



ANAグループの共通データ基盤「BlueLake」 最新版はIcebergを採用し、AI時代に備える
グループ4万人のデータ活用で“ANA経済圏”確立を目指せ 進化するANAのデータレイクハウス
2025年08月15日 15時45分更新

最新版・BlueLake V4は「Apache Iceberg」採用、処理の効率と性能を高める

井岡氏は、BlueLakeではV1の段階から一貫して、「最も汎用的な形式である『ファイル』でデータを管理する」という考え方を維持してきたと語る。実際にV3のアーキテクチャを見ても、データ処理は「Amazon S3」側で行ったうえで、Snowflakeの内部テーブルに取り込むのではなくParquet形式のファイルとしてS3上に保持し、Snowflakeからは「外部テーブル」として参照する形をとっている(一部の大規模データセットを除く)。
このように、データをファイルとして管理することで、将来的にSnowflake以外のデータプラットフォームに移行することになっても容易に対応できる、マルチクラウド環境でのデータ管理が簡素化される、ファイルを中心に据えてDWH/BI/カタログ/処理エンジン/AIなどをシンプルに統合できる、といったメリットがあると説明する。井岡氏は、こうしたデータ管理の環境を「ファイルベースのSingle Source of Truth」と呼ぶ。

BlueLake V3のアーキテクチャ。S3上のParquetファイルをSnowflakeの外部テーブルとして読み込む形だった
ただし、取り扱うデータやファイル数が増大するにつれて、課題も生じ始めていた。運用管理面では「高頻度でSnowflakeにデータをロードするのが非効率」「障害発生時のデータ復旧が困難」という課題が、パフォーマンス面では「大容量のParquetファイルのスキャンには時間がかかる」「マイクロパーティショニングなど、Snowflakeの処理高速化機能が活用できない」といった課題があった。
そこでANAでは2025年、多数のParquetファイルを管理するためのメタデータフォーマットとして「Apache Iceberg」を採用する方針を固め、BlueLake V4のPoCを開始した。
Icebergを組み込んだBlueLake V4のアーキテクチャでは、新たなデータを保存すると、データ本体はS3に、そしてメタデータはIcebergカタログに自動配置される。V3のように、まずS3にデータを保存して、Snowflakeで外部テーブルとして定義する手間が省ける。またSnowflakeだけでなく、Sparkを利用するソリューションからも共通のIcebergカタログを通じてデータを参照できる。
なおIcebergカタログの選定においては、Snowflakeの内部テーブルと同等のインタフェースとパフォーマンスを維持できる、アクセス認証やセキュリティ管理もSnowflakeと一元化できる、追加費用も発生しないといった点から、現時点では「Snowflake Managed Iceberg」を選択している。
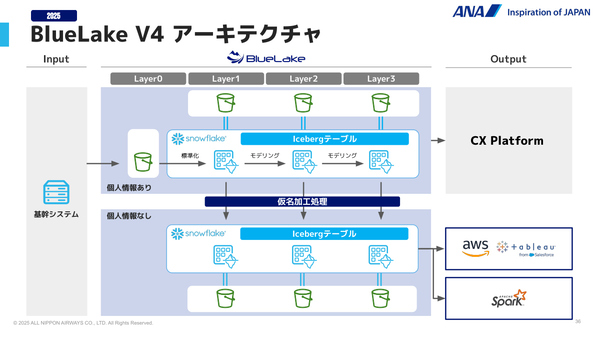
BlueLake V4のアーキテクチャ。SnowflakeにIcebergテーブル(メタデータ)を、S3にParquetファイル(実体データ)を配置する構成
BlueLake V4のPoCでは、Icebergの採用によるパフォーマンスの改善効果を検証するため、最小100万行から最大100億行のレコードを持つ6つの本番環境データを用いて、V3との比較検証を実施した。その結果、ETL処理(標準化処理と仮名加工処理)では最大3.9倍、クエリ処理(SELECT文の実行)では最大1.6倍の高速化が実現した。
BlueLake V3の抱えていた運用管理面、パフォーマンス面の課題を解決する見込みが立ったことから、ANAではBlueLake V4の本番採用に向けた開発を進めている(7月末のリリース予定)。
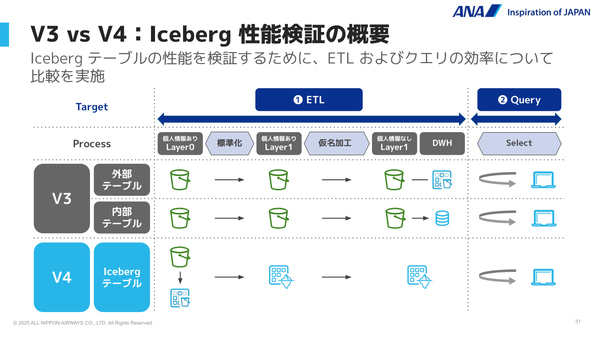
BlueLake V3とV4において、ETL処理とクエリの性能を検証した
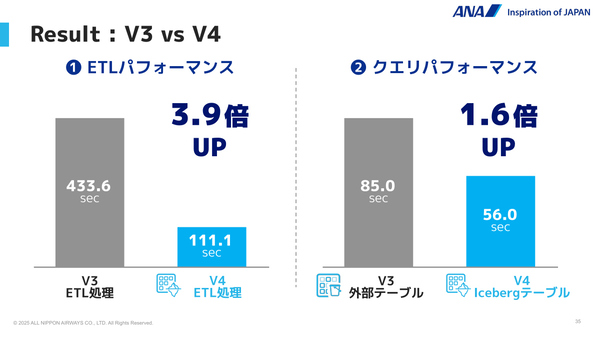
検証結果。いずれもV4が高いパフォーマンスを示した



