



ロードマップでわかる!当世プロセッサー事情 第855回
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術
2025年12月22日 12時00分更新

液冷を直列から並列配管に変更して
チップを均等に冷やす計画
500kWや1MWという消費電力のほとんどは、最終的には熱になって放出されるので、これを冷却する必要が当然ある。前回説明したCatalinaは、Compute Rackの横にAALC(Air Assisted Liquid Cooling)を2つ並べる構成にしているが、実はこれもMetaだけの独創的な発想ではなく、わりと一般的な構造である。
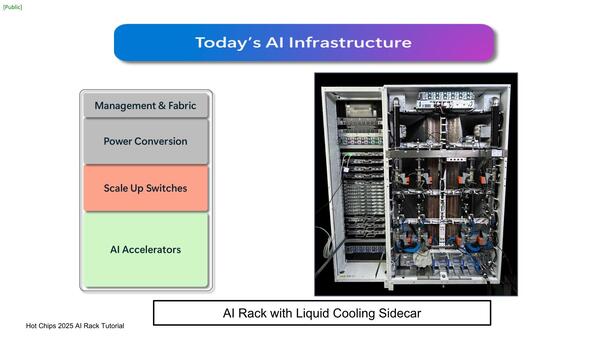
これは背面からみたもの。巨大なラジエーター2つが右側のCooling Sidecarに鎮座しているのがわかる。そのラジエーターの手前に、8基のポンプがあるあたり、このポンプで冷却液を循環しているのだろう
従来のデータセンターは空冷を前提に強力な冷房を用意しているため、そのまま設置できるという話である。ただGB200 NVL72はラックあたり120kWの消費電力で、それを冷やすのにAALC用のCooling Sidecarが4本必要となる。
Blackwell Ultra(150kW)ではCooling Sidecarが5本、200kW+のRubinでは最低でも7本必要になる計算だ。600kWのRubin Ultra世代になるとCooling Sidecarが20本並ぶ計算になる。さすがにこうなるとデータセンターの面積が無駄に大きくなるし、ラック同士をつなぐネットワークの距離も伸びるため、現実的な選択肢と言いにくい。
この分野に関して、かなり昔から研究していた先駆者がGoogleである。公式には2018年から液冷を利用していると公表しているが、社内では2014年から実装を開始、2018年には社外にも提供できる品質と性能のものが完成し、2024年には1GWの冷却に対応できるものが完成したとしている。

2014-2016年はTPU v3、2017年はTPU v4ベースで、2019年以降はTPU v5以降の全TPUに対応する形だ
まずチップの冷却で言えば、TPU v3世代は複数のチップをSeries(直列)につないでおり、これは冷却液の流量をそれほど高めなくても済むメリットがある一方、温度管理に問題があったという。
そこでTPU v4からはすべてのチップに対して並列で冷却経路を用意する形にしたことで、流量管理もチップごとにできるようになった。

TPU v3では直列の最後のチップが既定の温度になるような管理をしており、結果その手前のチップはやや冷却過多になっていたとする。並列に通すということはそれだけ冷却液の流量を増やさないといけない
またTPU v3ではダイとCold Plateの間にヒートスプレッダが挟まっており、これが熱抵抗を増やす要因になっていたので、TPU v4ではヒートスプレッダ(とTIM)を省くことで、効率を向上させたとしている。あと冷却液の流速もチップごとに調整できるようになっているとする。
そしてその冷却液の循環方法であるが、そもそも液冷には以下の4つがある。
| 冷却液の循環方法 | ||||||
|---|---|---|---|---|---|---|
| DLC (Direct Liquid Cooling) |
1相式、つまりチップを冷却して温度が上がった冷却液を、そのままデータセンター建屋外部のクーリングタワーに送り出して冷却し、再びチップに送り込む方式。 | |||||
| DTC (Direct to Chip Liquid Cooling) |
2相式、つまりチップを冷却する一次冷却液と、その一次冷却液を冷やす二次冷却液から構成される(クーリングタワーには二次冷却液が送られる)。この方式のメリットは、より沸点の低い冷却液を一次側に利用して、沸騰冷却できること。沸騰冷却は、通常の液冷よりもより効率的に熱をチップからうばえ、効率が高い。 | |||||
| CLLC (Closed-Loop Liquid Cooling) |
DLCに構造は近いが、冷却システムもサーバーの中に収めている点がDLCと異なる。冷却能力に制限はあるが、外部にクーリングタワーを設ける必要がないので設置が容易というメリットがある。 | |||||
| 液浸 | サーバー全体を冷却液にドブ漬けし、その冷却液を外部のクーリングタワーで冷却する方式。 | |||||
MetaのCatalinaはCLLCに相当するが、GoogleではDTCを利用すると決めた。ラックの列の端にCDU(Coolant Distribution Unit)と呼ばれる熱交換器+ポンプの塊があり、ここで一次冷却液(サーバーラックまで送られてチップを冷やす液体)と二次冷却液(一次冷却液の熱を奪い、それを外部のクーリングタワーで冷却する)の間の熱交換を行なう仕組みである。

CDUの構造は、講演では動画の形でその構成が紹介された
CDUには専用のUPSが用意され、これで電源断により冷却不足を引き起こす事態を防止するほか、CDU自体も冗長構成を取っており、Googleの説明によれば2020年以来の稼働率は99.999%を常に維持しているという。

CDUそのものもすでに第4世代になっている
Googleは現在Project Deschutesという名称で、第5世代のCDUを開発中だが、Deschutesに基づくCDUの設計情報はGoogleからOCPに寄贈されることになっており、これは先のMt.Diabloと組み合わせる形で将来のデータセンターで使われることを想定しているそうだ。当然Deschutesも、消費電力1GWのデータセンターに向けたものになると考えられる。

一組のCDUで何ラックのサーバーの冷却ができるかは明確な数字は出ていない。TPU v3世代のラック8本を1台のCDUでまかなえていることから考えるに、1MWまではいかないまでも800kWくらいまではなんとかなりそうに見える
この連載の記事
-
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 - この連載の一覧へ























の1台が今ならオトク!")
























")













