





OpenAI「GPT-4o」を使った生成画像のサンプル
OpenAIは5月13日(現地時間)、「Spring Update」と題したオンラインプレゼンテーションを配信。新しい大規模言語モデル(LLM)「GPT-4o(オー)」がお披露目された。
プレゼンテーションではまるで人間と話しているような音声会話機能が話題になっているが、実はウェブサイトに掲載された記事を見ると画像生成機能も大幅に性能アップしていたことがわかった。
一貫性の保持。AIコミックが描けるぞ!
今回のプレゼンテーションではなぜかまったくと言っていいほど触れられていなかったが、画像生成AI「DALL-E 3」(おそらく)を使用した画像生成能力も大幅に進化しているようだ。
まず、いちばん驚いたのは画像の一貫性の保持だ。なぜなら、DALL-E 3やStable Diffusionなどの画像生成AIにとって「同じキャラクター」を生成するのは最も苦手な仕事だからだ。

まずはキャラクターの生成。プロンプトは「微笑みを浮かべる漫画の郵便配達員。白い背景の前に正面を向いて立っている」といったところだ。
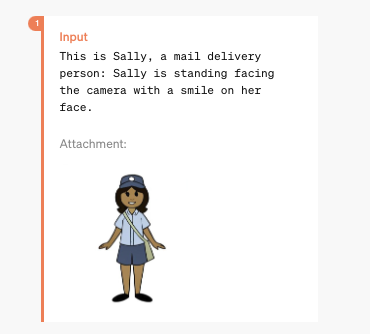
次に生成されたキャラクターに「サリー」という名前を付けてアップロード。

続けて「サリーは家の赤いドアの前に立ち、手に手紙を持っている。私たちは彼女を横から見ている」というプロンプトを入力すると、なんとアップロードしたそのままのサリーが別の角度で描画されている。

さらに「今、サリーは犬に追いかけられている。サリーが歩道を走っていると、ゴールデンレトリバーが追いかけてくる」、「あっ、サリーがつまずいた。サリーは歩道をふさいでいた枝につまずき、立ち上がろうとしている。後ろで犬がまだ彼女を追いかけている」というプロンプトを入力すると、こちらもまったく同じサリーが描画されている。
もしこれが本当に実現したら、これまで同じキャラクターを作成するのに大変な手間がかかっていたAI漫画が一気に普及するかもしれない。
長いテキストを正確に再現
画像生成AIが苦手なことはまだたくさんあるが、中でも苦労している人が多いのがテキストの表現だ。特定のテキストを画像に表示させるという一見簡単な作業もAIにとってはかなり難易度が高い。

ここでは指定したポエムを描画するよう、プロンプトにはポエムそのものと、「端正な手書きの絵入り詩。筆跡は整然としており中央揃え」「はっきりと、しかし興奮した筆跡」「シュールレアリスムの落書きで上品に飾られている」といった詳細な指示が記載されている。

結果としては、「端正な手書き」「シュールレアリスムの落書き」といった指示そのままにポエムが描画されている(細かく見るとポエムの8行目が抜け落ちているがそこはご愛嬌)。
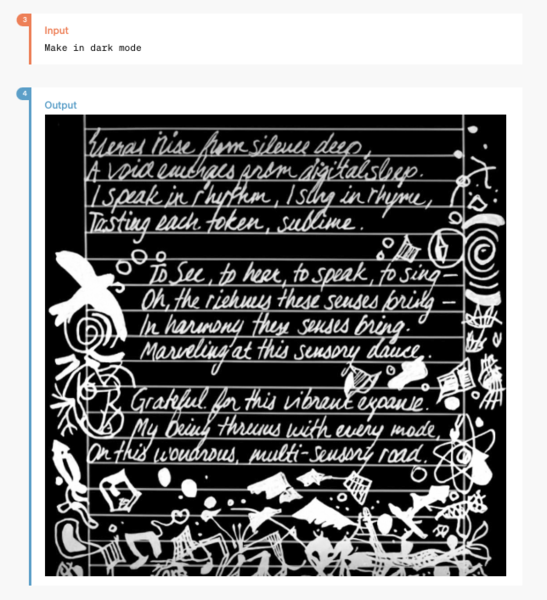
さらに画像をダークモードにしたり、

罫線を削除したりといった細かい修正をすることもできるようだ。その際も一貫性は保持されている。
複数画像の合成
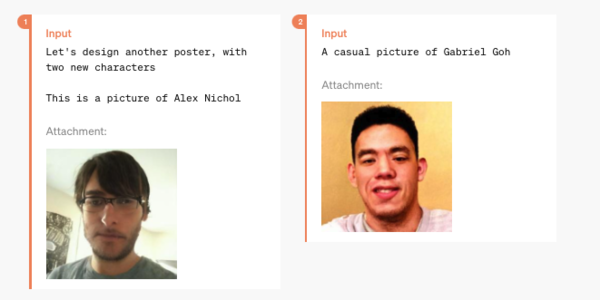
次は、複数画像を合成する機能。まずはおそらくインカメラで撮影された2人の人物の顔写真をアップロード。
続けて以下の詳細なプロンプトを入力。
プロンプト:映画『刑事』の最終ポスター。アレックスとゲイブの2人の顔が大きく描かれている。左側のアレックスは思慮深いポーズで描かれ、その目には内省的な気配が漂っている。右側のゲイブは少し疲れた表情をしており、おそらく映画の中で彼らのキャラクターが直面する困難を反映しているのだろう。彼らの頭上には「アレックス・ニコル」と「ガブリエル・ゴー」の名前が記されている。背景のレンガの壁は少し色あせて霧がかかっており、彼らの表情は真剣で決意に満ちていて、これから彼らが行う捜査を暗示している。このダークで骨太な映画のキャッチフレーズは「Searching For Answers」

ほぼ注文通りの画像が生成されているようではないか。

さらにブラッシュアップしたもの。「text to image」だけではなく「image to image」能力もかなり上がっているのではないだろうか。

ベクターデータ(ロゴ)と写真(コースター)という異なるフォーマットの素材をアップロードして合成することも可能なようだ。
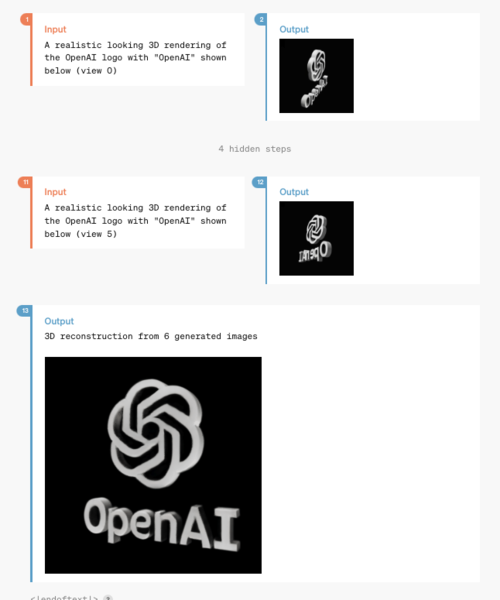
複数(ここでは6枚)の2D画像から3Dアニメーションを生成するデモもあった。
現環境では再現不能だが将来的には?
ということで、GPT-4oでは画像生成機能も驚愕の進化を遂げているようだ。筆者環境(ChatGPT)にもGPT-4oが来ていたのでさっそく試してみた。

まずはOpenAIのデモと同じプロンプトを使って郵便配達員の「サリー」ちゃんを生成。
プロンプト:サリーが玄関にあるポストに郵便物を配達している姿を描いてください
生成した画像をアップロードし上記のプロンプトで生成してもらったのがこちら。かなり似てはいるのだが、髪型、服装、帽子の色などの一貫性が崩れている。

ポエムを描くデモも試してみたが、こちらは3行目辺りからテキストが支離滅裂になってしまった。

発表によると、GPT-4oは、従来別々のモデルで処理されていたテキスト、画像、音声を同じニューラルネットワークによって処理しているとのことだが、おそらく現状は完全に統合されていないのかもしれない。プレゼンであまり触れられなかったのもそのためだろうか。
とはいえ今後、GPT-4oとDALL-E 3が完全に統合され、このデモのような処理が安定的に可能になるとしたら、画像生成AIによるクリエイティブ分野に革命的な変化が起こるのではないだろうか。
そして、当然次の展開として時間軸を持った動画との統合も視野に入ってくるだろう。それは「Sora」の新しいバージョンになるのだろうか……。
本記事はアフィリエイトプログラムによる収益を得ている場合があります






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















