



NVIDIA NeMoやMegatronを利用、「GPU over APN」実現にまた一歩近づく
「遠隔分散GPU」の時代が間もなく NTT Comはいかに“3拠点”でのAI分散学習に成功したか
2025年03月25日 07時00分更新

生成AIやデータの利活用、画像処理などの進展に伴い、GPUクラスタの重要性が高まり、より多くの計算資源が求められている。
このような状況の中、NTTコミュニケーションズ(NTT Com)は、IOWN APNを活用した、3拠点の分散データセンターでの生成AI学習の実証実験に成功した。
実験では、東京の三鷹・秋葉原および神奈川県の川崎に設置された3拠点のデータセンターに、「NVIDIA H100 GPUサーバー」を分散配置した環境で、NTTの独自LLM「tsuzumi」の分散学習を実施。データセンター間は、100Gbps回線のIOWN APNで接続した。その結果、単一のデータセンターで学習させる場合の所要時間と比較して“1.105”倍と、ほぼ同等の性能を発揮できることを確認している。
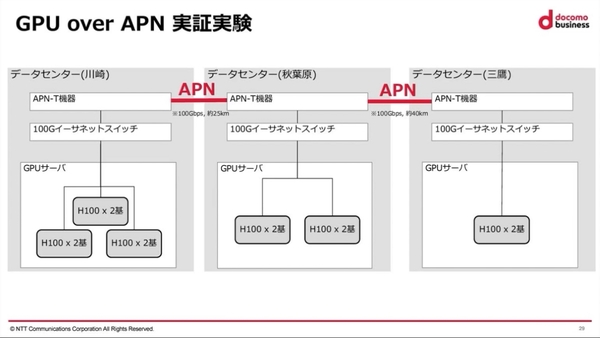
今回の実証事件の概要
本記事では、NVIDIAの開発者会議「GTC2025」における、NTT Comの同実証実験に関するセッションの様子をお届けする。
GPUサーバーの需要増には1つのDCでは対応しきれない
NTT Comのイノベーションセンター テクノロジー部門 担当課長である露崎浩太氏は、データセンターの現状について、「生成AIのモデルサイズの増大によって処理量が増加すると共に、より高精度で、より良いプロダクションモデルへの進化が求められている」と説明。
加えて、「より大規模なモデルを扱いたい場合には、ひとつのGPUには乗らない場合があり、複数のGPUに分割して学習する必要がある。そのため、学習用のデータを分散させて、複数のGPUで同時に学習させることで、全体の実行時間を短縮する動きが増えている」と述べる。
例えば、NVIDIA H100のメモリ容量は80GBであり、Mata社のLlama 3.1では1基のGPUには載せられず、複数のGPUが必要になる。このように様々な場面で、GPUリソース不足が課題となっているのが現状だ。
露崎氏は、「こうしたニーズに単一のデータセンターで対応するには、電源や熱量、ラックといったリソースに限界がある。今回の実証実験は、分散したGPUリソースを効率よく利用する『GPU over APN』の実用化に一歩近づく成果」と強調した。
GPU over APNは、2024年10月にNTT Comが発表したアプローチで、データセンター間をIOWN APNでつなぎ、オンデマンドにGPUリソースを確保。単一のデータセンターのように稼働させることで、GPU資源を有効活用することを目指している。
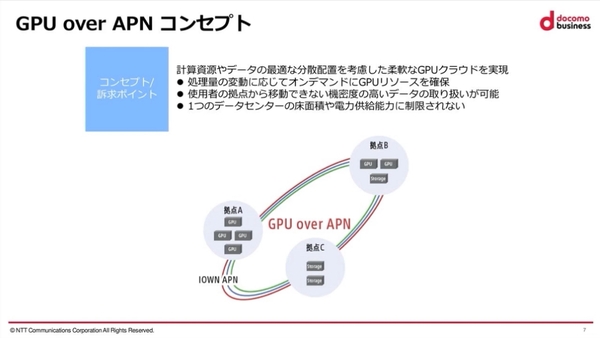
「GPU over APN」のコンセプト
また、すでに同社では、液冷サーバーに対応した超省エネ型コロケーションサービスである「Green Nexcenter」を展開する。リノベーションや増改築によって2025年3月に稼働する「横浜第1データセンター」および「大阪第7データセンター」と、2026年3月に稼働する「京阪奈データセンター」を、IOWN APNで結び、必要なときに、必要なリソースを活用できる環境を構築する計画を打ち出している。
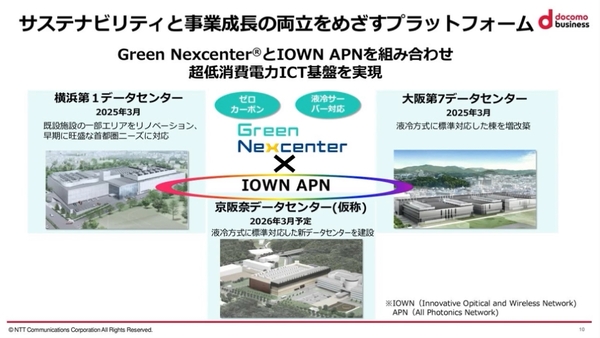
Green NexcenterとIOWN APNで超低消費電力ICT基盤を構築
分散学習に対応した開発基盤「NVIDIA NeMo」を活用
しかし、GPU over APNでは、マルチノードでスケールする分散学習フレームワークの選定が重要であり、さらに、NTT独自のLLMへの適用も未検証であった。
今回の実証実験では、分散学習に対応した生成AIモデルの開発プラットフォーム「NVIDIA NeMo(ニーモ)」を活用することで、こうした課題に対応したという。「GPU over APNは、既存のGPUリソースを有効活用して、さまざまな社会課題を効率的に解決するというコンセプト。それを実現するために、NVIDIA NeMoフレームワークやMegatronといった分散学習フレームワークについて検討を重ねてきた」と露崎氏。
Transformerの大規模学習ライブラリである「Megatron-core」の上で、クイックに実行できるNVIDIA NeMoや、カスタマイズ性が高いMegatron-LMといった学習実行フレームワークを活用。同社のイノベーションセンター テクノロジー部門 ソフトウェアエンジニアである鈴ヶ嶺聡哲氏は、「これらの学習実行フレームワークは、多様なモデルアーキテクチャーをサポートしていることや、bfloat16やFP8のサポートにより、学習の高速化やメモリ使用量の削減などの効果がある。また、分散並列学習手法のサポートも充実。LLM学習におけるコスト削減にもつながる」とそのメリットを述べた。
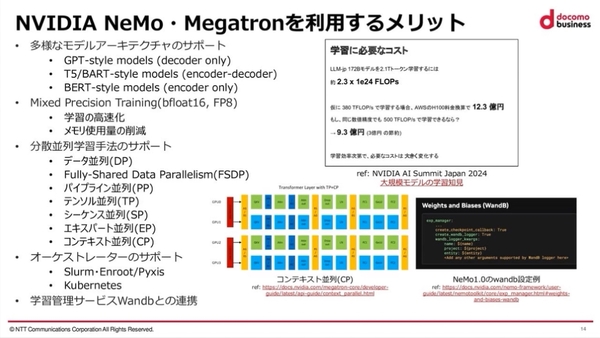
NVIDIA NeMoおよびMegatronを利用するメリット
また、GPUサーバー間の通信規格であり、データセンター内の低遅延通信を前提として設計されているNVIDIAの「GPU Direct RDMA」も活用。予備実験として、秋葉原と三鷹の約40kmの距離を100GbpsのIOWN APNで接続し、長距離RDMAにおけるパラメータの影響を調査した。その結果、Message sizeおよびQP sizeの増加が、スループットの向上に貢献することが判明したという。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



