



IBMデータ&AIビジネスの中核をなすデータプラットフォーム製品、DXの“第二章”に重要な位置づけ
「IBM Cloud Pak for Data」最新版、“DataOps/MLOps”実現も支援
2020年06月16日 07時00分更新

DXの“第二章”では、データやAIにも「継続的デリバリ」の仕組みが必要
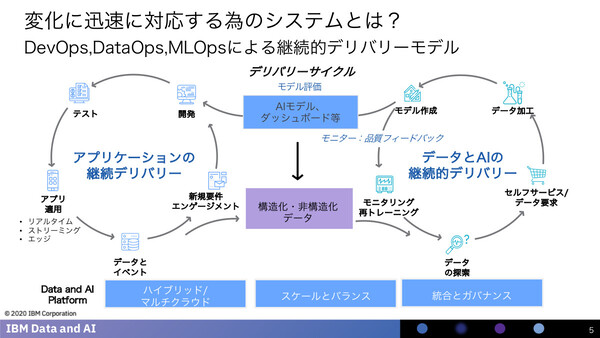
正木氏は、パンデミックの発生など“不確実性”の高まる環境下における経営ではデジタルトランスフォーメーション(DX)が必須であり、特に現在は「デジタルを最初からビジネスプロセスに組み込む」というDXの“第二章”が到来していると語る。そして、この“第二章”において企業ITに求められるのが、「データとAIの継続的デリバリ」の仕組みだと強調する。

DXの実験的な段階だった“第一章”から、本格的なビジネス活用が始まる“第二章”へ
デザイン思考を取り入れ、ユーザー主導型でビジネスやサービスを開発してきた“第一章”では、ユーザーのフィードバックを受けながらアプリケーションの開発とテスト、展開を迅速に繰り返す「アプリケーションの継続的デリバリ」が求められ、多くの企業がDevOpsの考え方を取り入れた。
「ただし、これだけでは“第二章”のアジャイルな経営には対応できない」と正木氏は指摘する。デジタルの本格活用段階である“第二章”では、ビジネスやサービスの創発や改善のためにデータ分析やAIモデル開発が必須となる。そして、それらもまた「試行錯誤」のサイクルを迅速に回す必要があるからだ。そのために、Cloud Pak for Dataのような包括的な機能を備えた統合データプラットフォームが必要になると強調する。
アジャイルなアプリ開発/展開と同様に、データ分析/AIモデル開発もアジャイルに実行し、試行錯誤できる環境が必要だと強調した
“as-a-Service”型提供やエッジ対応、モデルの分散学習など今後の方向性
Cloud Pak for Dataは今後のバージョンでどのように進化していくのか。田中氏は、5月に開催された「IBM Think Digital 2020」で発表された、3つの“進化の方向性”を紹介した。
1つめは、このデータプラットフォームをサービスとして(as-a-Service)提供するというものだ。IBM Cloudをサービス基盤として利用しマルチテナント型で提供するもので、利用量に応じた従量課金型、または期間契約のサブスクリプション型で利用できる。2020年下期からの提供が予定されている。
2つめは、データ分析/AI能力をエッジ環境まで拡張する“Cloud Pak for Data Edge Analytics”である。エッジで収集したデータに基づきクラウドやデータセンターで機械学習モデルを開発、そのモデルを組み込んだAIアプリケーションを開発してエッジに展開するというものだ。AIの推論処理はエッジ端末/エッジゲートウェイ上で実行されるため、低レイテンシでの処理や転送データ量の削減などが実現する。
最後が“Federated Learning”だ。これまでの、エッジ拠点からデータをすべて中央に集約したうえで機械学習トレーニングを行う方式とは異なり、各エッジ拠点でトレーニングを実行し、それぞれの学習済みモデルを中央に集約して1つのモデルに結合するという仕組みだ。
わかりやすい例としては、グローバル企業で各拠点地域から個人情報などのデータが域外に持ち出せない場合に、それぞれの拠点でモデル化したうえで中央に集約するというものがある。そのほか田中氏は、たとえば企業内の部門間やグループ企業間など、データそのものは他組織に開示できないが、全体の知見を集約した統合モデルを開発したい場合などに有益なのではないかと説明した。まさに現在、どのような具体的ユースケースが考えられるか、顧客と議論を重ねている段階だという。
「IBM、特にData and AI事業部としては、このCloud Pak for Dataを中核となる製品だと位置づけている。IBMが“Journey to AI(AIへの道のり)”を顧客に提供していくうえでも非常に重要なコンポーネント。今後も迅速に、多くの機能を取り込んで成長していくので、ぜひ期待いただけたら」(田中氏)



