



ロードマップでわかる!当世プロセッサー事情 第798回
日本が開発したAIプロセッサーMN-Core 2 Hot Chips 2024で注目を浴びたオモシロCPU
2024年11月18日 12時00分更新

レジスターやメモリーのほとんどがシングルポート
ソフトウェア制御だからこそできた珍しい構成
MN-Coreのチップ構造が下の画像である。基本になるのはMAB(Matrix Arithmetic Block)である。こちらはPE(Processing Element)×4とMAU(Matrix Arithmetic Unit)から構成される。
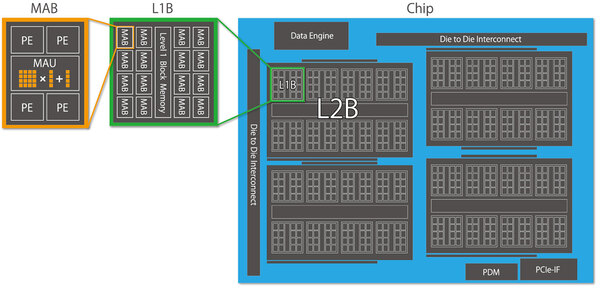
MAB×16にL1 Block RAMを合わせたものがL1Bで、そのL1B×8+L2 Block Memoryを組み合わせたものがL2Bとなる。1つのダイにL2Bが4個あり、4つのダイが相互接続されており、結果としてチップ全体ではMABが2048個、PEは8192個ある計算となる
MAUは行列専用のアクセラレーターであり、PEからデータを受け取って行列演算をして、その結果を再びPEに戻す仕組みである。ではPEの中身は? というのがこの下の画像。
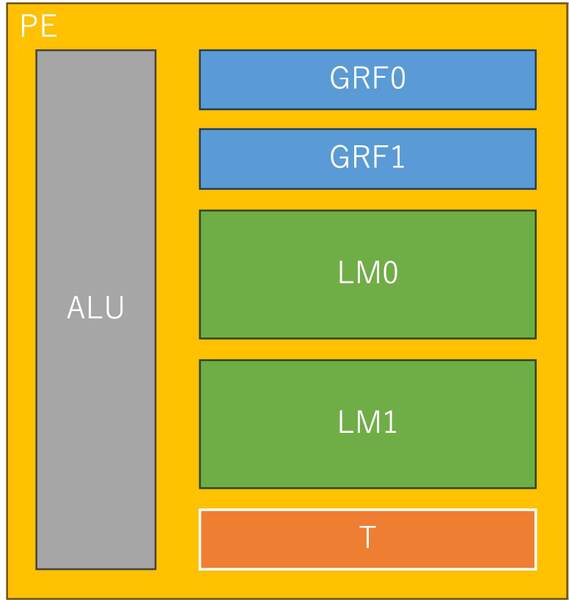
これはMN-Core 2のホワイトペーパーからの抜粋なのでMN-Coreではないのだが、大きくは変わらない。強いて言えば、2nd GRF(GRF1)はMN-Core 2で追加されたようだ
ALUに汎用レジスター(GRF)とローカルメモリー(LM)、それと一時データ保持用のTレジスター、演算結果のフラグを保持するフラグレジスターなども搭載される。LMはそれぞれ36KBの容量を持つが、特徴的なのはこれらのレジスターやメモリーのほとんどがシングルポート構成ということだ。
通常レジスターやキャッシュ、ローカルメモリーはマルチポート構成になっていることが多い。複数のユニットから同時に読み出したり、あるいは書き込みと読み出しを同時に行なったり、といったことが可能な構成になっている。ただこれは当然その分回路が複雑になるし、レイテンシーと消費電力も増える。
MN-CoreではGRF0/1のみR/Wが同時に可能だが、その他のSRAMはすべてシングルポート構成である。これは、通常のコアだとしばしばメモリーアクセスの競合が発生して性能低下の要因になりえるが、MN-Coreの場合はそもそもそうしたメモリーアクセスすらもソフトウェアから制御するので、競合が起きないようにプログラミングすることで無駄なトランジスタ数を減らし、効率を引き上げられる。
ここまででわかるように、PEもMAUも独立して動作する。したがってプログラミング次第であるが、SIMDのようにPEとMAUを並行して同時に動かすことも可能だし、その際の性能予測も容易である。なにしろハードウェア側がなにもしないから、正確に性能を推定できるわけだ。
データ移動も同様にプログラムで管理できるため、きちんとプログラミングできれば非常に効率的に動作する。逆に言えば、プログラミングの難易度は高い。そもそもMN-Core、設計段階でのコード名はGRAPE-PFN2(初代のGRAPE-PFNは冒頭で触れた、NEDO向けの開発プロジェクトのチップの模様)という名前からもわかるように、GRAPEシリーズとかなり似通った命令構成になっている。GRAPEシリーズのプログラミングの経験者であれば、それほど難しくはないという割り切りがあって、こうしたスタイルになったものと考えられる。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")









































