メンヘラテクノロジーの高桑蘭佳です。今回は何か特別な背景があるわけではなく、ただただ純粋に自分自身の作業効率を上げるためのツールを作成してみました。その様子を紹介できればと思います!
強いて言うならば、私自身はちょっとした作業を自動化することが日常的にあり、最近RPA(ロボティック・プロセス・オートメーション)のような文脈の中で社内・チーム内で頻繁に繰り返す単純作業を自動化した際に、自分以外でも使えるように環境を整えることは意外と大事なことだと感じました。
私たちはスタートアップでリソースもまったくない状態ではあるので、社内ツールの開発をリッチにできる余裕など存在しません。しかし、今回初めてPySimpleGUIを使ってみたところ、単純に自分の作業環境を改善するくらいの実装コストで、良い感じのGUIツールが作成できたので、今後も積極的に使っていきたいと思いました。
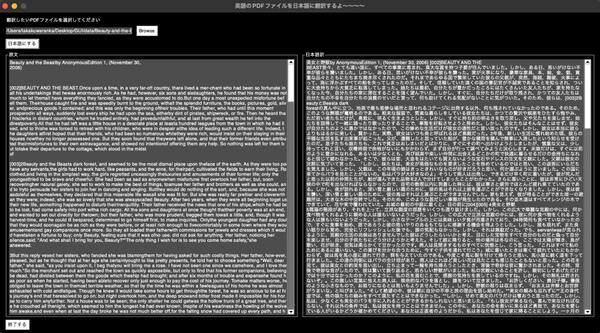
今回作成したのはタイトルの通り、英語のPDFファイルを日本語に翻訳するGUIツールです。もともとPDFファイルからテキストを抽出し、翻訳ツールを使って日本語に翻訳するところまでは自動化していました。しかし、PDFのファイルのパスを都度指定して、吐き出された日本語のテキストファイルを開きにいく……ということすら面倒くさくなってしまい、GUI化できたらとても楽そう〜! と思い、作ってみることにしました。
英語のPDFファイルを日本語に翻訳する
英語のPDFファイルを日本語に翻訳する部分については軽く紹介できればと思います。今回、PDFファイルからのテキスト抽出には「pdfminer.six」というライブラリ、翻訳には「DeepL API」(クライアントライブラリ「deepl」)を使用しました。
DeepL APIについてはアカウントを作成し、クレジットカード情報を登録した後、事前準備として認証キーを発行します。
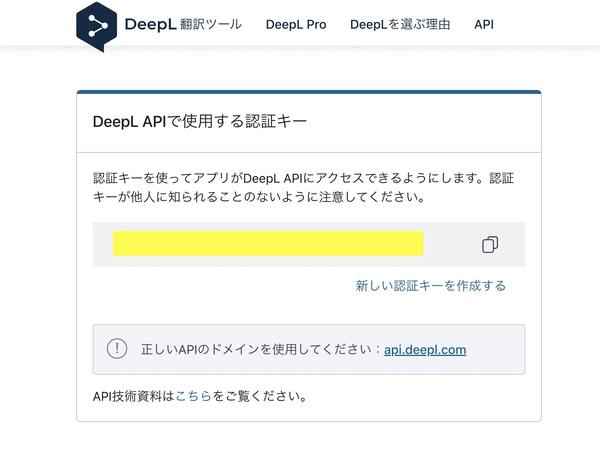
DeepLの認証キーは「dotenv」というライブラリを使用して.envファイルで管理します。作成した.envファイルはメインのプログラムと同じディレクトリに保存します。
# .env
DeepL_API_KEY = ‘(認証キー)’
以下、PDFファイルからテキストを抽出する関数です。
# guitool.py
from pdfminer.high_level import extract_text
def pdf_to_text(pdf_path): #引数:PDFファイルのパス
docs = extract_text(pdf_path) #pdfファイルからテキストを抽出
en_docs = docs.replace('\n', '') #テキストから改行コードを削除
return en_docs
以下、DeepL APIを使用して、英語のテキストを日本語に翻訳する関数です。
# guitool.py
import deepl
from dotenv import load_dotenv
import os
def translate(en_docs):
load_dotenv('.env') #.envファイルの値を環境変数に追加
API_KEY = os.environ.get('DeepL_API_KEY') #認証キーの読み込み
translator = deepl.Translator(API_KEY) #認証キーを設定
jp_docs = translator.translate_text(en_docs, source_lang='EN', target_lang='JA') #翻訳の実行
return jp_docs
この連載の記事
- 第345回 順調なのに不安 その違和感、実は“次のサイン”です
- 第343回 メディアアート再燃?「TOKYO PROTOTYPE」に人が殺到した理由
- 第342回 休職中の同僚を「ずるい」と思ってしまうあなたへ
- 第341回 3Dモデルを必死にリギングした結果、「AIが優秀すぎる」ことに気づいた
- 第340回 VRChatでロボットになりたい筆者、最終的にBlenderを選んだ理由
- 第339回 復職が不安なあなたへ。“戻らない復職”を私が選んだ理由
- 第338回 DJをやってみようと思い立った
- 第337回 「子どもを預けて働く罪悪感が消えない」働く母親の悩みに答えます
- 第336回 ChatGPT、Gemini、Claude──特徴が異なるAI、どう使い分ける?
- 第335回 100点を目指さない勇気。家庭と仕事、両立時代のキャリア戦略
- この連載の一覧へ