



HPEの“メモリ主導型コンピューティング”研究プロジェクト「ヨタバイト級も実現可能」
世界最大160TBの単一メモリ空間「The Machine」が実証に成功
2017年05月22日 07時00分更新

米ヒューレット・パッカード・エンタープライズ(HPE)は現地時間5月16日、“メモリ主導型コンピューティング”(Memory-Driven Computing)の実用化を目指す「The Machine」研究プロジェクトにおいて、世界最大の単一メモリ空間を持つコンピューターの実証実験に成功したと発表した。今回の実証により、エクサバイト、ゼタバイト、ヨタバイト級に及ぶ単一メモリプールの実現も可能であることが予想できるとしている。

今回の実証実験で使われた「The Machine」プロトタイプ。40ノードで160TBの単一メモリプールを構成した

「The Machine」プロトタイプを構成するブレード。左半分がコンピュートノード、右半分が共有メモリノードで、各々が独立して動作する
HPEでは、近い将来に予想される「『ムーアの法則』の終焉」と「生成されるデータ量の指数関数的な増加」に備え、「巨大かつ複雑なデータの瞬時での分析」というニーズに対応するために、半世紀以上大きな変化のない従来の“プロセッサ中心型アーキテクチャ”からのパラダイムシフトとなる“メモリ主導型アーキテクチャ”の実用化を目指している。その研究プロジェクトがThe Machineだ。
The Machineでは、大容量の不揮発性メモリ(NVM)を搭載した多数のメモリノードを高速なファブリックで接続し、巨大な共有メモリプールを構成する。この共有メモリプールを複数のコンピューティングノードが参照し、データを処理するという仕組みだ。従来のキャッシュ/メインメモリ/ストレージというティアをなくす「ユニバーサルメモリ」、メモリファブリックだけでなくノード間、ノード内部のバスにまで適用される「フォトニクス(光通信)」、汎用的なx86だけでなくGPU、DSPなど個々のワークロードに適した「SoC(System on a Chip)」が利用可能、といった技術的な特徴がある(詳細な解説は下記関連記事を参照されたい)。
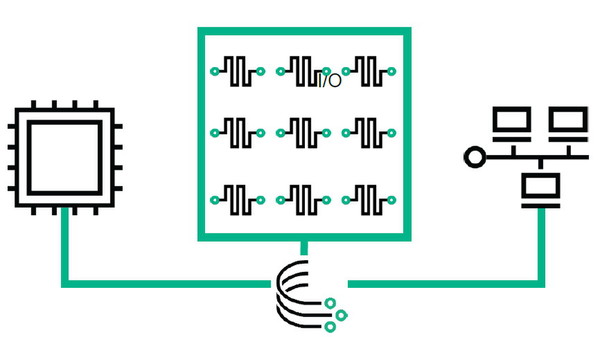
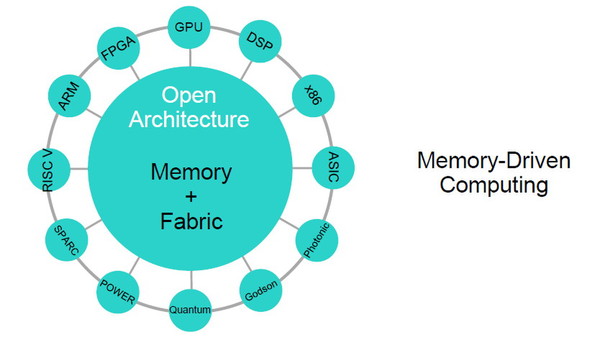
メモリを中心に据える「メモリ主導型アーキテクチャ」のノード構成(左)。クラスタ構成の場合、共有メモリプールを中心にプロセッサ(コンピュートノード)が“ぶら下がる”形になる(右)
The Machineプロジェクトでは、すでに昨年段階でプロトタイプ機を完成させていた。今回の実証実験は、そのプロトタイプ機で技術改良を重ね、実際に大規模な単一メモリ空間を構成したものとなる。
具体的には、40台の物理ノードを高速なファブリックプロトコルで相互接続し、160TBの共有メモリプールを構成している。コンピュートノードには、Cavium(カビウム)のARMv8-A SoCである「ThunderX2」を搭載し、メモリ主導型アーキテクチャに最適化されたLinuxベースのOSが動作する。アプリケーション開発のためのプログラミングツール(SDK)も用意されている。
HPE発表によると、160TBの単一メモリ空間は「米国会図書館が所蔵する全書籍の5倍にあたる、約1億6,000万冊の本に書かれているデータを同時に処理できる」規模のものであり、これまではこのような巨大データを単一メモリシステム内で保持/操作することは不可能だった。
さらにHPEでは、今回の実証によって、エクサバイト(ペタバイトの1000倍)規模の単一メモリシステム、さらには4096ヨタバイト(ヨタバイトはペタバイトの10億倍)のメモリにまで「容易に拡張可能であると予想している」と述べている。なお4096ヨタバイトの規模は、「今日の宇宙全体に存在するデジタルデータ総量の25万倍」だ。
発表の中で、HPEのCTOでありHewlett Packard Labs ディレクターを兼任するマーク・ポッター(Mark Potter)氏は、「本日発表した(メモリ主導型)アーキテクチャは、インテリジェントエッジ機器からスーパーコンピュータまで、すべてのカテゴリーのコンピューティングに応用可能」だと述べている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



