




8月14日に発表された軽量AIモデル「Gemma 3 270M」はわずか2億7000万と軽量ながら、ローカル環境でも自然言語処理ができる性能を持ち、省リソースでも使えるAIを探す開発者の選択肢の一つとなりえるモデルだ。今回はこの「Gemma 3 270M」について紹介する。
軽量AIモデルながら知識密度が高い「Gemma 3 270M」
AIモデルは巨大であるほど高性能、という常識に一石を投じる存在が登場した。8月14日にGoogle DeepMindが発表した「Gemma 3 270M」は、わずか約2億7000万という軽量なパラメータ数が特徴だ。

8月14日、軽量AIモデル「Gemma 3 270M」がリリースされた
このモデルの狙いは、あらゆる問いに答える万能な知性ではなく、特定の業務を確実に遂行する「専門家」としての能力だ。スマートフォン上でも軽快に動作するほどの小ささでありながら、AI開発の新たな戦略の要となる可能性を秘めているのだ。
一般的なモデルは、思考を司る「Transformerブロック」という部分に多くの資源を割くのに対し、Gemma 3 270Mは総パラメータの6割以上を「埋め込み層」に集中させている。埋め込み層とは、言葉の意味を理解するための巨大な辞書のような部分だ。なんと25万6000語もの語彙を持つこの辞書のおかげで、専門分野のニッチな用語も直接理解できるようになる。企業などが特定の業務に合わせてモデルをファインチューニングする際、新たな単語を教える手間を省き、思考部分の学習に集中させることができるのだ。
Gemma 3 270Mはコンパクトながら、6兆トークン以上という膨大なデータで訓練されているのもポイント。従来の常識からすれば過剰ともいえるが、そのおかげで言語の多様なパターンがコンパクトなパラメータの中に凝縮された。その結果、極めて知識密度の高い基盤モデルとなっているのだ。
性能評価の軸もユニークで、一般的な知識量を測るテストのスコアを強調していない。代わりに、与えられた指示にどれだけ忠実に従えるかという「指示追従能力(IFEval)」で、同規模のモデルでは最高水準のスコアを記録したとのこと。これは、物知り博士としてではなく、確実な業務遂行エンジンとして評価してほしいという意思の表れだろう。
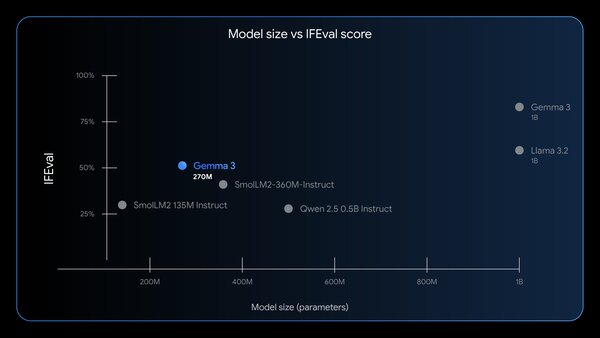
「指示追従能力(IFEval)」のスコアが計量モデルと比べると高いことがわかる
精度を少し落とす代わりにモデルを軽量化する「量子化」という技術を学習段階から想定しているため、性能の低下を最小限に抑えつつ、メモリ使用量を劇的に削減できる。
例えば、4ビット精度に量子化すれば、必要なメモリはわずか240MBほど。Googleのテストでは、スマートフォン上で25回の対話を実行してもバッテリー消費は0.75%にとどまったという。
ローカルで軽快に動作し、クラウドよりも快適に動く
Gemma 3 270Mは、AIを組み込んだシステムの設計思想に変化をもたらすかもしれない。コンパクトなAIを組み合わせて「スペシャリストの船団」という新たな設計図が作られることになるだろう。問い合わせ内容を分類する専門家、請求書からデータを抽出する専門家、文章のコンプライアンスをチェックする専門家などが生まれる。そして、それぞれに特化した小さなモデルを多数連携させることで、コスト効率にも優れるシステムを構築できるようになる。
Gemma 3 270はモデルの重みが公開されており、誰でも自由にダウンロードして使うことができる。オープンソースではなく、独自ライセンスだが、無料で商用利用もできる。
試しに、「LM Studio」で「Gemma 3 270M」をローカル動作させてみた。とにかく回答速度が速いので驚く。これなら、クラウドのサービスを使うよりも快適だ。とはいえ、簡単な質問には答えるが、少し複雑なタスクをさせようとするとすぐに破綻するのは想定通り。
試しに、「以下の文章を読み、ポジティブ、ネガティブ、またはニュートラルのいずれかに分類してください。文章: 」というプロンプトで、コメントの感情分析を行ったところ、即答した。ローカル動作でこのレスポンスであれば、ビジネスシーンで大活躍してくれるだろう。
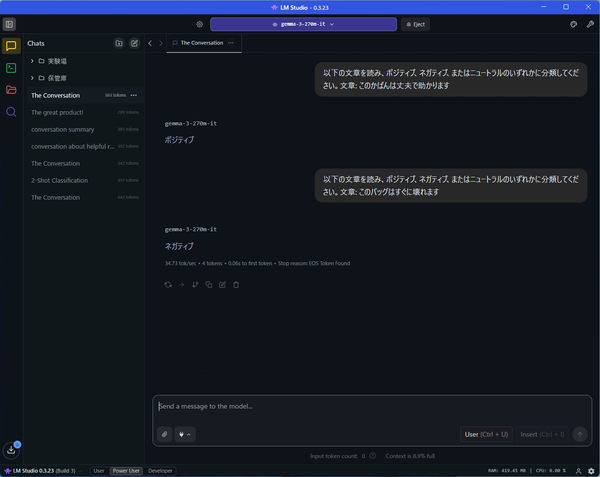
「Gemma 3 270M」でコメントの感情分析をしてもらったところ
Gemma 3 270Mはまだ原石に過ぎず、磨き方で価値が変わってくるだろう。公開されているモデルをそのまま利用するのではなく、ビジネスに合わせて微調整するのが基本だ。実験の母数を増やし、短周期で学習と検証を回す体制を敷けば、専門家の船団は確実に成果を積み上げることができるはず。今後、ビジネスシーンでの活用事例に注目したい。



