



Stable Diffusion入門 from Thailand 第32回
【無料】動画生成AI「Wan2.2」の使い方 ComfyUI設定、簡単インストール方法まとめ
2025年09月08日 17時00分更新

公式ワークフローで試す
ComfyUIの「公式ワークフロー」を試すには、ComfyUIを最新のものにアップデートする必要がある。
Stability Matrixを使ってComfyUIをインストールしている場合は「更新」をクリックするだけでアップデートが完了する。Stability Matrixを使っていない場合は自分で git pull / pip update が必要だ。
「更新」をクリック
更新が終わったら「Launch」をクリックしてComfyUIを起動しよう。
「Launch」をクリック
ComfyUIを起動すると、以前開いていたワークフローが表示されるが、それは無視して画面左の「Templates」をクリック。
「Templates」をクリック
ワークフローのテンプレート一覧が表示される。ここでテンプレートを選ぶと、対応するワークフローが展開されることになる。まずはサイドバーで「Video」を選択。
「Video」を選択
少し下にスクロールすると「Wan 2.2 5B Text to Video」という「TI2V-5B(50億パラメーター)」モデルを使用するテンプレートがあるのでこれをクリック。
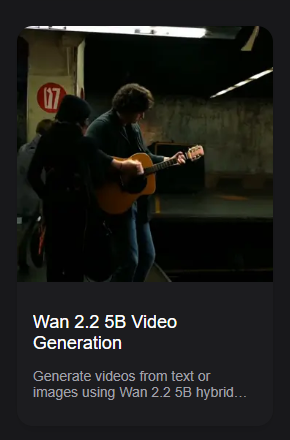
事前にモデルやVAEをダウンロードしていない場合ここで警告が表示される。すべてのDownloadリンクをクリックしてダウンロードをスタート。
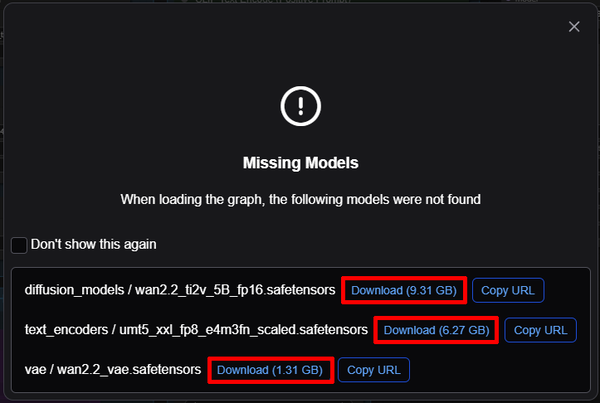
各ファイルの保存先はここになるのでしっかり確認しよう。
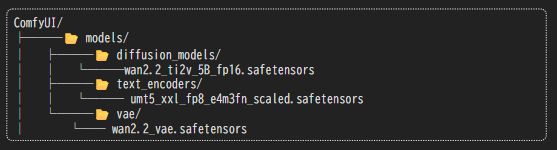
正しい階層にダウンロード
最大17GB近くのファイルをダウンロードすることになるのでそれなりの時間はかかる。
ダウンロードが終わるとComfyUI上に「Wan 2.2 5B Text to Video」ワークフローが展開される。
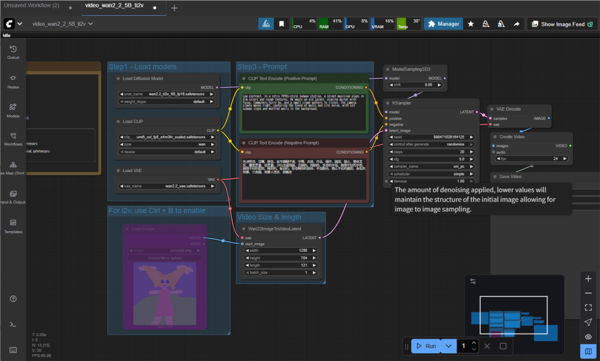
まずはプロンプトもそのままの状態で動画を生成してみよう。
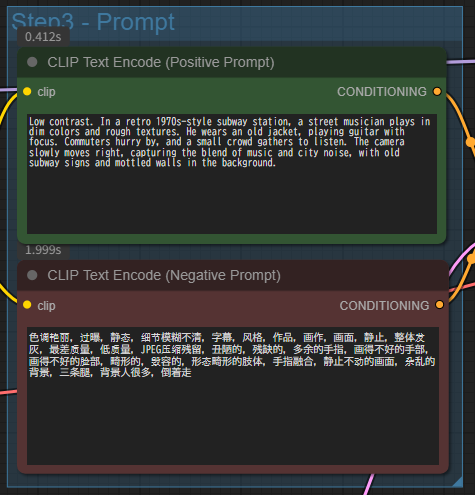
プロンプトはデフォルトのまま
右下の「Run」ボタン(もしくはShift+Enter)をクリックで生成が開始される。
筆者の環境では「VAE Decode」ノードで10分近く動かなくなり少し心配になった。
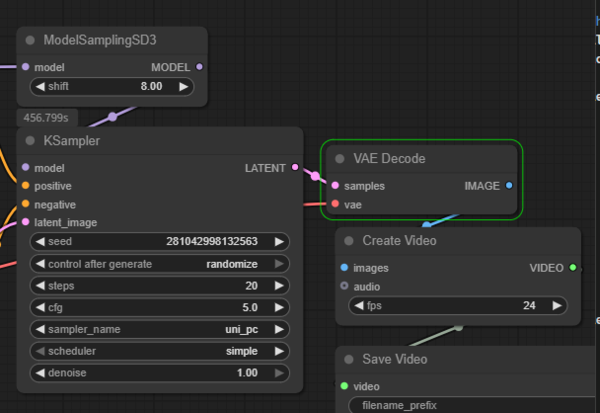
緑枠で囲まれているのが「VAE Decode」ノード
コンソールを見てみると、ログに「Requested to load WAN22」と表示されている。これはWan2.2本体モデルの読み込み開始を意味しており、ここからVAEなどの重いデータを展開するため数分間止まったように見えるのは正常動作だ。
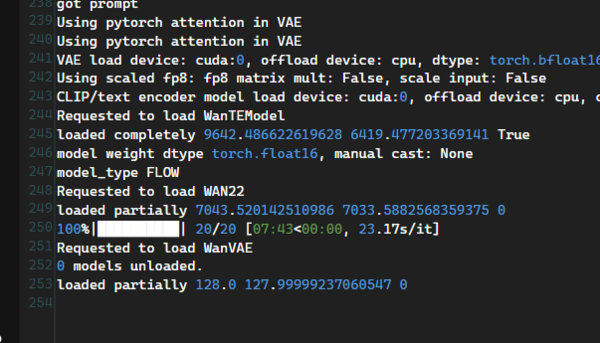
しばらくそのまま待っているといきなり動画が完成し、右下の「Save Video」ノードに表示された。
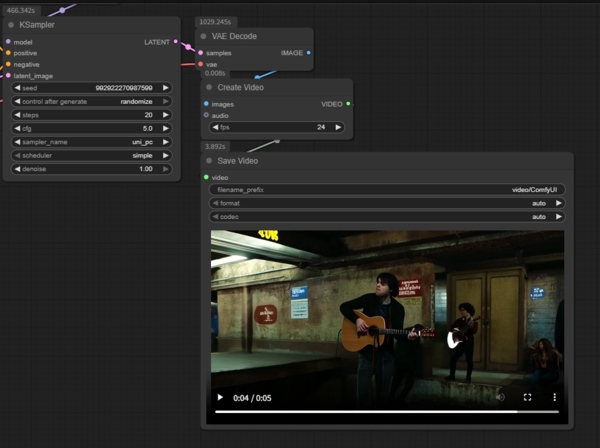
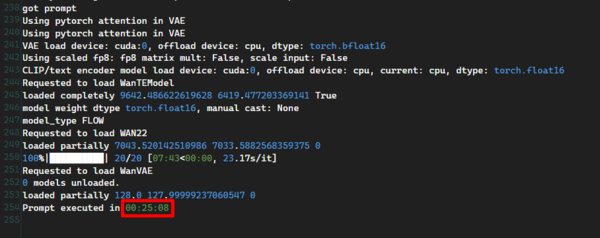
5秒の動画を生成する所要時間は約25分だった。
とは言え生成された動画はかなりクオリティーが高い。なお生成に使われたプロンプトは以下のデフォルトプロンプトだ。
プロンプト:Low contrast. In a retro 1970s-style subway station, a street musician plays in dim colors and rough textures. He wears an old jacket, playing guitar with focus and passion. Only a small light source from above illuminates the scene in the dark, atmospheric underground city lit less, with old subway signs and mottled walls in the background(低コントラスト。レトロな1970年代スタイルの地下鉄駅で、ストリートミュージシャンが薄暗い色彩と粗い質感の中で演奏している。彼は古いジャケットを着て、集中と情熱をもってギターを弾いている。上からの小さな光源のみが、古い地下鉄の標識とまだらな壁を背景にした、暗く雰囲気のある地下都市の照明の少ないシーンを照らしている。)
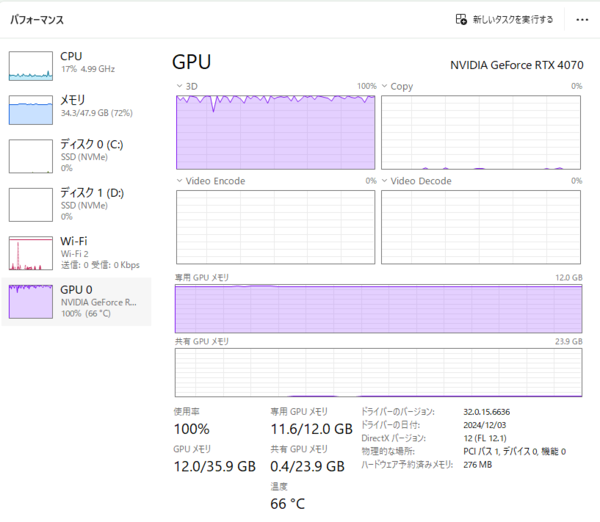
生成時のパフォーマンス。GPUメモリーは11.6GB使用、それでは全然足りないのでCPUメモリーも大量に使っているのがわかる。温度も66度とまあまあ高い。ただしCPUの負荷は限定的だ。
次にプロンプトをこちらで考えたものに差し替えて生成してみる。
プロンプト:A young woman turning her head and smiling, close-up shot, shallow depth of field(頭を振り返って微笑む若い女性、クローズアップショット、浅い被写界深度)
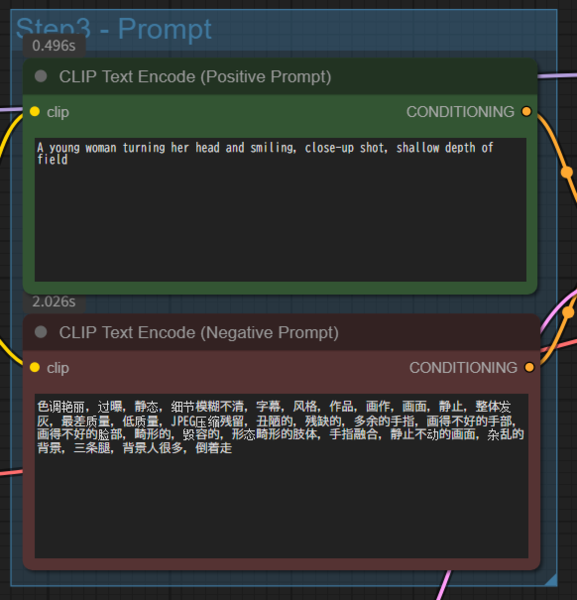
こちらが生成された動画。少々イメージとは違ったが生成された動画に破綻はなさそうだ。
2回目の生成ということで多少のスピードアップを期待したが生成時間は変わらなかった。
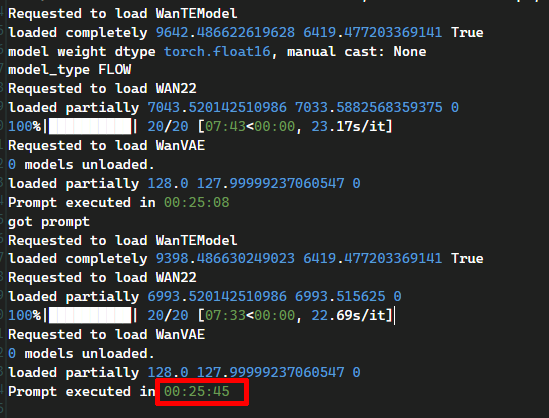
生成時間は変わらず25分
以上RTX 4070(12GB VRAM)環境でも問題なく動作し、高品質な動画が得られることが確認できた。ただしVAEのロードや生成には時間がかかり、短尺でも実時間の数倍〜十倍以上の待ち時間が発生してしまった。また、VRAMが12GBと限られているため、毎回メモリーをやりくりしながらモデルをロードする必要があり、2回目以降も時間が短縮されることはなく、ほぼ同じ時間がかかってしまった。
これ以上のスピードを求めるなら解像度やフレーム数を下げるなど調整を追い込んでいく必要があるだろう。量子化モデルやLoRA軽量化を検討するのも手だ。
なお、5B(50億)パラメーターモデルでこの状態なので、「T2V-A14B」や「I2V-A14B」といったよりサイズの大きなモデルをこのままの状態で動かすのは現実的ではないだろうということで今回は割愛。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第40回
AI
Suno級がローカルで? 音楽生成AI「ACE-Step 1.5」を本気で検証 -
第39回
AI
欲しい映像素材が簡単に作れる! グーグル動画生成AI「Veo 3.1」の使い方 -
第38回
AI
最新の画像生成AIは“編集”がすごい! Nano Banana、Adobe、Canva、ローカルAIの違いを比べた -
第37回
AI
画像生成AIで比較!ChatGPT、Gemini、Grokどれを選ぶ?得意分野と使い分け【作例大量・2025年最新版】 -
第36回
AI
【無料で軽くて高品質】画像生成AI「Z-Image Turbo」が話題。SDXLとの違いは? -
第35回
AI
ここがヤバい!「Nano Banana Pro」画像編集AIのステージを引き上げた6つの進化点 -
第34回
AI
無料で始める画像生成AI 人気モデルとツールまとめ【2025年11月最新版】 -
第33回
AI
初心者でも簡単!「Sora 2」で“プロ級動画”を作るコツ -
第31回
AI
“残念じゃない美少女イラスト”ができた! お絵描きAIツール4選【アニメ絵にも対応】 -
第30回
AI
画像生成AI「Midjourney」動画生成のやり方は超簡単! - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















