



ライバルのGeForceとRadeonの良さを取り入れた2世代目
インテル“Battlemage”世代の新GPU「Arc B580」はRTX 4060/RX 7600以上の性能になる?
2024年12月03日 23時00分更新

より高効率を目指したXe2アーキテクチャー
Battlemageのアーキテクチャーについては、Lunar Lakeに搭載されている内蔵GPUと同じ「Xe2アーキテクチャー」が採用されている。Xe2アーキテクチャーにおいても、GPUコアの最少単位は「レンダースライス」だ。1基のレンダースライスの中には4基の「Xeコア」が含まれ、各Xeコアの中にはXVE(Xe Vector Engine)とAI処理に特化したXMX(Xe Matrix Engine)がそれぞれ8つ格納されている。
8つのXVEをまとめる共有L1キャッシュが増量されたほか、グラフィック描画タスクを様々な角度から分析し、Xeアーキテクチャーにあったレイテンシーを減らし、レンダースライスがストールを起こしにくい設計に改められた。特にSIMD16のネイティブ実行に対応することで、1フレームの描画における様々なステージにおいて処理時間を短縮することに成功している。

Arc B580に使われている「BMG-G21」フルスペックのブロック図。5基のレンダースライスと20基のレイトレーシングユニットなどから構成されている

レンダースライスの構成。GeForceでいうとことろのGPC(Graphics Processor Cluster)的なもので、最低限の描画機能を備えたユニットというべきもの

XeコアはRadeonで言うCompute Unitに相当するブロック。ここではL1キャッシュの容量が増量されたのが大きなポイント
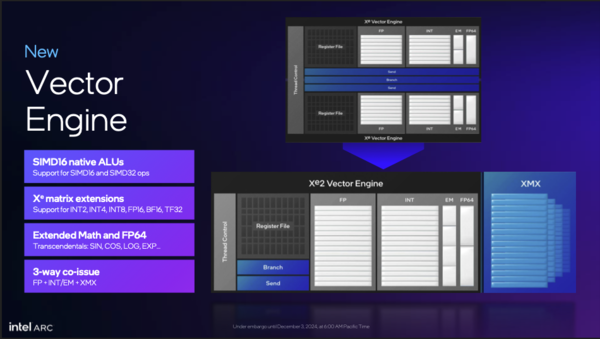
XVEではSIMD32のほか新たにSIMD16のネイティブ実行が可能に。これはゲームグラフィック処理において非常に大きな意味を持つとインテルは言う
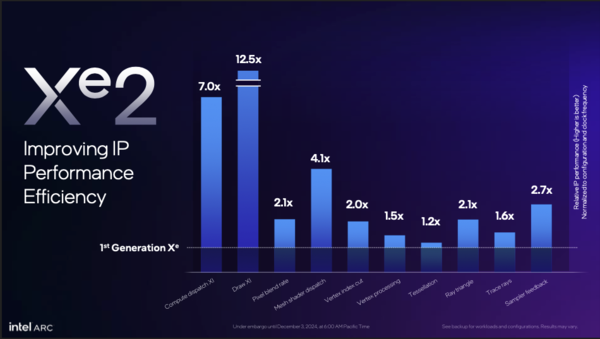
Xe2アーキテクチャーではXeよりもグラフィック描画における様々な機能が強化されている。従来はソフトウェアエミュレーションで実行していた部分もハードウェアで実装することで、古いゲームでも良いパフォーマンスが出ることが期待できる
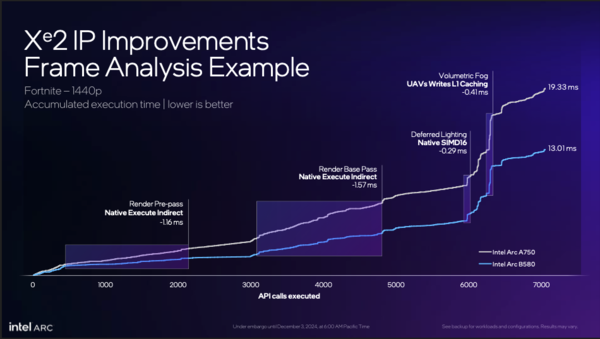
ゲーム「Fortnite」の1フレームあたりに発生するドローコールの回数は7000回以上。その際にXeとXe2でどの程度処理時間が必要かをグラフ化したもの(下にあるほど良い)。序盤から中盤はフロントエンド部の強化によるもの、終盤ではSIMD16のネイティブ実行やL1キャッシュの増量によって処理時間に大きな差がついた

レイトレーシングユニットも大幅強化。レイトレーシング処理には欠かせないBVH(Bounding Volumes Hierarchy)探索処理を高速・効率化するように機能強化されている

Xe2アーキテクチャーはXeアーキテクチャーに比べXeコアの性能は70%向上。ワットパフォーマンスでは50%向上しているとある。つまり機能強化してあるぶん消費電力も増えた、と考えることができる
本記事はアフィリエイトプログラムによる収益を得ている場合があります
































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















