



同社最高マーケティング責任者、APACチーフセキュリティテクノロジストに聞く
標的型攻撃/APT対策で急伸、Splunkが語る“次世代SIEM”とは
2015年07月08日 14時00分更新

――その“次世代のSIEM”とはどんなものでしょうか。従来のSIEMとどこが違うのですか。
パン氏:従来型のSIEMは、セキュリティログ「だけ」を取り込んでいた。つまり、多数のセキュリティ製品から発せられる大量のアラートから、重要度の高いものを抽出し、見落とさないようにすることが主な目的になっていた。
しかし、長期潜伏型の高度な攻撃であるAPTの場合、セキュリティログには何の痕跡も残さないことが多い。APTに対抗するためには、それ以外の一般的なログ、たとえばEメールやWebアクセス、DNS、顧客が自社開発したアプリケーションなどのログも合わせて取り込み、データを分析していく必要がある。具体的には、脅威インテリジェンス/ネットワーク/アプリケーション/エンドポイントという、4階層のデータが必要になる。
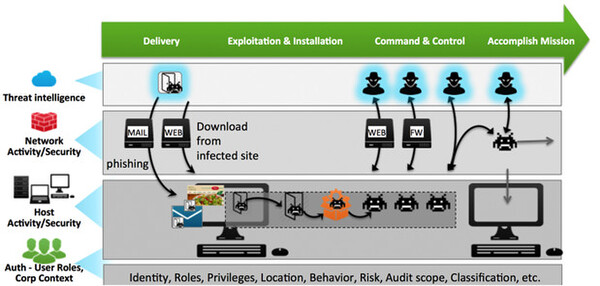
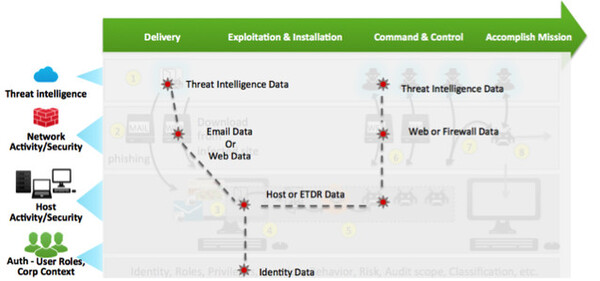
一般的なAPTは、1:組織への侵入、2:組織内での感染拡大、3:外部からの攻撃指示、4:攻撃(機密情報窃取など)の実行といった流れで実行される(左図)。セキュリティログだけでなく、EメールやWebアクセス、エンドポイントなどのログも合わせて分析しないと、攻撃の全体像は見えてこない(右図)
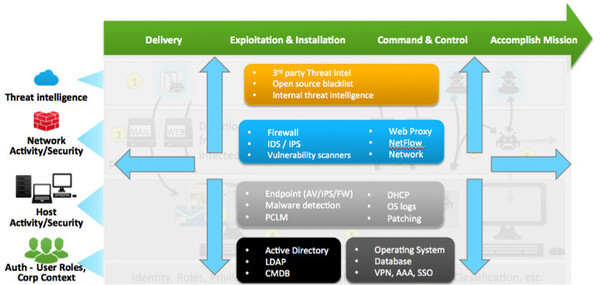
そのため、APT対策を成功させるためには「4つの階層」において情報を収集し、それらを統合したうえで分析する必要があるとパン氏は説明した
また、一見正常に見えるログでも、ビッグデータとマシンラーニング(機械学習)の活用によって「異常」が見えてくることがある。これにサードパーティからの脅威インテリジェンス情報も組み合わせることで、潜伏する脅威も発見できるわけだ。
マシンラーニングを活用、多様なログから「異変」を見つける
――マシンラーニングの技術は、Splunkの中で具体的にどう活用されているのですか。
パン氏:マシンラーニングを活用することで、あらゆるデータにおいて「アノマリー(不正値)」の検出が容易になる。
たとえばSIEMが、社内PCからWebへのアクセスログをチェックしているとしよう。通常時のアクセス先URLの長さは1000文字未満だが、あるとき急に9000文字に伸びる。SIEMはこの異常を検知して、アラートを出す。実は、マルウェアに感染したPCから、ふつうのWebアクセスに見せかけて重要なデータが送信されていたというわけだ。
ここで、マシンラーニング技術を備えていない旧来のSIEMならば、あらかじめ設定された「しきい値」を基準に異常を判断することになる。しかし、それはとても難しい。なぜなら、個々の顧客環境における「通常時の値」をベンダーは知らないからだ。顧客の管理者自身でしきい値を設定するとしても、膨大な種類のデータ一つひとつに対して「正常な値」を決めていくのは難しく、大きな手間がかかる。
一方、Splunkでは、平常時に取り込まれた大量のデータをマシンラーニングで解析し、最大/最小値や平均値、標準偏差などを自動的に“学習”する。これにより、顧客が独自開発したアプリケーションのログなど、どんなデータであっても「正常な値」を解析し、何らかの異変の発生を容易に検出できるわけだ。

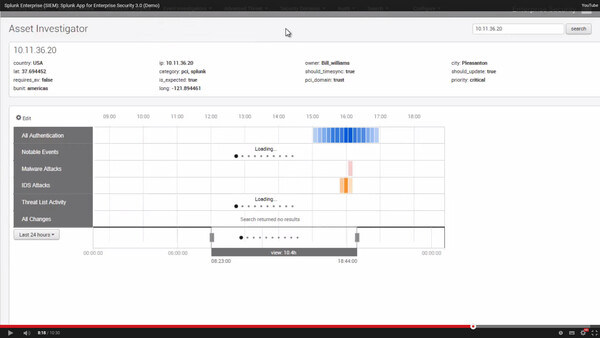
アノマリー分析なども活用しながら、不審な通信を発見し、端末ごとの詳細なアクティビティまでドリルダウンしていくことができる(デモビデオより)
――Splunkのセキュリティソリューションを導入している海外の企業や組織の事例を教えてください。
パン氏:Splunk App for Enterprise Securityの顧客は、グローバルでおよそ4000社/組織いる。その多くが、セキュリティベンダーの従来型製品からSplunkへと乗り換えた顧客だ。
たとえば株式市場のNASDAQ、金融機関のBank of AmericaなどがSplunkのセキュリティソリューションを採用している。また、ハニーネットやボットネットの研究のために、SymantecやSophosといったセキュリティベンダーもSplunkを活用している。サムスンも、Splunkを使ってグローバルセキュリティのモニタリングを行っている。
ソマー氏:導入の目的はAPT対策だけではない。オンラインショップなどのサイトで、違法行為や不正行為を検出するためにSplunkを採用されているケースもある。たとえばオンラインバンキングのサイトで、1つのIPアドレスから何百何千もの口座へのアクセスがあれば、それをアカウント乗っ取りとして自動的に検出できる。
ほぼすべての主要セキュリティベンダー製品と連携できるSplunkは、セキュリティシステムの“頭脳”として動作する。さまざまなセキュリティ製品からログデータを取得し、そうした製品に高度なインテリジェンスを与えるというわけだ。



