どの商用Webサイトでも、オーガニック検索からの訪問は最重要です。オンラインショッピングの顧客のほぼ半数が、検索エンジンで商品を検索してから買い物を始めていますし、Eコマースのトラフィックの3分の1は検索結果からの訪問です。実店舗を構えている場合でさえ、オーガニック検索の世話になっている可能性が高いのです。なぜなら、モバイルで検索した人の半数は検索から1日以内に店舗を訪れるからです。
結局は1つの事実に行き着きます。Webサイトから収益をあげたいなら、オーガニック検索からの訪問客が必要だということです。ではどうやって訪問客を得ればよいでしょうか。それは、SEO(検索エンジン最適化)です。
SEOは通常、マーケッターやライターの範疇だと思われています。しかし、開発者にも果たすべき大きな役割があります。もし、サイトが正しく作られていなければ、検索エンジンはページを見つけてインデックスを付けるのに苦労したり、あるいは、まったくできないかもしれません。たとえば、たった1つのrobots.txtファイルの誤った移動で、サイトのすべてがGoogle検索結果から消えてしまう可能性だってあるのです。
開発者が検索結果の上位表示に最適な手法でサイトを作る手助けになればと思い、9項目のチェックリストをまとめました。
クローラーの巡回とインデックス
1. 検索エンジンにサイトを知らせる
SEOの目的はターゲット顧客の検索結果にサイトを表示させることなので、サイトを作る際に一番大切な配慮は、サイトがクローラーに巡回されインデックスされるようにすることです。インデックスされるために一番簡単な方法はGoogleとBingに自分のサイトを直接知らせることです。GoogleサーチコンソールのサイトURLの送信を使いましょう。Googleサーチコンソールのアカウントは必要ありませんが、もし持っているなら、クロールのセクションでFetch as Googleツールが使えます。Googleのボットが無事にサイトを見つけたら、「Submit to index(インデックスに送信)」ボタンを押してください。

Bingにサイトを送信するにはBing Web マスター ツールのアカウントが必要です。
2. XMLサイトマップ
基本的なXMLサイトマップの記述は、サイトのルートフォルダーにテキスト形式で保存された、サイト内のすべてのURLのリストです。実際にはそれだけではありません。XMLサイトマップには、確かにサイト内のすべてのURL、または、少なくともクローラーにインデックスさせたいURLが並んでいますが、同時に、SEOで重要な各ページの追加情報も記載されています。検索エンジンはサイトマップの情報を使って、重要ではない、もしくは変更がないコンテンツに立ち寄ることなく、インテリジェントかつ効率的にサイトを巡回するのです。XMLサイトマップを正しく記述した基本的なサイトマップは、次のようになります。
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xhtml="http://www.w3.org/1999/html">
<url>
<loc>https://www.example.com/</loc>
<lastmod>2016-8-01</lastmod>
<changefreq>monthly</changefreq>
<priority>0.9</priority>
<xhtml:link rel="alternate" hreflang="fr" href="https://www.example.com/fr/"/>
</url>
上のコードの概要です。
- <urlset>:クローラーに対し、サイトマップの始点と終点を示す
- <url>:サイトマップ内の、各URLの始点と終点を示す
- <loc>:ページのURLを定義する。<url>タグ内のほかの属性は任意だが、<loc>は必須
- <lastmod>:ページの最終更新日をYYYY-MM-DDの形式で表す
- <changefreq>:ページの更新頻度を示し、最新コンテンツをインデックス化するためのクローラー巡回頻度の決定を助ける。偽って巡回頻度を高めたい誘惑にかられるかもしれないが、やめておいたほうがよい。検索エンジンが<changefreq>と実際の更新頻度が一致しないと判断すれば、このパラメーターは単に無視されるだけだからだ
- <priority>:ほかのページと比較したときの、そのページの優先順位を設定する。有効な値は、最小優先度は0.0で最大は1.0。クローラーのサイト巡回をより効率化するために使う。このタグはクローラーに対し、そのページが同じサイトのほかのページに比べてどれだけ重要かを伝えるということに注意。そのページがほかのサイトに比べて重要かどうかには影響しない
- <xhtml:link>:代替ページを示す。上の例は、フランス語版のhttps://www.example.com
サイトマップは直接ランキングを上げる要因ではありませんが、検索エンジンがすべてのページとコンテンツを発見するのを促すことで、サイトのランク向上に役立ちます。
もし自分でサイトマップを書きたくないなら、作成を助けてくれるたくさんのツールが出回っています。XMLサイトマップを作ったら、Googleサーチコンソールで有効化して送信しましょう。同じようにBing Web マスター ツールでBingにも送信できます。サイトのインデックスを妨げないように、エラーがあればすべて修正してください。
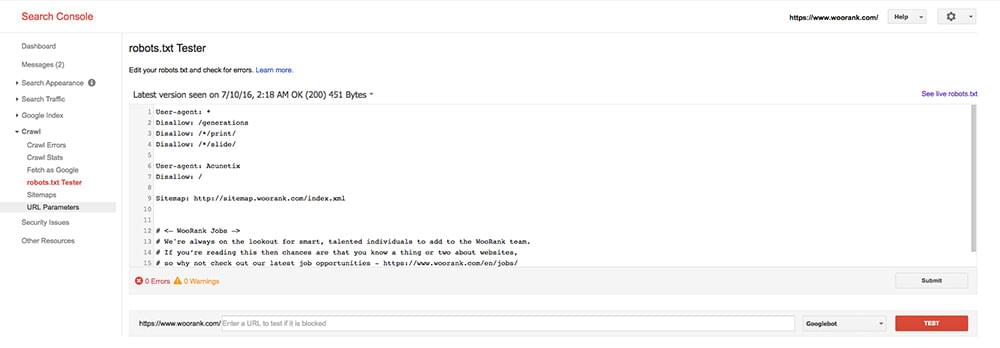
3. Robots.txtファイル
XMLサイトマップと同じく、robots.txtファイルはルートフォルダーに置くプレーンテキスト形式のファイルで、クローラーのサイト巡回を助けます。このファイルには、どのユーザーエージェントがどのファイル、ファイル形式、フォルダーにアクセスできるのかを指定するコードが含まれています。さらにブロックごとに分かれていて、1セクションに1行のユーザーエージェントがあります。基本的なrobots.txtのコードは次のようになります。
User-agent: *
Disallow:
User-agent: googlebot
Disallow: *.ppt$
アスタリスク(*)はワイルドカードを表します。ユーザーエージェント行でワイルドカードを使うと、すべてのボット(クローラー)を表します。disallow行のワイルドカードは特定部分までのURLを表します。上の例ではGooglebotに対して、URL終端がPowerPointファイル拡張子(.ppt)のページの巡回を禁止しています。$記号はURLの終端を表します。
disallow行でスラッシュ(/記号)を使えば、クローラーに対しサイト内すべてを巡回禁止にできます。
User-agent: *
Disallow: /
サイトを作成・改装・移動している間、すべてのクローラーにサーバー全体のアクセスを禁止するのはよい方法です。しかし、いったん作業が終了したら忘れずに指定を元に戻しましょう。そうしないと、せっかくのピカピカの新サイトもインデックスされません。
Googleサーチコンソールで、robots.txtファイルに構文エラーやほかの問題がないかテストしましょう。
■Meta Robotsタグ
robots.txtファイルの問題の1つは、検索エンジンが外部リンクをたどってサイトにアクセスしてくることまでは防げないので、不許可(disallow)にしたページがインデックスされてしまう可能性です。各ページにrobots meta タグを使い、保護をもう1階層追加します。
<meta name="robots" content="noindex">
逆にサイトをインデックスしたい場合は、インデックスさせたいページにrobots meta タグを使わないように気を付けてください。
URLの最適化
4. 優れたURLにする
URLはユーザーエクスペリエンスとSEOの双方で重要です。人間もロボットもURLに、少なくとも何についてのページか、サイト階層のどの部分なのか、といった基本的な情報を求めています。URLに、ページキーワードとフォルダー名とサブフォルダー名を含めることで最適化しましょう。下の2つのURLを見てください。
- https://www.example.com/clothing/mens/shirts/fancy-white-dress-shirt
- https://www.example.com/product/cid=12345&pid=67890
ページを巡回する検索エンジンは、最初のURLでは、おしゃれな白いワイシャツに関係するだけでなく、男性用の衣類に関係したトピックだと判断できます。残念ながら2番目のURLでは、たぶんexample.comの商品だということ以外、ページになにがあるのかほとんど分かりません。「男性用のおしゃれな白いワイシャツ」という検索キーワードに対してどちらが適しているでしょうか。
優れたURLにするためには、以下のことを心がけてください。
- 簡潔:URLにはキーワードを含めるが、簡潔にする。一般的には英字100文字以下
- クリーン:できれば、URLにセッションIDやソート名、フィルター名を含まないようにする。これらは使い勝手を下げるうえ、コンテンツ重複のリスクがある
- ハイフンの使用:URLに複数の単語を使うときは単語をアンダースコア( _ )ではなくハイフン(-)で区切る。検索エンジンはハイフンを単語の区切りと認識するが、アンダースコアは認識しない。たとえば、url_keywordはurlkeywordと同様に認識される。人間は検索時にスペースで単語を区切るので、ハイフンで単語が区切られたURLのほうが適している
5. 正規URL(Canonical URL)
URLの最適化はキーワードをどのように使うかだけではありません。同時に、コンテンツの重複を防ぎ、被リンク効果といったランク付け要因を強化することでもあるのです。URLのパラメーターや同時配信されるコンテンツによって、うっかり複数のページに重複したコンテンツを掲載してしまうことはよくあります。重複ページがよくないだけではなく、パンダアップデートの「ペナルティ」はサイトすべてに及びます。もし使用するコンテンツマネジメントシステム(CMS)やEコマースプラットホームによって重複コンテンツが発生するなら、rel="canonical"属性を使い検索エンジンに対してどれがオリジナルURLかを指定しましょう。
正規URL(Canonical URL)を使うときは、WWWの名前解決から始めます。Googleサーチコンソールのサイトの設定で、優先ドメインを設定します。Googleは優先ドメイン設定を考慮してWebの巡回と検索結果の表示をします。もし、www.example.comを優先ドメインに設定した場合、example.comへのすべてのリンクは、Googleが検索結果ページ(SERP)に表示するサイトwww.example.comに対するリンク効果を発揮します。次にcanonicalタグを、HTMLページなら<head>タグ内、非HTMLページならばHTTPヘッダー内に加えます。
HTML:<link rel="canonical" href="https://www.example.com"/>HTTP:Link <https://www.example.com>; rel="canonical"
canonicalタグを加えるときは絶対に、目当てのURLと正規URLが100%一致するようにしてください。Googleは「http://www.example.com」「https://www.example.com」「example.com」の3つを、それぞれ別のページと認識します。もしもcanonicalリンクを2つ以上のページに使っていたり、エラー404を返すようなページに使った場合は単に無視されます。
ページ読み込み速度
ページ読み込み速度は、ユーザビリティとSEOの両面からとても重要です。Googleはユーザーを最高のWebサイトに導くというのが主旨なので、ユーザーを読み込みの遅いWebサイトに案内したくないのです。もしWooRankを使ってサイトを管理しているなら、ユーザビリティのセクションで自分のサイトの読み込み時間をチェックし、競合と比較してみてください。

6. サイト読み込み速度の最適化
もし、サイトの読み込みが遅いなら、以下の要素を最適化して速度を改善します。
- 画像:画像は、読み込み速度を遅くする原因になる。HTMLは画像の寸法を変更するだけなので、サイズの削減には使えない。サイズを減らすにはPhotoshopをはじめとする画像編集ソフトを使う。さらに画像を圧縮するには、画像最適化ツールの使用を検討する
- 依存性(dependency):プラグインやスクリプト、たとえば、ソーシャルメディアのシェアボタンやトラッキングソフトは、Webサイトを最大限に活用するために必要だ。可能なら常にCMS純正のプラグインを使い、トラッキングシステムは1度に1つだけ使うようにする。CMSのバージョンをアップデートしてもサイトに不具合が発生しないように、アップデートのたびにテストできるテスト環境を用意する
- キャッシュ:ヘッダーでexpiresを指定して、サイトがキャッシュされる時間を調整する。また、ブラウザーに対し、画像、スタイルシート、スクリプト、Flashをキャッシュできることを宣言しておく。HTTPリクエストの数が減ってページ読み込み速度が改善する
- G-Zipエンコード:回線帯域の節約とダウンロード時間の短縮のために、ページ上の大きなファイルはG-Zip圧縮を使って結合・圧縮しておく
- リダイレクト:リダイレクトは避けられないが、リダイレクトは新たなHTTPリクエストを送信するのでミリ秒単位で読み込み時間が延びる
それでもまだ問題があればブラウザーの開発コンソールを開き、ページ読み込みの際にボトルネックとなっているファイルを突き止めましょう。
モバイルフレンドリーであること
7. モバイル用ページの読み込み速度
モバイルフレンドリーであることは、サイトの読み込み速度と直結しています。読み込み時間はモバイルでの検索順位に影響する主要な要因だからです。モバイル用ページの読み込みの速さは、デスクトップ用ページ以上に重要なことは間違いありません。それを裏付ける数字があります。40%のモバイルユーザーは表示まで3秒間待たされるとページを離脱します。Googleによるモバイルフレンドリーの要件は、1秒以下でブラウザーの初期表示領域のコンテンツを表示することです。
モバイルページの読み込み時間は、デスクトップ用サイトと同じ方法で最適化できます。画像サイズを減らし、キャッシュを使用し、依存オブジェクトを減らし、リダイレクトを最小限にするのです。もしくは、AMP(Accelerated Mobile Page)を作ることです。AMPは、高速でユーザーエクスペリエンスに優れたモバイルページを作るための、オープンソースの仕様です。AMPの主な内容は次の3つです。
- HTML:AMPページのためのHTMLは、基本的に普通のHTML。ただし少しだけ、画像、動画、iframe要素といったリソースのカスタム要件と制約がある
- JavaScript:AMPページでは、非同期読み込みのカスタムJavaScriptライブラリーを使う。またHTMLにサイズを記述して、ブラウザーが要素を実際に読み込む前にその外観を把握できるようにする必要がある。これによりほかの要素が読み込まれた際にWebページの表示が飛んだりしなくなる
- キャッシュ:GoogleにはAMPページ専用のキャッシュがあり、検索結果の表示に使用する。AMPキャッシュに保存されたページを表示するときは、すべての要素を同じ場所から読み出すので効率がよくなる
8. モバイルページの構成
モバイル版のページを作るときには、主に3つの選択肢があります:
- モバイル用サブドメイン:サブドメイン(通常はmobile.example.comまたはm.example.comと表示)にまったく別のモバイルサイトを作る方法で、3つの方法のうち一番手間がかかる。Googleにはサブドメインが単なるモバイル版だということが判別できないので、内容が重複するページにはすべてrel="canonical"タグを使わなければならない。ほかの2つ方法より多くのリソースが必要で、通常は推奨されない
- ダイナミックデザイン:ユーザーエージェントを検出し、モバイルとデスクトップのブラウザーに別々のHTMLを提供する。検索エンジンに対して、ユーザーエージェントごとに異なるコードを提供していることを示すためにvary: user-agentHTTPヘッダーを使う(『「もっとSEOを意識して」と言われたときにエンジニアが取り組むこと5つ』参照)。もしPHPで組んでいるなら次コードを加える。
<?php header<"Vary: User-Agent, Accept"); ?>Apacheであれば、以下のコードを.htaccessに加える。
Header append Vary User-AgentWordPressで組んでいるならば、次のコードをfunctions.phpに加える。
function add_vary_header($headers) { $headers['Vary'] = 'User-Agent'; return $headers; } add_filter('wp_headers', 'add_vary_header'); - レスポンシブデザイン:もっともシンプルで簡単にモバイル版サイトを作る方法として、Googleが推奨する方法がレスポンシブデザインだ。単にviewportというmetaタグを使うだけだ。viewportはブラウザーに対して、ページの表示をどのような大きさにすればよいかを指定する。viewportをセットすれば、表示をデバイスの大きさに合わせてページをモバイルフレンドリーにできる。
<meta name="viewport" content="width-device-width, initial-scale=1.0"/>
コンテンツに意味を付加する
9. 構造化データマークアップ
構造化データマークアップは、検索エンジンがコンテンツを理解できるようにするためページ上のコンテンツに意味を付加するものです。たとえば、「About(当社について)」のページにSchema.orgマークアップ記法を使えば、検索エンジンに対して所在地、営業時間、電話番号を示せます。商品ページに使えば、検索エンジンは商品の評価や点数を簡単に見つけられます。もし、個人のサイトがあれば、学歴、家族、職業の情報を示すためにSchemaマークアップを追加してください。
Schema.orgマークアップ記法を使っても、使っていないサイトより必ずしもランクが上がるわけではありません。しかし、Googleのリッチスニペットに使われているためSEOで大きな効果があります。検索スニペットを実際に見る最も簡単な方法は、レシピ検索です。検索結果にはタイトル、URL、説明と一緒に、写真と評価を示す星印があるはずです。写真と評価の表示は、セマンティックマークアップによる効果です。
つまり、セマンティックマークアップはランク付け要因ではありませんが、検索の表示順位の改善に役立つのです。Googleがページ上になにがあるかを理解すればするほど、ランクが上がる可能性が高まります。しかもセマンティックマークアップは、スクリーンリーダーなどの障害者支援ツールを手助けをしますし、サイトのユーザーエクスペリエンス向上にもつながります。
最後に
以上の9項目のほかにも、テクニカルSEOにはいろいろな要素があります(さらに詳しくは『「良質なコンテンツ作り」 と合わせて取り組む!いま必要な内部SEO総まとめ』のチェックリストを参照)。しかし、Googleに発見、インデックスされて検索結果で上位表示されるには、基本があります。テクニカルSEOでとりわけ重要なことは、確実にGoogleがページ上のコンテンツを発見し、巡回し、解釈できるようにすることと、優れたユーザーエクスペリエンスを実現することです。
※本記事はWooRankのSEOシリーズの1つです。SitePointでの記事公開に協力してくれたパートナーへのサポートに感謝します。
(原文:9-Point Technical SEO Checklist for Developers)
[翻訳:西尾健史/編集:Livit]
本記事はアフィリエイトプログラムによる収益を得ている場合があります