



ロードマップでわかる!当世プロセッサー事情 第838回
驚異のスループット! NVLink Fusionで最大900GB/秒を超えるデータ転送速度を実現する新世代AIインフラ
2025年08月25日 12時00分更新

COMPUTEX TAIPEI 2025でNVLink Fusionを発表
従来のPCIeを大幅に上回る帯域幅と低遅延を実現
NVLinkやNVSwitchは(AMDのInfinity Fabric同様に)NVIDIA独自のものであり仕様などは一切公開されていないのだが、今年のCOMPUTEXにおいてNVIDIAはNVLink Fusionを発表した。

NVLink Fusionでは、顧客のカスタムASICの隣にNVLinkチップレットを配置し、NVIDIAのコンピュートボードやAIスーパーコンピューターのエコシステムに統合する
もっとも、発表時の説明を読んでも今ひとつ内容がわかりにくい。端的に言えば、CPUベンダーあるいは独自のASICを製造しているベンダーが、自社の製品にNVIDIAのGPUを組み合わせるにあたって、PCIeではなくNVLinkを利用できるようにする、というものだ。
PCIe経由での接続であれば今すぐにも可能なのだが、これはGPU同士の通信には遅くなりすぎる。そこでNVIDIAからNVLinkの利用権をライセンスする形を取って、自社のCPUやASICとNVIDIAのGPUをNVLinkで利用できるようにする、というのがNVLink Fusionになる。
もともとNVIDIAはGrace Hopperの世代にNVLink C2C(Core to Core)というCPUとGPUを接続するためにNVLinkの拡張をしている。これを一歩進めたのがNVLink Fusionという言い方もできるかもしれない。
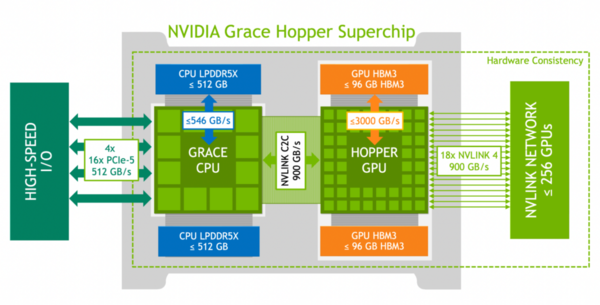
Grace CPUとHopper CPUの間がNVLinkで接続されている
さてそのNVLink Fusionだが、下の画像を見ると、上で書いた「自社CPUにNVIDIAのGPU」だけでなく、「自社GPU/アクセラレーターにNVIDIAのCPU」という組み合わせもNVLink Fusionでサポートされるようだ。

外部ネットワークであるSpectrum-X/BlueFieldが他のソリューション(青色)で代替されるのはともかく、CPUであるVeraとGPUであるRubinのどちらも他のソリューション(青色)で代替可能というのは興味深い
実際NVLink Fusionでサポートされる最初の世代は次のVera/Rubinの組み合わせになるが、現在のNVL72の構成のまま、カスタムチップで混在可能と説明されている。
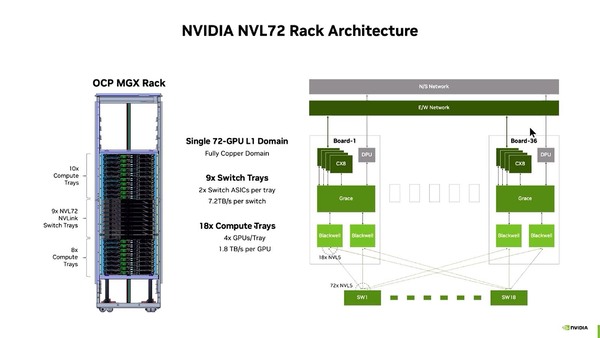
こちらは現在のNVL72の構成。2つのBlackwellと1つのGraceを載せたボード36枚が、18本のCompute Trayに収まる格好だ
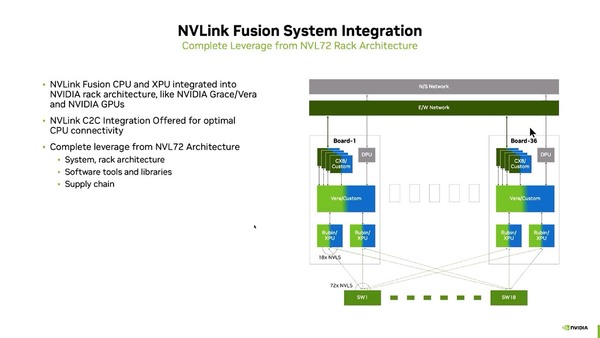
カスタムチップで混在可能。GraceがVeraないしカスタムCPUに、BlackwellがRubinないしXPUに変更される格好だ
もっともこれは概念図かと思われる。少なくともNVLink Fusionを使う場合にはNVL72のラックをそのまま流用しなければいけないという縛りはなく、ただ構成を説明するのにNVL72と同じような構成が利用できるというだけかと思われる。
なにげにサラッと描かれているが、GPU/XPU同士の接続には引き続きNVLink Switchが必要になっており、ここはNVIDIAとしては外部にライセンスするつもりはないようだ。このページの最初の画像でパートナーの中にMarvellが入ってはいるが、これはNVLink Switchのライセンスを提供しているわけではなく、おそらくはチップレット接続部分の実装に向けたものと思われる。
Marvellはネットワーク関連製品の製造以外に、自社以外のASICの物理実装の設計と製造の受託というビジネスをしている。Broadcomも同じくこうしたビジネスをしており、富士通のMonakaは過去の経緯を考えるとBroadcomにMonakaの物理実装を依頼しているのではないかと筆者は考えていたのだが、今回パートナー企業にBroadcomではなくMarvellの名前があるあたり、ひょっとすると物理実装のパートナーがMarvellに変わった可能性もありそうだ。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")










































