





ChatGPTで生成
OpenAIは12月16日、ChatGPTの画像生成機能「ChatGPT Images」を新モデルに更新したと発表した。ChatGPTユーザー全員が利用できる。あわせてAPIでも新モデル「GPT-Image-1.5」として提供開始している。API料金は、前世代の「GPT-Image-1」より20%安い。
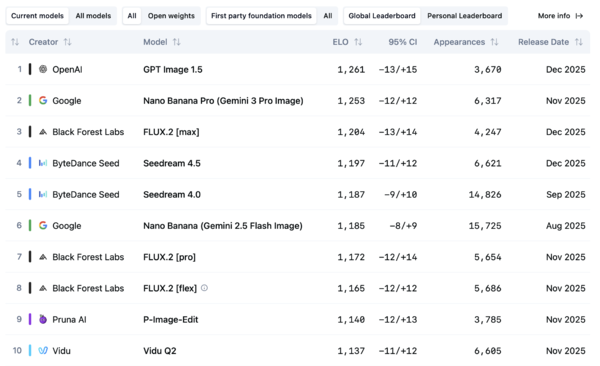
AI比較サイトArtificial Analysisでは、画像編集リーダーボードのEloレーティングにおいて、競合にあたるGoogle DeepMindの「Nano Banana Pro」や、Black Forest Labsの「FLUX.2 [max]」を抑えて首位を獲得している。
新モデルは、生成速度と編集精度の両立が特徴。生成速度は公称値としては最大4倍速くなったという。画像編集では、指示した部分だけを変える精度を高めた。照明や構図、人物の見た目などの要素を保ったまま編集ができる。衣服や髪型はもちろん、画像のタッチやスタイル、概念的な部分なども柔軟に編集できる。複数の画像を組み合わせ、1つの画像に合成することも可能だ。

OpenAIの公式作例。男性の画像が2枚、犬の画像を1枚を入力画像に指定

“子供の誕生日パーティーで退屈しているように見える2000年代のフィルムカメラスタイルの写真で、2人の男性と犬を組み合わせて”

“背景で混沌とした子供たちが物を投げたり叫んだりしている”

“左側の男性を手描きのレトロなアニメスタイルに、犬をぬいぐるみスタイルに変え、右側の男性と背景の風景をそのままにして”
テキストレンダリングの精度も向上した。小さく密度の高い文字を含むレイアウト表現が改善し、インフォグラフィックや“紙面っぽい”表現などができるようになった。プロンプトへの追従性も向上し、6×6のマスに指定のイラストを配置するなど複雑な指定にも対応するようになった。

クラッシックハリウッド映画ポスター風の例。グレッグ・ブロックマン主演作「コーデックス」(フィールAGIピクチャーズ提供)

6×6のグリッドにそれぞれ指定の画像を配置した例
また、ChatGPTのサイドバーに新たに画像生成用の専用スペースを設け、プリセットのスタイルやトレンド系のプロンプト例を見せるように工夫している。
ただし、OpenAIでは新モデルの限界についても言及している。新モデルは旧モデルに比べて広範なケースで改善は確認できたものの、出力は依然として不完全で、将来の反復で改善すべき余地が大きいと説明している。
たとえば、深海生物のポスターのような複雑なビジュアルでは、表現の鮮明さや構図は向上したものの、科学的に正確とは言い切れない部分がある。多数の人物が写る場面や、複数の顔を同時に扱うケース、スタイルの厳密な一貫性、多言語表現などでは制約が残るとしている。
実際、Nano Banana Proが得意とするインフォグラフィックや漫画表現において、GPT-Image-1.5は日本語の不備が目立つ結果となる。ユーザーの意図や文脈は理解しているものの、まだ正確さを欠く部分が残っているようだ。

ChatGPTで生成
OpenAIは今回の更新を「意味のある前進」としつつも、今後はより細かな編集や、言語をまたいだ表現力、さらに自然で詳細な出力へと進化させていく考えだ。






























を2画面搭載するモバイルディスプレー")














