



ロードマップでわかる!当世プロセッサー事情 第685回
メモリーと演算ユニットをほぼ一体化したUntether AIのrunAI200とBoqueria AIプロセッサーの昨今
2022年09月19日 12時00分更新

runAI200を4つ搭載したPCIeカード
TsunAImi(ツナミ)
runAI200は、4チップを搭載したPCIeカードの形で、2 POpsの性能を発揮するとされている。

このカードは“ツナミ”と呼ぶそうだ(ややこじつけがましいが)。文字だけ見てると“ツナィミィ”みたいな発音になりそうなのだが。4つのrunAI200チップの下にMicrochip(旧PLX Technology)のPCIeスイッチが見える。外部にメモリーなどが不要なためか、基板が大変にシンプル
このグラフは純粋にTOPS値を比較したもので実際の性能はまた別だが、実際にResNet-50やBERTの結果では競合製品を大きく上回る性能で、また消費電力あたりの性能で見ても競合の2倍以上の効率としている。
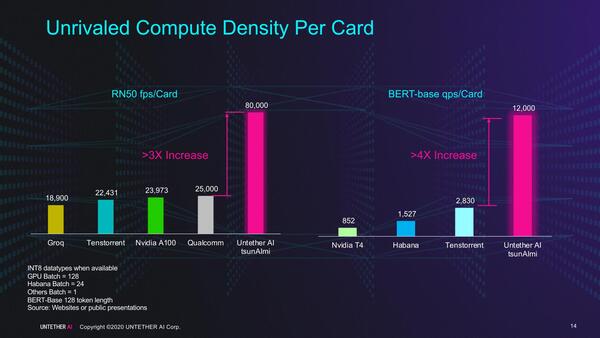
TOPS値を比較したもの。これはカードあたりの性能という比較である
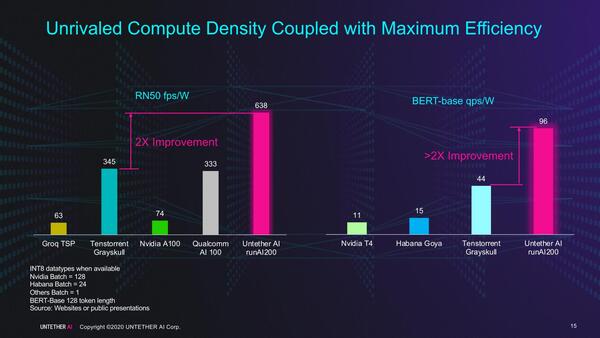
消費電力あたりの性能。この時にはTenstorrentのGrayskullと比較しても2倍の効率、という話であった
2020年10月の段階ではまだサンプル出荷だったrunAI200だが、2021年第1四半期には量産開始ということで、正確な出荷時期は不明ながらすでに購入可能になっている。

消費電力は明らかにされていないが、補助電源が8ピン×1のところから見て、225W程度と思われる。カードの上にはファン用電源コネクターが2つあり、必要ならファンを取り付けての冷却も可能ながら、基本はファンレスでの冷却を前提にしているとみられる
runAI2000の後継
Boqueria(ボケリア)
さてここからが今回の話。runAI2000はINT8で500TOPS(カードは4つ搭載で2000TOPS)だったが、これに続くBoqueriaは、FP8で2PFlops、効率30TFlops/Wを実現する製品となった。
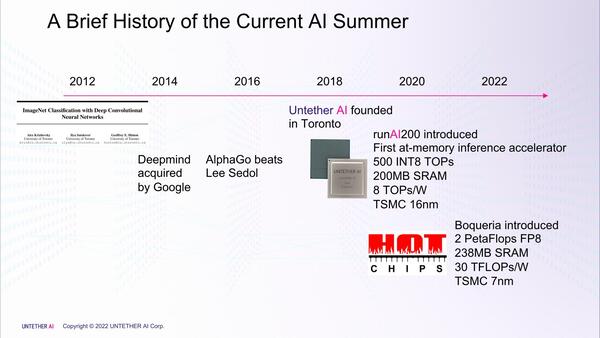
Untether AI社の歴史。2016年までのタイムラインは同社と関係ない気もするのだが……
基本的なアーキテクチャーはrunAI200と変わらないが、メモリーバンク数は27×27の729個に増加され、また外部に1MB×4のキャッシュが追加、さらにLPDDR5メモリーI/Fも搭載された。
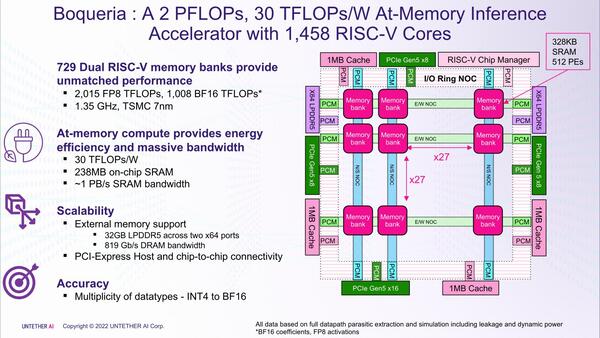
Boqueriaの内部構造。RISC-V云々の話は後述する。RISC-Vコアそのものは実は主役ではない。またrunAI200ではRow/Column Interconnectと呼んでいたものがBoqueriaではE/W(East/West)・N/S(North South) NOC(Network On Chip)に改称されたが、これは名前が変わっただけのようだ
なるべくならメモリーを使いたくないのだろうが、ネットワークの大規模化に対応しようとすると、どうしてもオンチップSRAMだけでは間に合わず、だからといってこれを超えたらPCIeで対応……になると遅くなりすぎるあたり、ある程度妥協したものと考えられる。
個々のメモリーバンクの中身が下の画像だ。runAI200では独自の32bit RISCプロセッサーを使っていたものを、BoqueriaではRISC-Vプロセッサー×2に置き換える形になった。またSRAMアレイも8Bytes×80で640Bytesと大幅増量になっている。
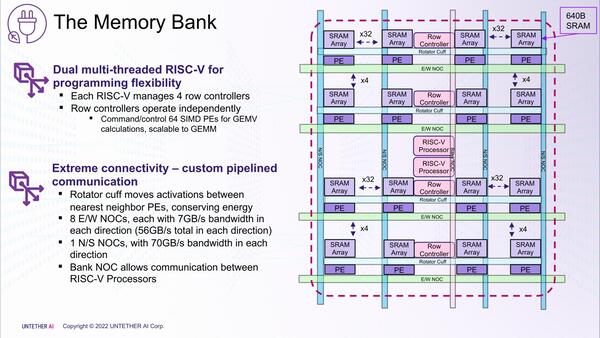
メモリーバンクの中身。N/S方向は同期させてデータを移動しても差し支えない、ということだろうか? このあたりはrunAI200からのフィードバックに基づいたものだろう
あと、おもしろいのはrunAI200ではRow/Columnともにインターコネクトはそれぞれ独立で動作するように記述されているのが、BoqueriaではE/Wは8つでそれぞれ7GB/秒の帯域なのに対し、N/Sは全体で1つとされ、その代わり70GB/秒の帯域となっていることで、このあたり少し振る舞いが変わっているようだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























