




SUPERNUMを変形させたような構成の
GENESIS
そのGENESIS、正確にはGENESIS Version 1のノード構成は下の画像のようになった。1つのノードにCP(Communication Processor)とAP(Application Processor)の2つのi860XPが搭載され、両者はLCI(Local Communication Interface)という専用バスで接続される。

GENESISのノード構成。随分と贅沢な構成である。出典は“The Architecture of the European MIMD Supercomputer GENESIS”
名前の通り計算処理はAPが担い、CPがノード間通信を担うという仕組みだ。NLIはNetwork Link Interfaceでノード間接続を行なう。
また2つのi860XPは共有メモリーバス経由で8MB×4Bank=32MBのメモリーを利用できる。860XPそのものは共有メモリーI/Fなどは持ち合わせていないので、これはGENESIS側で設計・製造したと思われる。
メモリーI/Fは3段のパイプライン構造で、帯域は最大320MB/秒になるとされる。100MFLOPSということは倍精度では理論上800MB秒の帯域が必要になるが、さすがにそこまでは用意できなかったらしい。
このノードのCPにつながるNLIの構造が下の画像である。1つのノードからクロスバスイッチ経由で4本のリンクが出る仕組みになっている。リンク速度は当初は1本あたり50MB/秒とされる。
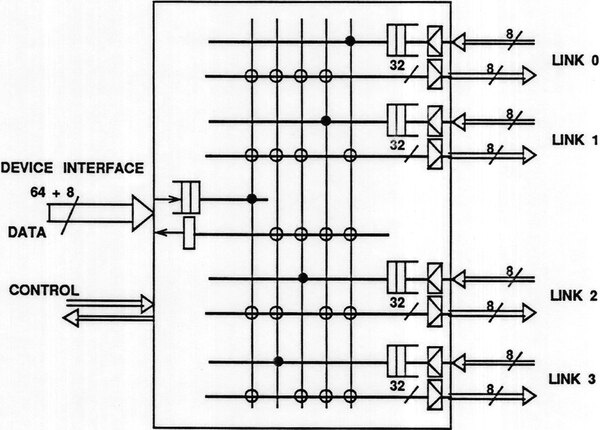
上の画像と左右がひっくり返っており、左のDEVICE INTERFACEがノードのCPに接続される
問題はリンクがノードあたり4本しか出せないことである。1024ノードをターゲットとする場合、HyperCube構造を取るならノードあたり10対20本のリンクを用意する必要があるが、さすがにこれを構成するのはコスト面から非現実的と判断された。
そこでGENESISではSUPERNUMを変形させたような構成とした。まず少数のノードをクロスバスイッチでつなぎ、小さなクラスターを構成。このクラスター同士をさらにインターコネクトでつなぐという2段階の接続方式が採用された。
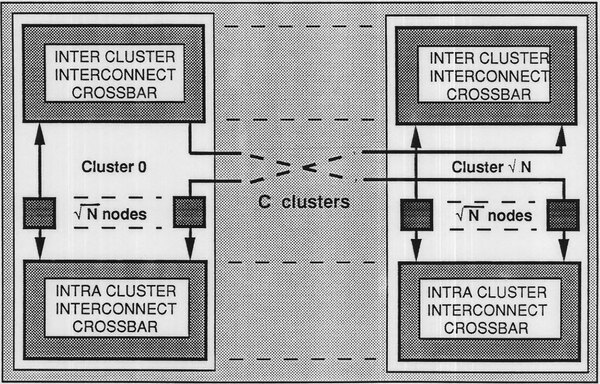
クラスターをインターコネクトでつなぐ2段階の接続方式。下側のCrossbarがクラスター内の接続、上側のCrossbarがクラスター間の接続をそれぞれ担っている
具体的な数字が出てこないのだが、おそらく1クラスターを32ノード構成とし、このクラスターを32個つないで1024ノードを実現する予定だったと思われる。
1つのクラスターには2つのInter-Cluster Crossbarが含まれており、うち1つはクラスター内のノードの接続に、もう1つはクラスター間の接続に利用する方式だ。
ベクトルプロセッサーを追加して
性能向上を計画したVersion 2
ここまでで100GFLOPSのマシンを構築できるメドは立ったことになる。SUPRENUM-1が理論性能で5.12GFLOPSだったから20倍の高速化であるが、さらに性能を上げたVersion 2も予定されていた。
どうやるかというと、これまたSUPRENUM-1と似た、ベクトルFPUの搭載である。下の画像がそのVersion 2でのノード構成だが、新たにベクトルプロセッサーを追加してもう一段ノード性能を上げようというわけだ。
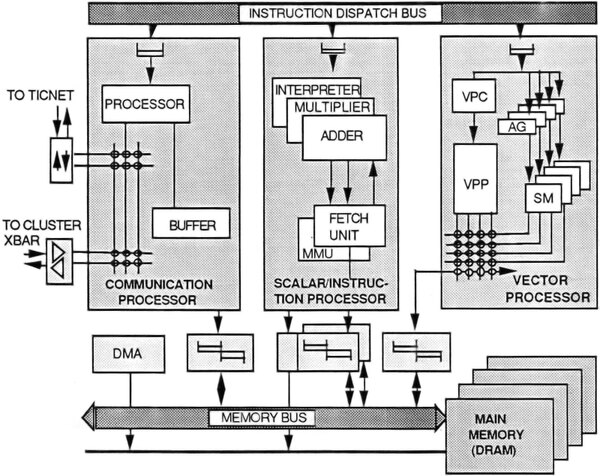
Version 2のノード構成。この構成ではメモリー帯域が不足するのは明白である。これに対する回答だが、論文にも“This will be combined with a large cache size(大容量キャッシュと組み合わせる)”と脳天気に書いてある。仮に実行したとしても、実現は難しかっただろう
このベクトルプロセッサー、採用を考えていたのはBIT(Bipolar Integrated Technology)の提供していたB2110/2120である。
WeitekのFPU同様、B2110が32bitの加算、B2120が32bitの乗算を実行するチップで、この2つを組み合わせて乗加算をスループット1サイクルで実行できた。
B2110/2120を使う場合、さらにB2210というSRAMのレジスターファイルも組み合わせる必要があるので、おそらく搭載される予定だったと思うのだが、さすがにそこまでははっきりしない。
このBITという会社、名前の通りバイポーラベースのFPUを作っている会社で、B2110/2120は同社の初の製品である。ちなみに会社は1983年にオレゴンで設立されたが、設立資金を出したのがFPSとインテル、それにTektronixというあたりからも製品の方向性が見えようというものだ。
その後同社はECLベースのSPARCチップや、ECLベースのMIPS R6000など、とにかく動作周波数を引き上げること「だけ」に専念した製品をいくつかリリースするが、半端ない消費電力もあって商業的には成功せず、最終的に1996年にPMC-Sierraに買収されてしまう。
そのB2110/2120だが、1990年の段階ですでに33MHz動作のチップは存在しており、かつこれを利用したベンチマークソフトも走っていたらしい。同社はB2110/2120を最終的に100MHz以上まで動作周波数を引き上げる計画をこの時点で発表していた。
上の画像のVersion 2のノード構成でもわかるように、このB2110/2120を利用してベクトル長4のベクトルプロセッサーを構築することで、理論上は400MFLOPSが実現できるはずで、これを全ノードに搭載すれば400GFLOPSのマシンができあがる計算になる。なかなか気宇壮大な話である。
→次のページヘ続く (ソフトウェア開発に専念)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































