"と書いてあるが、これはNPUの間違い。Qualcommの場合はDSPベースのNPUなので、Neural Signal Processingの略でNSPでも間違いではないのだろうが。おそらくDSPと書いたのをNPUに直すつもりでNSPにしてしまったのだろう
GPUでFP32ではなくFP4もサポートできるようにすれば、確かに演算性能は上がる。単純計算で8倍なので、2025年の時点で8TOPSくらいのものを64TOPSくらいまで引き上げられるかもしれないが、絶対性能はともかくとして、性能/消費電力比の方が大問題になるので、ここは素直にNPUに任せた方が得策である。問題はその性能/消費電力比の方である。
上の画像の右側がこれに相当するわけだが、TDP枠はスマートフォン向けのシリーズが1~2W、タブレットでも約5Wなのに対し、Arm PC向けは10W程度まで許容できるとしているが、それでも100TOPSを実現しようとすると10TOPS/W以上を実現しないといけない。この観点ではCPU/GPUともに絶望的である。また純粋に性能だけでなくレイテンシーの低さもEdge AI向けでは求められる。この点でもGPUはかなり不利である。結果、やはりNPUに任せるのが得策という結論になる。
とはいっても、実際にCPU/GPU/NPUのどれを使うのかというのはアプリケーション側が決める。そこで設計にあたってはターゲットアプリケーションを定め、それぞれのアプリケーションで満足できる性能を確保できる形で最適化を進めることになったそうだ。
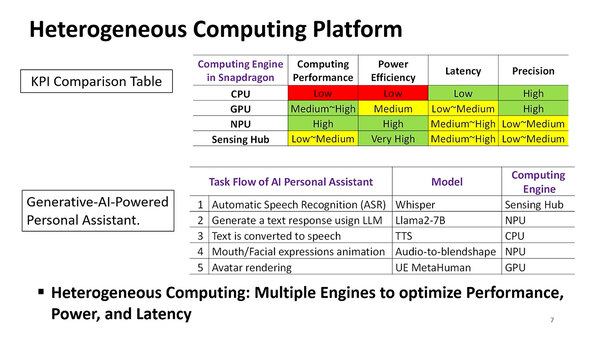
KPI(Key Performance Indicator)の比較テーブルで、赤が一番厳しい部分、黄が努力次第、緑は比較的容易に達成になる。ただ下の表を見ると、テキストの読み上げなどはCPUでやることになっており、CPUはこれを達成できる範囲でなるべく省電力に振る、といった最適化がされる
ハードウェア的な工夫をまとめたのが下の画像だ。
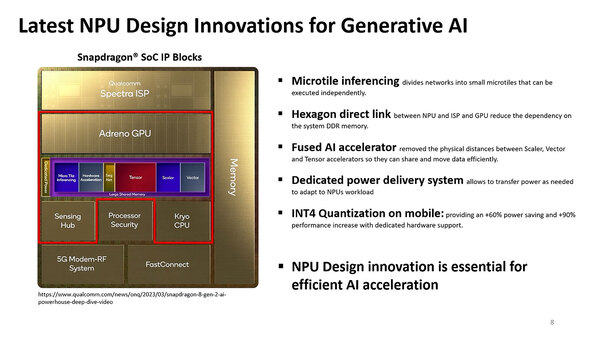
Snapdragon SoCの改良点。これはあくまでラフな構成図であって、実際のダイの配置をそのまま反映したわけではないはずだ
Hexagon NPUは中央に配されている格好だが、以下のようにNPUの性能改善にずいぶん手を打っていることがわかる。
| Snapdragon SoCのハードウェア的な工夫 | ||||||
|---|---|---|---|---|---|---|
| Microtile inferencing | それぞれのタイルについて細かく分割したマイクロタイル構造とし、独立させて動かせるようになった。複数のネットワークを動かすのではなく、一つのネットワークを分割して処理することで効率化を図ったものと思われる。 | |||||
| Hexagon direct link | NPUとISP/GPUの間で専用の接続を用意することで、CPUを介さずに例えばISPで取り込んだ画像をそのままNPUで画像分析が可能になった。この際CPUを介さないがゆえに、一度外部のDRAMに格納する手間も省けた。 | |||||
| Fused AI accelerator | NPU内部のデータの持ち方を工夫することで、SRAM領域を共有で利用可能とし、かつデータ移動の手間を省いた。 | |||||
| Dedicated power delivery system | NPU専用の電源コントローラーが用意されたようで、利用するワークロードに応じて細かくVector/Scalar/Tensor/...の各ユニットに電力を供給できるようにした。これは単に不要なブロックの電力を減らすだけでなく、フルに動いているブロックに優先的に電力を供給できる仕組みが用意された。 | |||||
| INT4 Quantization on mobile | NPUに関してはINT4をサポート。消費電力を60%以上削減し、90%以上の性能向上を実現した。 | |||||
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















