



企業内の暗黙知=“秘伝のタレ”をAIエージェント化する「H.D.E.E.N」プラットフォームも
オンプレミス導入向け日本語LLM「リコーLLM 27B」発表 Dify搭載サーバーと組み合わせ販売
2026年01月09日 17時10分更新

リコーが、小型の日本語LLM(大規模言語モデル)として新たに開発した「リコーLLM 27B」を発表した。「オンプレミス環境への導入に最適な高性能LLM」と位置づけており、エフサステクノロジーズが提供するオンプレミス環境向け対話型生成AI基盤「Private AI Platform on PRIMERGY(Very Smallモデル)」に搭載。生成AI開発プラットフォーム「Dify(ディフィ)」をインストールし、LLMの動作環境を構築した上で、リコージャパンを通じて販売する。

今回発表の「リコーLLM 27B」を加えたリコーLLMのラインアップ

エフサステクノロジーズの「Private AI Platform on PRIMERGY(Very Smallモデル)」と組み合わせ、オンプレミス環境向けの生成AIソリューションとして提供する
半分以下のパラメータ数で、従来を上回る性能を実現した新たなLLM
リコーLLM 27Bは、Googleのオープンモデル「Gemma 3 27B」をベースに開発された270億パラメータのLLMで、リコー独自のモデルマージ技術を活用することで、ベースモデルから大幅な性能向上を実現しているのが特徴だ。独自開発を含む約1万5000件のインストラクションチューニングデータによって追加学習したInstructモデルから抽出したChat Vectorなど、複数のChat Vectorを統合。OpenAIのgpt-oss-20bをはじめとする、同規模のパラメータ数を持つ最先端LLMと同等の性能を発揮するという。
リコー AIサービス事業本部でデジタル技術開発センター所長を務める鈴木剛氏は、「これまでに開発した『リコーLLM 70B』の半分以下のパラメータ数で、それを上回る性能を実現した。非思考モデルながら、思考モデルに匹敵する推論性能を実現している。とくに執筆能力が高く、Time to First Token(TTFT)が速いため、チャットなどでの利用に適している」と説明する。
270億パラメータのモデルであることから、「NVIDIA L4」のような入手しやすいGPUでも稼働させることでき、消費電力も下がる。これにより、オンプレミスでの動作環境が容易に構築できるという。
また、AIサービス事業本部 AI事業開発センター所長の児玉哲氏は、Private AI Platform on PRIMERGYに搭載して提供することで、「ハードウェア価格を、3分の1から4分の1程度、抑えることが可能だ。タワー型のサーバー筐体なので、オフィスの足元に置いてLLMを稼働させることもでき、個人情報などの機微なデータを活用する際にも適している。IT部門の管理とは別に運用したいというニーズにも対応する」と紹介した。

リコー リコーデジタルサービスビジネスユニット AIサービス事業本部長の梅津良昭氏


リコー リコーデジタルサービスビジネスユニット AIサービス事業本部 デジタル技術開発センター所長の鈴木剛氏、同事業本部 AI事業開発センター所長の児玉哲氏
企業ごとの暗黙知=“秘伝のタレ”をエージェント化する新たなAI基盤も
リコーでは、AI開発に1980年代から取り組んできた。これまで、独自のOCR技術の開発や、画像とテキストを融合した検索技術の開発などで実績を持つ。2015年以降は、外観検査向けAIや与信判断向けAI、路面性状検査システムなどのほか、自然言語処理AIにより企業内のテキストデータを活用する「仕事のAI」を製品化。営業活動を支援するバーチャルヒューマンも開発した。
生成AI/LLMについても、国内企業としては早い段階で開発に着手していた。2023年3月の「リコーLLM 6B」を皮切りに、2024年1月にはLlama 2ベースの「リコーLLM 13B」、2024年9月にはLlama 3ベースの「リコーLLM 70B」を開発。2025年4月には、このリコーLLM 70BやSwallow、Llamaを統合し、顧客モデルを最適化する技術を確立している。2025年10月には、GPT-5と同等の性能を持つ日本語大規模言語モデルを開発。さらに、図表も読むことが可能な“LMM”(マルチモーダル大規模言語モデル)の開発は、GENIACで採択され、2025年7月から無償公開を行っている。
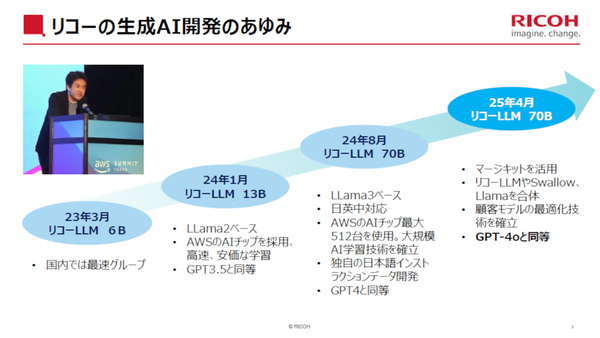
リコーにおける生成AI/LLM開発の歩み
リコーでは今回、前述した新たなLLMに加えて、“秘伝”を意味する「H.D.E.E.N」という新たなプラットフォーム(仮称)を発表している。これは「Hidden Deep Expertise Engine Nexus」の頭文字をとったもので、「企業特化型LLM」「ドキュメント活用基盤」「マルチAIエージェント活用基盤」を組み合わせたパッケージとして提供する。
同社 AIサービス事業本部長の梅津良昭氏は、「この『秘伝のタレプラットフォーム』は、秘められた(Hidden)深層の専門知識(Deep Expertise)を活用するシステムの中核を担うことになる。企業ごとに特化した知識を持つエージェントが、ユーザーの質問意図を理解して、様々な企業情報から、自律的に最適な回答を導く仕組みを構築できる」と説明する。
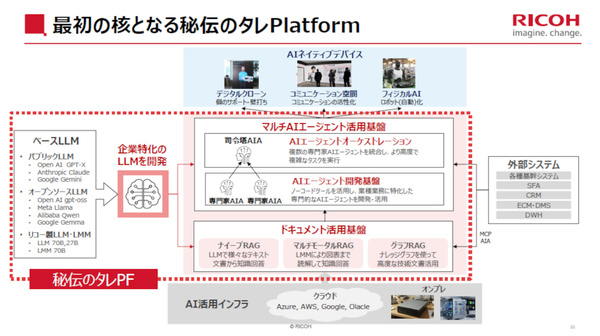
「H.D.E.E.N」(ヒデン、仮称)プラットフォームの全体像
H.D.E.E.Nプラットフォームでは、ベースLLM(パブリックLLMやオープンソースLLM、リコー製LLM)を基に個別企業に特化したLLMを開発する環境、テキスト/マルチモーダル/グラフRAGを組み込んだ「ドキュメント活用基盤」を用意。その上で、業種/業務に特化した専門知識を持つAIエージェントの開発基盤と、複数のAIエージェントを統合管理し、より高度なタスクを実行するためのAIエージェントオーケストレーションで構成される「マルチAIエージェント活用基盤」を提供する。開発したAIエージェントは、MCPなどを通じて外部システムとの連携も可能だ。
これにより、“デジタルクローン”を活用した壁打ちや、複数のAIエージェントをひとつの空間に同居させてコミュニケーションを活性化させるコミュニケーション空間の提供、ロボットとの連携によるフィジカルAIの活用などにつなげることができるという。
「社員がAIに問い合わせると、司令塔AIエージェントが、問い合わせの意図を踏まえて最適な専門家AIエージェントを自律的に判断し、タスクを指示。専門家AIエージェントは、ナイーブRAG、マルチモーダルRAG、グラフRAGといった最新RAG技術を駆使して、多様な現場ドキュメントをナレッジ化したなかから最適な回答を行う。様々なRAGを統合していることで、秘伝のタレのAI化が可能になる」(梅津氏)
リコー社内ではすでにこのH.D.E.E.Nプラットフォームを活用しており、500部門が開発したおよそ6000もの専門家AIエージェントを利用できる環境が整っているという。
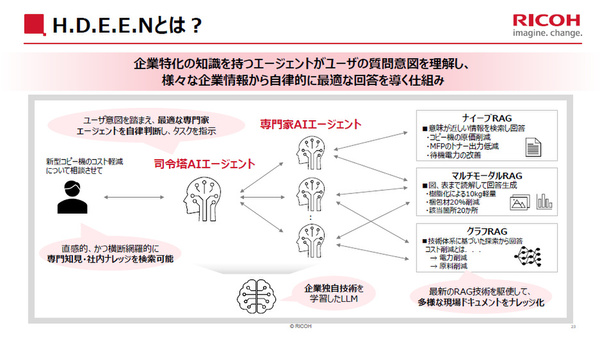
企業特化型の専門知識を持つ複数のエージェントと複数種のRAGを組み合わせ、ユーザーの質問意図に沿った最適な回答を導く
多くの企業が悩む“社内の暗黙知”の活用を後押しする
リコーに対しては現在、国内企業からAI活用に関する問い合わせが増加している。
なかでも多いのが、社内に蓄積した膨大な「暗黙知」の活用に関するものだという。梅津氏は、「企業内には“企業ノウハウの塊”である日報や提案書といった資料があるものの、再利用が進んでいない」と指摘する。企業が持つデータの約70~90%が非構造化データであること、ベテランが持つ暗黙知がデジタル化されていないことが背景にある。
「“秘伝のタレ”とも言える属人化された暗黙知を、活用可能な資産として利用するには、秘伝のタレをAI化していくことが大切だ。AIとデータを掛け合わせることで『知識爆発』と『技智融合』が可能になる」(梅津氏)
こうした「秘伝のタレのAI化」を進めるために、リコーでは、プライベートLLMやRAGを活用して散在する現場知見を形式知化する「技術基盤の構築」、ローコード開発によるAI市民開発文化の浸透や、AIエージェントによる個別業務の自動化を促進する「文化醸成」、バーチャルヒューマンによるコミュニケーション活性空間を実現する「交流活性」、エッジ=ロボティクス連携によるブルーカラー領域へのAI波及で実現する「生産革新」という4つのステップを提案していくという。
梅津氏は、「企業の秘伝のタレをAI化するために、マルチエージェンティックRAG環境を開発し、複数のAIエージェントを統制。さらに、プライベートLLMによって、企業ごとに最適化し、業界知見や専門用語を正確に解釈し、回答することができるようにした」と語った。
「リコーでは、オフィスのなかでも、工場のなかでも“つまらない仕事”はAIやロボット任せて、人は創造性を発揮できる仕事に集中できるようにすることを目指している。『つまらない仕事はもうやらない』がリコーからのメッセージだ。その第一歩が、現場にあるドキュントを読解し、知識化すること。これが、秘伝のタレのAIを実現するH.D.E.E.Nの役割だ」(梅津氏)



