



生成AIでデータ探索を支援する「セマンティック・オートメーション」は2024年中旬に正式版
「watsonx.data」のデータストア・AIデータベースとしての実力は? IBMが説明
2024年05月08日 08時00分更新

日本IBMは、2024年4月26日、AI・データプラットフォームである「IBM watsonx」の主要コンポーネントのひとつである「watsonx.data」に関する勉強会を開催した。
watsonx.dataは、AIとデータ活用を促進するためのデータプラットフォームであり、2023年7月からソフトウェア、およびAWS、IBM Cloudのマネージドサービスとして展開されている。同製品は、大きく別けて2つの顔を持つ。
ひとつは、“データストア”としての側面である。情報系インフラにおいて切っても切れない、コストとパフォーマンスの課題を解決するレイクハウス・アーキテクチャーで構築されていることが、watsonx.dataの価値だという。
もうひとつが、AIを活用するための、AIが組み込まれた“AIデータベース”としての側面だ。生成AIのアウトプットにおける信頼性を担保する「ベクトルデータベース」、生成AIを用いたデータの意味付けと検索強化によってデータ活用を支援する「セマンティック・オートメーション」を備える。

watsonx.dataはデータストアとAIデータベースの2つの顔を持つ
日本IBMのテクノロジー事業本部 Data and AI製品統括部長である四元菜つみ氏は、watsonx.dataについて、「ユーザーが抱えている課題を解決するだけではなく、AIのような新たなテクノロジーを簡単に使える、もしくは意識せずともメリットを享受できるというコンセプトを体現するデータプラットフォーム」と説明する。

勉強会では日本IBM テクノロジー事業本部 Data and AI製品統括部長 四元菜つみ氏(左上)およびテクノロジー事業本部 watsonx製品主幹 張重陽氏(右上)、テクノロジー事業本部 テクニカル・スペシャリスト 丹羽輝明氏(下)が登壇した
クエリエンジンをワークロード毎に選択することでコスト最適化
データストアとしてのwatsonx.dataの特徴については、日本IBMのテクノロジー事業本部 watsonx製品主幹である張重陽氏が説明した。
データ基盤のテクノロジーは進化を続けてきており、90年代後半のデータウェアハウスの登場から、ビッグデータ活用のためのデータレイク、クラウド化に伴うオブジェクトストレージ利用の流行などを経て、データウェアハウスのパフォーマンスとデータレイクのコスト効率や柔軟性を組み合わせた「レイクハウス」の誕生へと至っている。
一方でレイクハウスにも課題がある。業務要件のワークロードを適切に選ぶ仕組みがなく、結果的にBIやMLなどの断片的な利用にとどまってしまう。なおかつ、クラウドが進化している中で、オンプレミスやハイブリッド環境などでの柔軟な運用ができず、ガバナンスやメタデータ機能もないため、幅広いユーザーに展開するには不安を抱える。

レイクハウスの現状と課題
これらの課題を解決するのが、次世代のレイクハウス・アーキテクチャーを搭載したwatsonx.dataだという。クエリエンジンや稼働環境の選択肢を用意し、ガバナンス機能も提供。データレイクで集中管理し、ワークロードに適したクエリエンジンを選択することで、コストの最適化につなげられる。
watsonx.dataのアーキテクチャーは、データを保存するストレージ層、データのメタデータを保持するカタログ層、そしてデータを処理するためのSQLエンジン層の3つの層で構成される。
ストレージ層では、オブジェクトストレージにデータを集約することで、ストレージコストを削減。カタログ層においては、個人情報などの機密データのマスキングやアクセス制御でデータガバナンスを確保し、加えて、メタデータや自然言語処理を用いたデータの即時アクセスを実現する。
そして、watsonx.dataの最も特徴的な点は、SQLエンジン層において、データ活用のワークロードに応じたクエリエンジンが実装され、業務要件に応じて選択できるところだ。

オープンなレイクハウス・アーキテクチャーで構成されるwatsonx.data
例えば、BIダッシュボードでの分析では、リアルタイム処理に優れたデータウェアハウスのエンジンを、BIレポートの参照には、複数のデータソースにアクセスしながら数秒程度のデータ読み込み処理を実現するPrestoを活用する。ETL処理やバッチ処理には、コストと性能のバランスに優れたSparkで最適化する。
「クリティカルな場面では、処理エンジンを性能優先で選び、夜間バッチなどの時間がかかる処理にはコスト優先で選択する。複数のデータウェアハウスを利用して、読み取り処理と書き込み処理が混在する企業では、Sparkエンジンを選択することで、コストを60%圧縮した事例もある」と張氏。
将来的には、ワークロードに対してどのクエリエンジンを選べばよいかAIがリコメンドしてくれる機能も実装予定だ。

ワークロードに応じたクエリエンジンを選択することでコストを最適化
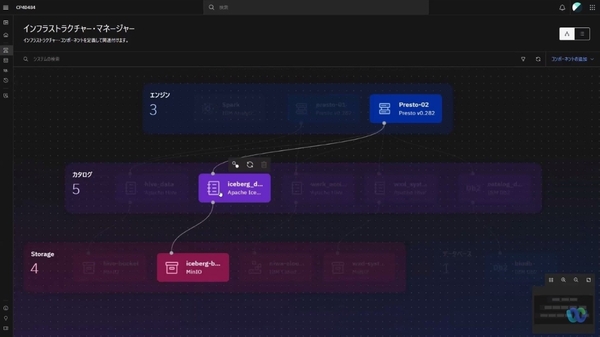
デモ:ワークロードに応じて容易にクエリエンジンを切り替えられる
また、watsonx.dataは、IBM Storage Fusionと組み合わせることで、オンプレミスも含む複数のデータソースを統合した、ハイブリッドクラウド環境を構築することも可能だ。
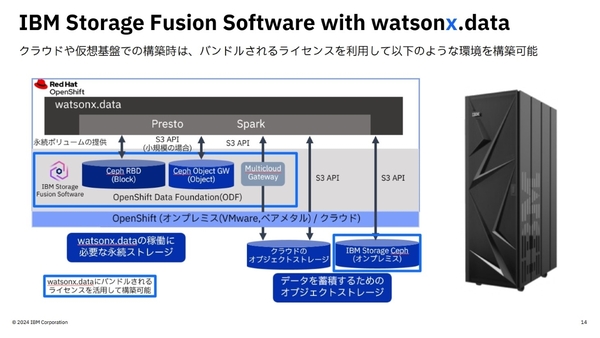
IBM Storage Fusion Software with watsonx.data
ベクトルデータベースである「Milvus」を統合、データ活用の裾野を広げる「セマンティック・オートメーション」も
一方、AIデータベースとしての側面は、日本IBMのテクノロジー事業本部 テクニカル・スペシャリストである丹羽輝明氏が説明した。
現在の生成AIの活用において重要となるのが「ベクトル検索」だ。非構造化データを、データの特徴や関係性を保持しながら、処理できる形で数値に変換(ベクトル化)する。ユーザーの質問やクエリの意味を理解して関連性の高い情報を返すセマンティック検索や、独自データによる根拠付けでハルシネーションを軽減するRAGの構築を実現する。
このベクトル検索を効率的に処理するのに用いられるのが、ベクトルデータベースである。watsonx.dataにおいても、2024年3月より、オープンソースのベクトル専用データベース「Milvus」を組み込んでいる。
Milvusは、クラウドネイティブなベクトルデータベースであり、エンジンとデータが疎結合された設計であるため弾力性が高く、大規模なデータセットに対する高いパフォーマンスを備え、コストを最適化するためのインデックスタイプを豊富に揃えている。また、列フィルタリングやベクトル検索、キーワード検索を組み合わせたハイブリッド検索が可能で、例えば大規模データに対して、検索期間の指定やデータソースの制限をかけることが可能だ。
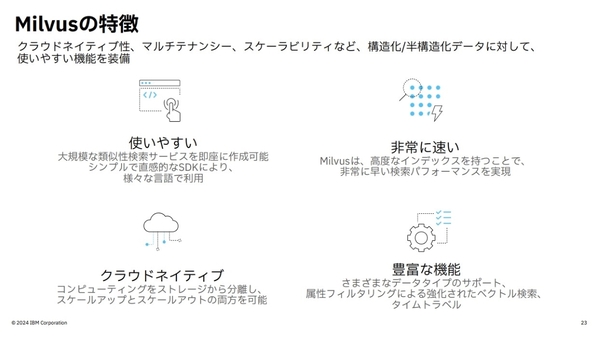
ベクトルデータベース「Milvus」の特徴

非構造化データを基に、自然言語でチームに必要な選手を見つけられる“スカウティング”での事例も紹介された
また、ベクトルデータベースを活かした「セマンティック・オートメーション」というデータ探索を支援する機能を、現在ベータ版で展開している。
同機能では、生成AIを用いて、自然言語による指示でセマンティックにデータ検索することやSQL文を必要とせずにデータ加工ができ、用語の意味やタグ付けなどのメタデータも付与してくれる。これによりデータの検索・取得から、データの結合や加工までを自動で実行でき、データ活用に必要な時間を短縮できる。
「データの所在や結合方法が分からなかったり、専門的なデータへの理解が足りないといった、データ活用において80%の時間を準備に費やしている現状を解消する」と丹波氏。セマンティック・オートメーションは、2024年中旬での一般提供を目指しており、日本語対応も予定している。
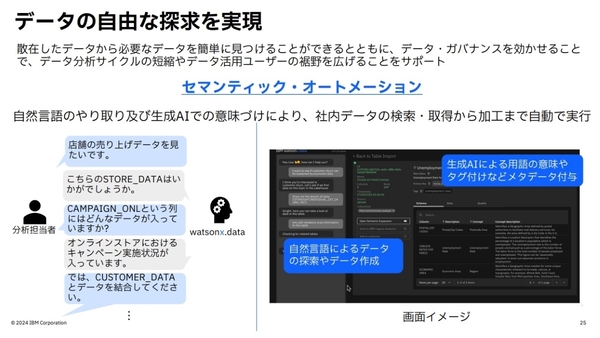
生成AIでデータ探索を支援する「セマンティック・オートメーション」
本記事はアフィリエイトプログラムによる収益を得ている場合があります



