




S2V:音声×画像から自然なリップシンク動画
Wan2.2 S2Vは、音声とリファレンス画像から、動画を生成する「Sound-to-Video(音からビデオ)」モデルです。数百万のクリップからなる音声・動画データセットを構築して、パラメータのトレーニングをしたようです。複数の解像度でのトレーニングと、複数解像度の推論をサポートしており、縦横のどちらの解像度でも生成できるようになっています。写実からアニメ映像まで、そのスタイルも幅広さをアピールしています。
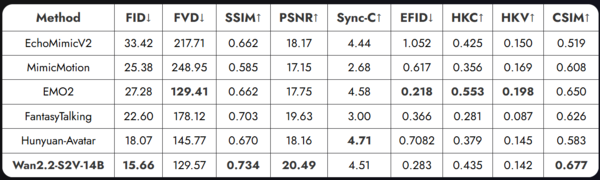
画像に合わせて的確なリップシンクをする機能は常に求められてきており、その分野も激しい技術競争がされています。「FantasyTalking」などのモデルが登場してきていますが、アリババは、他社のものに比べて、FID(映像品質)、EFID(表現の信憑性)、CSIM(同一性の一貫性)といった主要指標において、類似モデルの中で最良、またはそれに近い性能を達成しているとしています。
単にリップシンクをするだけでなく、動きの生成もプロンプトによって指定できる特徴があります。リップシンクと同時に頭の傾き・視線・手の微動をさせることができ、その点も評価されています。
ComfyUIは公式ワークフローを公開しています。モデルは、やはりfp8方式で量子化されている「wan2.2 s2v fp8 14B scaled」と、高速化のための「Wan2.2 LightX2V 4steps Lora」が選択されています。
基本は640x640ですが、832x480の横長画面に設定を変えて、6秒ほどの読み上げの作例を作成してみました。また、英語の音声を読み上げる「ChatterBox Voices TSS(Text-to-Speech)」をワークフローに組み込んでいます。筆者の環境で、生成にかかったのは、モデルのロード時間を除くと、約2分でした。
▲英語を話させてみた作例。下の画像が参照画像
このS2Vのワークフローの組み方は、少し変わった作りになっており、生成過程は約4.81秒(16FPSの77フレーム分)を一単位としています。それを組み合わせることで、長くすることが可能になります。デフォルトでは2組14秒が設定されており、組み合わせるとどんどん長くできる仕組みです。音楽を歌わせたりする場合には自然と長い設定にするとよいでしょう。ただし、長くすると、生成にかかる時間は極端に伸びていきます。
歌声を使って作成してみました。次は2つの生成過程を組み合わせて9秒の動画を生成してみたところ約35分かかりました。プロンプト設定にもよりますが、少し極端な動きにも見え、顔に崩れがあるようにも思えます。LightX2Vで高速化している影響で激しい動きでは品質低下が起きる傾向があり、特に手や顔の形が崩れやすい傾向があるようです。
現状は、最適なパラメーター設定の模索がSNS上で進められているため、その結果を待つ必要がありそうです。
▲歌を歌わせてみた作例。サイズは832x480。品質については、このままでは物足りない
一方で、クラウドサービスでの対応が進んでいます。WaveSpeedAIでは5秒につき0.15ドル(約23円)で480pの動画が最長2分まで対応しています。同じ条件で生成してみたところ、生成時間は約5分で、0.44ドル(約66円)ほどでした。ローカルで生成したものよりも品質が高いため、十分な選択肢になると考えられます。
WaveSpeedAIを使い、プロンプトを次のように指定して、アニメ系の動画でも試してみました。「コンサート会場で、アイドルの女の子が楽しそうにダンスをしながら歌っている。まわりの女の子は彼女に合わせて、ダンスしている。カメラはアイドルの女の子を中心に、緩やかにズームアウトする」(実際は英訳して指定)。アニメ画像でも十分に動いていることが確認できます。
▲WaveSpeedAIでの生成結果、720x544とサイズも最適化されて出力される
▲WaveSpeedAIでのアニメ画像での生成結果、下がリファレンス画像
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第152回
AI
Seedance 2.0×AIエージェントでAI動画が激変 “AI脚本家”や“AI絵コンテ作家”との共同作業で、アニメ制作が身近に -
第151回
AI
画像・動画生成AIの常識が変わる、Claude Codeに全部やらせる方法論 -
第150回
AI
無料でここまで? 動画生成AI「LTX-2.3」はWan2.2の牙城を崩すか -
第149回
AI
AIと8回話しただけで“性格が変わる” 研究が警告する「おべっかAI」の影響 -
第148回
AI
AIが15万字の小説を1週間で執筆──「Claude Opus 4.6」が示した創作の未来 -
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")




