データ統合の課題はデータ仮想化で解決
データ活用の万能ナイフ「CData Virtuality」で、溜めるだけのビッグデータやDWH乱立に訣別を
提供: CData Software Japan

CData Softwareの「CData Virtuality」は企業のデータ統合に最適なデータ仮想化製品。「それはデータウェアハウス(DWH)やレプリケーションを使えばいいのでは?」と思ったユーザーはぜひ記事を読んでいただきたい。溜めているだけのビッグデータ、複数のBIツールやDHWの管理や統合に悩むユーザーにもオススメ。聞いたのは、CData Software Japanテクニカルディレクターの桑島 義行氏だ。

CData Software Japanテクニカルディレクターの桑島 義行氏
現場とデータを最適な形で連携するデータ仮想化
CData Virtualityはエンタープライズグレードのデータ仮想化を実現するソフトウェア。CData Softwareが今年の4月に買収したドイツのData Virtuality GmbHの製品がベースになっており、買収後は大文字の「C」を追加し、CData VirtualityとしてCData製品のポートフォリオに統合している。
これまでCData Softwareはデータのレプリケーションを行なう「CData Sync」、B2B連携をノーコードで自動化できる「CData Arc」、セルフサービスでデータ接続を行なう「CData Connect Cloud」などを展開してきたが、今回紹介する「CData Virtuality」はエンタープライズグレードのデータ仮想化を実現する。まずはデータ仮想化について説明してもらおう。
データ仮想化は、元のデータソースから物理的なデータのコピーを行なわず、論理的にデータを統合するという技術を指す。データソースからデータウェアハウス(DWH)などにデータ自体をコピーするCData Syncと異なり、データソースから仮想的にデータベースを構成するのがCData Virtualityになる。
データ仮想化の概念は古くから存在していたが、実装していたのは、データベースからレポートを生成するためのBIツール側だった。BIツールにはデータベースに登録されているデータ項目と、レポートで利用するためのビジネス表現をマッピングした「セマンティックレイヤー」が実装されていたわけだ。しかし、BIツールやアプリケーションが増えてくると、当然これらを共通化した方がよいというアイデアにつながり、論理的なデータモデルを構成できるCData Virtualityのような製品が出てきたという経緯だ。
もう1つは元データが複製され続けることへのアンチテーゼだ。データの複製には、エンジニアが作ったジョブが必要になり、ストレージコストも消費される。複製である限り、必ずタイムラグは生じるし、コピーが加工され続けるのは管理やセキュリティの観点でもリスクは大きい。もちろんレプリケーション自体のメリットもあり、CData SoftwareもCData Syncという製品を持っているが、それだけではカバーできないニーズが存在する。これを埋める新たな選択肢がCData Virtualityだ。
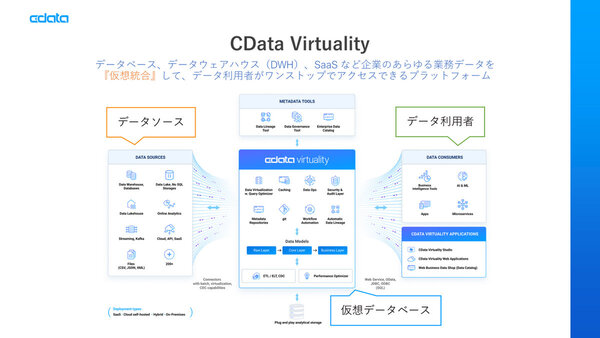
業務データを仮想統合するCData Virtuality
仮想DBならリアルタイムにデータを取得でき、ジョブの生成や管理も不要
データ仮想化のメリットはリアルタイムなデータアクセスが可能になることだ。「データをコピーするわけではないので、つねに鮮度の高いデータにアクセスできる」と桑島氏は語る。また、データをコピーするわけではないので、データストアのコストやジョブにかかる時間を削減でき、規制や要件の変化などにも柔軟に対応できる。さらに、複数データソースへのアクセスを統合できるので、データガバナンスやセキュリティにも寄与するという。
一方でユースケースによっては考慮すべき点もある。あくまで仮想化しているだけなので、データの履歴を追うことはできない。履歴や保管のためには別途DWHが必要だ。また、リアルタイムにソースデータにアクセスするため、大量のデータを取得する場合は、レスポンスタイムも必要になるし、ソースとなるシステムにも負荷がかかる。
こうした特徴を考慮したCData Virtualityのユースケースの1つ目は、ETLとDWHに代わるデータ統合だ。今までは、SaaSやデータベースからETLを介して、DWHにデータを統合するのが一般的だったが、これをCData Virtualityによる仮想データベースに置き換える。仮想データベースにはいわゆるメタデータやテーブルのフィールド情報のみを持ち、データはリアルタイムに参照すればよい。
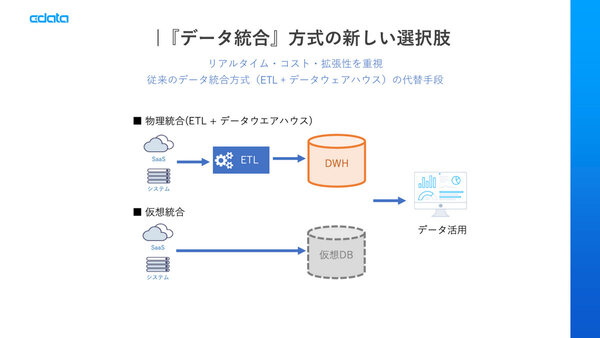
データ統合の新しい選択肢
2つ目のユースケースは、BIやアプリケーション開発の効率化だ。DWHがない企業の場合、複数のデータソースにアクセスするBIやアプリケーションの開発はコストと手間のかかる作業になる。その点、CData Virtualityでは複数ソースのデータを仮想化し、単一のデータアクセスポイントに統合することができる。
用意されたデータアクセスポイントでは、ODBCやJDBC、REST APIなど異なるインターフェイス、セマンティックレイヤーを提供するほか、アクセスコントロールや証跡、秘匿化、バージョン管理などのデータガバナンスなどの機能も備わっている。こうしたリッチなデータアクセスポイントを統合すれば、BIツールやアプリケーションの開発生産性を向上させることができる。
3つ目のユースケースは、複数のDWHの統合だ。「大企業になるとすでにDWHは持っている。しかも営業部門向けDWH、センサーデータを集めたDWH、買収した企業のDWHなど複数あるんです。プロダクトも、クラウドならAmazon RedshiftやAzure DWH、オンプレミスならTeradata、Oracleなどさまざまです。これらのデータを統一して見たいというときに、『じゃあDWHのDWHを作るのか』、という話になるんです」と桑島氏は語る。その点、CData Virtualityを使えば、複数DWHのデータを仮想化し、統一的な環境で利用できるわけだ。
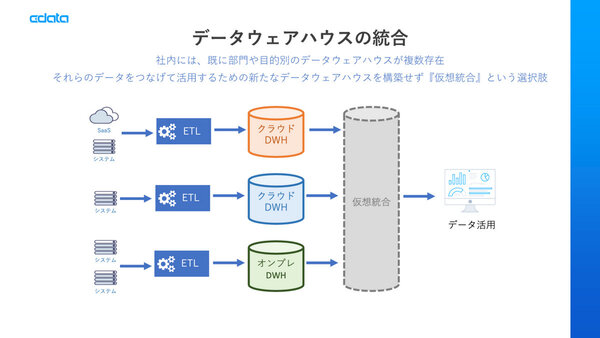
複数のDWHの統合にデータ仮想化
圧倒的数の対応データソース、複製にも対応、費用対効果の高さ
データ仮想化は、すでにDenodo、TIBCO、IBMなどのベンダーが製品を提供している。これらの製品に比べた競合ポイントとしては、なんといっても対応するデータソースの数だ。「CDataはそもそもデータコネクター屋ですから、つながるデータソースは圧倒的に多いです。買収時でも100程度だったが、統合後はすごいスピードで対応データソースを増やしています」と桑島氏。CRM&ERP、コラボレーション、マーケティング、アカウンティングなどのSaaS、RDBMSやNoSQLなどのデータベース、各種ファイル、APIまで対応データソースは200を超える。
2つ目のポイントは、論理データ統合と物理データ統合の両方を実現できるハイブリッドなプラットフォームになっている点だ。仮想化のみならず、データ複製であるレプリケーション(ETL/ELT)の機能も包含しているため、特徴にあわせて使い分けることができる。「複製に関してはCData Syncをおすすめしているのですが、仮想化しながら、履歴データもとらなければならない場合は、CData Virtualityでカバーできます」(桑島氏)。
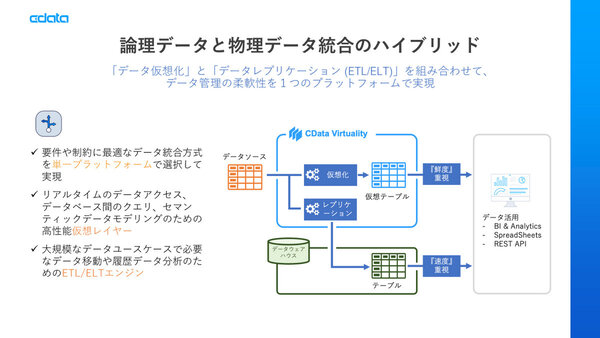
論理データ統合も、物理データ統合も
3つ目は費用対効果の高さと管理の容易さ。まずSaaS、オンプレミス、ホスティングなどの運用形態が選べる上、AIを用いた最適化やデータ仮想化の弱点とされるクエリの遅さを補うインメモリキャッシングのエンジンも含まれる。また、利用に関してもセルフサービスやオートメーションなどが利用できるだけでなく、すべての操作を手続き型のSQLコマンドで実行することも可能なので、あらゆる専門家が利用しやすいという。
エンタープライズグレードで重視されるセキュリティについても、ISO 27001、SOC 2 Type II、SOC 3認証、GDPRおよびHIPAAに準拠するほか、さまざまな認証・セキュリティプロトコルをサポート。データガバナンスも重視しており、堅牢できめ細やかなユーザーのアクセス管理、データの変換を追跡し、履歴や使用状況を管理するデータリネージ、列レベルマスキングでの機密データの保護、メタデータの詳細な履歴管理など充実した機能を持っている。
データ統合に必要な機能が「本当に」1つのプラットフォームに統合
具体的な利用イメージを見てみよう。まずはGUIの画面から接続するデータソースを選択する。前述した通り、200以上のデータソースがあるので、接続先を選択。認証情報を登録すると、接続先のスキーマが見えるので、SQL開発者向けの「コードエディタ」でクエリを生成すればよい。スクリプトのスケジューリング、履歴の表示、ファイルのインポート、CSVのエキスポートなどもこの画面から行なえる。
また、ビューエディタを利用すると、異なるデータベースのテーブルから取得したデータを結合し、独自のビューを作成できる。「MySQLに顧客データ、PostgreSQLに注文データが入っているような場合は、両者のデータから顧客の注文ビューを作ることができます。BIツールやスプレッドシートからこのビューに対してリクエストを行なうと、その時点で最新のデータを取得するという流れになります」(桑島氏)。
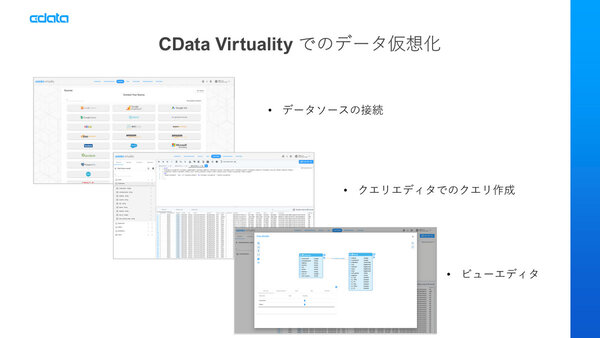
CData Virtualityの画面
ただ、データ仮想化という仕組み上、リクエストのために毎回データソースにアクセスするため、データソースの負荷は重くなる。それを回避する施策として、分析用のストレジ(Analytical Storage)に実態を持った「マテリアライズドテーブル」と呼ばれるキャッシュを作成できる。「パフォーマンスを重視する場合はマテリアライズドテーブルを作成し、リアルタイム性を重視する場合は直接データソースにアクセスするという方法を選択できます」(桑島氏)。また、前述したレプリケーション機能も実装しており、いわゆる洗い替え、増分、履歴、アップサートなどのモードで、データ自体をコピーすることも可能だ。
ExcelやBIツールなどでデータを利用するエンドユーザーに向けては、組織内にあるデータ資産を包括的に表示する「ビジネスデータショップ」というデータアクセスポータルが提供できる。「ExcelやCSV、TableauやPower BIのレポートファイルをそのままダウンロードし、可視化できます」(桑島氏)。データリネージもここから扱えるので、エンドユーザーからも見たいデータの生成元や経緯を追うことが可能だ。Webインターフェイスだけではなく、デスクトップツールの「CData Virtuality Studio」も用意されている。
ビッグデータを単なるストレージコスト消費のための存在にしていくのか?
取材で感じたCData Virtualityの魅力は、やはりデータ統合に必要な機能がワンプラットフォームとして提供されているという点だ。多種多様なサービスとつなげるインターフェイスやセマンティックレイヤーを統合するデータ仮想化に加え、履歴をとるための物理複製機能、最適化やレスポンス向上のためのエンジン、セキュリティやデータガバナンス、ユーザーを選ばないエディターやツールなど、今まで別のツールで提供されていた機能がすべて1つに統合されている。
せっかくのビッグデータも、そこから価値が得られなければ、単にストレージコストを消費するだけの存在に過ぎなくなる。一方で、BIツールやAIに活用しやすいようデータを整備し、データガバナンスを強化していくのは、データカンパニーになるためには避けて通れない作業だ。その点、必要な機能をすべて取りそろえたCData Virtualityはデータ統合のための万能ナイフとして期待できる。複数のデータソースやDWHの統合、AI-Readyなデータ生成などに悩んでいる企業にとっては、かなり強力なツールになるのではないだろうか?
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この記事の編集者は以下の記事もオススメしています
-
デジタル
早くも日本市場に投入 サイロ化したデータアクセスの課題を解消する「CData Virtuality」 -
デジタル
データ仮想化プラットフォーム「CData Virtuality」をインストールしてみよう(SaaS版) -
デジタル
データ仮想化プラットフォーム「CData Virtuality」をインストールしてみよう(Windows版) -
デジタル
データ仮想化ソリューション「CData Virtuality」、日本リージョン対応で本格展開 -
sponsored
複数クラウドの契約管理の悩み セーフィーはSnowflakeとCData Syncで乗り越えた -
デジタル
データ仮想化ソリューション「CData Virtuality」新版、ロール別のUI制御でガバナンス強化 -
デジタル
データ仮想化ソリューション「CData Virtuality」、大規模利用時のリソース管理を強化 -
デジタル
Google Analystics 4のデータをBIツールやMA・CRMと直接連携させる -
デジタル
GoogleスプシからDr.Sumへ ゼロETLでデータをインポートする -
デジタル
イベント管理SaaSとBIがノーコードで連携できると、参加者動向がガッツリ分析できて便利 -
デジタル
kintoneのデータをSaaS・DBと仮想統合 CData Virtualityが“日本市場向け”アップデート -
デジタル
BIツール「MotionBoard」とデータ仮想化基盤「CData Virtuality」が連携開始 -
デジタル
セキュリティ・ガバナンスを強化したCData Virtualityのアップデート -
デジタル
あらゆる業務データの活用をAIに任せる CDataからコネクタ群の「MCP Server」が登場 -
デジタル
「CData Virtuality」統合後初のメジャーアップデート UI刷新でより使いやすく