




従来のFPGAよりも高速なSpeedster
この初代Speedsterは、冒頭に出てきたpicoPIPEをフルに利用した製品になっている。picoPIPEとはなにか? 例えば一般にFPGAは下図のように複数のロジックを組み合わせる形になるが、その際にロジックとロジックの間にはLatchと呼ばれるバッファが入る。
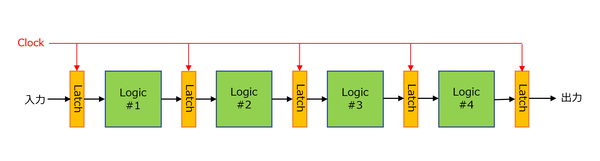
一般のFPGAは複数のロジックを組み合わた形だ。ロジックとロジックの間にはLatchと呼ばれるバッファが入る
このバッファは外部のクロック信号で駆動される格好になるので、仮にLogic #1~#4の処理がものすごく高速であっても、この処理では最低でも5サイクルの所要時間が必要になる。
これに対してSpeedsterでは、入出力の前後にはLatchが入るが、Logic間の接続は独自のpicoPIPEと呼ばれる手法で接続される。このpicoPIPEはクロック信号と無関係に、いわば非同期で伝達を可能とする方法で、この結果としてLogic #1~#4が本当に高速に処理できれば、理論上は2サイクルで処理が完了する。入出力のLatchのみクロック信号に同期するからだ。
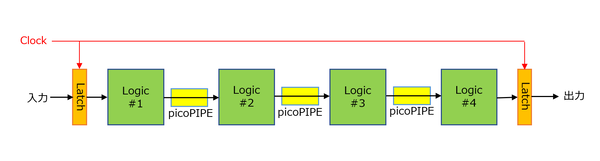
Speedsterでは、入出力の前後にはLatchが入るが、Logic間の接続は独自のpicoPIPEと呼ばれる手法で接続される
内部そのものは普通のCMOSプロセスではあるが、いわば非同期回路が構成できるために、処理次第では従来のFPGAよりもずっと高速に処理できるというのが同社の説明である。実際初代Speedsterシリーズは65nmプロセスでの製造でありながら、1.5GHz相当で動作するというのが当時の説明であった。
その一方でFPGAの容量そのものは大したことがなく、ローエンドのSPD30で24576 LUT、ハイエンドのSPD180でも163840 LUTという構成で、大規模な回路は構成できなかった。ただ「とにかく高速に処理できるFPGAが欲しい」という航空宇宙軍事方面(NASAなどが積極的に採用していたと記憶している)を中心に出荷されていた。
そのAchronix、2010年には次期製品にインテルの22nmプロセスを利用すると発表して一躍有名になった。実際のサンプル出荷開始は2012年8月、量産出荷はその1年後を予定していたものの、実際には2015年2月までずれ込んだ。
しかも当初、高性能向けのSpeedster22i HPと高ロジック密度のSpeedster22i HDの2つがラインナップされており、商品リストもそれぞれ発表されていたにも関わらず、量産出荷開始がアナウンスされたのは高ロジック密度のSpeedster22i HDのみ、というあたりから少し雲行きが怪しくなっていく。

これは2012年当時の画像だが、まだ単に「サンプル出荷を開始」しただけで、“NOW SHIPPING!(出荷中)”はやや気が早いのでは
最大の問題はプロセスであった。下の画像は2015年当時の同社のトップページに掲載されていた画像であるが、この当時はSpeedster22iに続き、引き続きインテルの14/10nmプロセスを使ってより高速化&微細化による大容量化のロードマップが立てられていた。

このメッセージを出したSunit Rikhi氏(当時の肩書はVP、Technology and Manufacturing GroupおよびGM、Custom Foundry)は2015年5月にインテルを離職している
ところがこれ以前の2013年あたりからインテルの14nmが不調という話が出てきており、実際2014年に投入されたBroadwellはノート向けのみ。デスクトップ向けのBroadwell-Sは2015年になんとか出たものの、動作周波数が上がらずにSkylakeにすぐ切り替わる有様だった。
なんとか14nmが安定したのは2016年の14nm+以降で、ところがこれは全量インテルのプロセッサー向けに利用され、カスタム・ファウンドリーに回せる余力はなかった。その次の10nmに至っては現在もまだ不十分という有様で、見切りをつけたのは正解だったのだろう。先に出たeFPGA IPも第2世代に進化したが、こちらはTSMCの16nm/12nm向けに開発されており、これ以上インテルに頼っても無駄と判断したのだろう。
もう1つ、Speedster22i HPが量産されなかったのは、同社の顧客のニーズが変わってきたためと思われる。初代Speedsterは最初に書いたように航空宇宙防衛向けに結構利用されたが、こうしたニーズがSpeedster22i世代ではなくなりつつあったようだ。
それもあり、同社の顧客は(eFPGA IPを別にすると)通信系の顧客ということになった。そうしたこともあってか、2016年にはPCIeのカードにSpeedster22i HDを搭載したAccelerator-6Dカードを発表している。

左のコネクター部にはQSFP+という規格のトランシーバモジュール(40Gbps)を装着し、カード1枚で最大160Mbpsの処理が可能、という構成。DDR3 SODIMM×12で容量192GB、帯域690Gbpsの外部メモリーも利用できる構成である
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























