




新しい外部I/Fで帯域を確保する
NVIDIA
NVIDIAはHPCに関してインテルを捨て、IBMと組むという戦略に出た。もともと同社はARMからアーキテクチャーライセンスを取得し、Project Denverと呼ばれる64bit ARMベースの独自CPUを開発しており、一時期はこれがHPC向けに使われるという噂もあったが、結局Project DenverのコアはTegra K1などのモバイル向けに利用されることになった。
となると、少なくともKnights Landingのようなな解決法を行なうためには手頃なCPUコアがない。またそもそも同社のCUDAがホストベースの構成を前提としたものだったため、いきなり超並列のような構成を取ることはできない。
かといってインテルベースのプラットフォームを使う限り、PCI Expressベースになるから性能がここで頭打ちになる。技術的にはインテルがQPIのI/Fをライセンスしてくれれば、もっと高速で、しかもキャッシュコヒーレンシが利用できることになるが、インテルがこれを公開しない以上どうしようもない。
その一方、IBMは2014年4月にPower8というハイエンドプロセッサーを発表したが、このPower8は外部通信I/Fとしてこれまで利用してきたPCI Expressに代えて独自のCAPI(Coherence Attach Processor Interface)と呼ばれるポートを装備した。
これにあわせてNVIDIAはNVLINKと呼ばれる新しい外部I/Fを発表、Pascalの世代から搭載することを明らかにした。このNVLINKはGPUとホスト、あるいはGPU同士を接続するために利用可能とされ、帯域は80~200GB/秒になるとしている。
これだけ帯域が大きければ、ホストとの同期がボトルネックになる可能性はだいぶ下がることになる。

NVLINKは、CPUと直接接続しメモリー内容などを転送し、CPUとGPUのメモリを統一して扱うユニファイドメモリーを実現する。CPUから直接NVLINKを出力することになるため、現時点では、専用のPowerプロセッサーだけが対応する
HSAをHPC市場に持ち込むつもりの
AMD
さて、ではAMDは?という話である。AMDの場合は、APUの実装を優先した関係で、GPGPUカードとホストの連携はあくまでも通常のPCI Express経由という扱いだったが、Kaveri世代で一応HSAの実装がフルに完了したこともあり、再びHPC市場に目を向けつつある。
IEEEの学会誌の1つであるIEEE MicroのVol 35 Issue 04(2015年7-8月号)は、“Heterogeneous Computing”という特集であるが、ここにAMDは10人もの筆者を集めて“Achieving Exascale Capabilities through Heterogeneous Computing”という記事を掲載している(関連リンク)。
下の画像はその概念図を示したものだが、同社のAPUコア(論文の説明ではARMもしくはx86ベースだそうだ)とGPU、そしてDRAMを全部シリコンインターポーザーに搭載するという形を想定している。要するにRadeon R9 Furyのもっと大規模、そしてCPUコアも載っている版である。
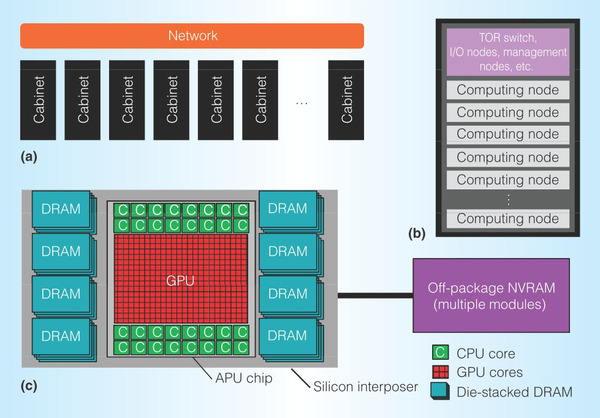
巨大なシリコンインターポーザーの上にAPUとHBM、GPUコアが鎮座するというもの。これを実装するとするとどのくらいのパッケージサイズになると想定しているのか、気になるところだ
もともとAMDがHSAの実装でGPGPUカードのサポートを抜いたのは、PCI Express経由だと遅すぎる上にキャッシュコヒーレンシ性がないからだ。
ところが上の画像のようにシリコンインターポーザー経由にすればもっと高速に接続できるし、キャッシュコヒーレンシの実現も不可能ではない。つまり、現在のAPUをもっと大規模構成にできるというものだ。
発想はインテルのMICアーキテクチャーの方向性に近いが、GPUコアはあくまでもGPUコアでx86が走ったりはせず、ところがHSAの恩恵をフルに生かすことでより高い効率を得られる、と主張しているわけだ。
確かに実装密度で言えば、このほうがMICアーキテクチャーよりも高くなるし、HSAに向けての布石をここ数年努力してきたからソフトウェアの面では移行は難しくない。そんなわけで、AMDはHSAをHPCの市場に持ち込む方向性をとろうとしていることが、ここから見て取れる。
というわけで、簡単に今後のHPC向けのGPGPUの方向性について説明した。とりあえず汎用のGPUカードに似たGPGPUカードが装着される、という光景はここ数年で切り替わりそう、という感じである。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























