【2025年最新版】ETLとELTの違いとは?自社にピッタリな手法はどっち?


本記事はCDataが提供する「CData Software Blog」に掲載された「【2025年最新版】ETLとELTの違いとは?自社にピッタリな手法はどっち?」を再編集したものです。
企業が分散したデータをデータウェアハウス(DWH)に統合する際、一般的にETL またはELT と呼ばれるデータパイプラインを活用します。本記事では、ETL とELT の主要な6つの違いを解説し、それぞれの特徴を比較することで、様々なデータ統合シナリオにおける最適な選択をサポートします!
また、次世代のデータ統合手法であるETLT など最新のアプローチもご紹介します。
※本記事はCData USブログ ETL vs. ELT: Which is better? 6 key differences の翻訳記事です。
ETL とELT の概要
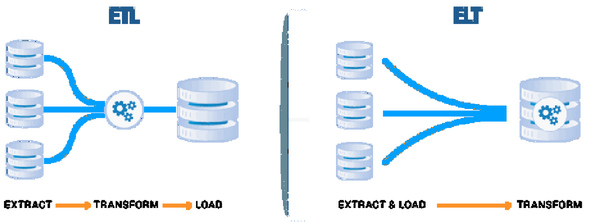
企業が複数の業務システムやデータベースからDWH やデータレイクにデータを取り込む際には、ETL(Extract:抽出、Transform:変換、Load:ロード)またはELT(Extract:抽出、Load:ロード、Transform:変換)処理を採用します。両者は同じ3つの処理で構成されていますが、その実行順序が異なります。
・抽出(Extract):業務システムからデータを取得
・変換(Transform):取得したデータを、複数のデータソースで使用される様々な形式から、データウェアハウスで採用される共通のデータモデルに標準化
・ロード(Load):標準化されたデータをDWH またはデータレイクに格納
ETL が登場した当初(1990年代)、データウェアハウスのリソースは現在と比べて大きく制限されていました。1990年代のストレージコストは現在と比較して数千倍以上高額で、計算処理能力も極めて限られていました。
このように厳しい制約が存在したため、データをDWH に格納する前に変換を行うことで、ストレージ、計算処理、ネットワーク帯域幅などの貴重なリソースを効率的に活用する必要がありました。
現在では、Snowflake、BigQuery、Databricks などのクラウドDWH やデータレイクは、ペタバイト級の大規模なデータストレージと、多数の同時接続ユーザーに対応する柔軟なスケーリング機能を提供しています。このテクノロジーの進化が、ELT という新しいデータ統合アーキテクチャを可能にしたのです。ELT では、データを抽出後すぐにデータウェアハウスやデータレイクにロードし、分析に必要な時点で初めて変換を行います。
ETL とELT のメリット・デメリット
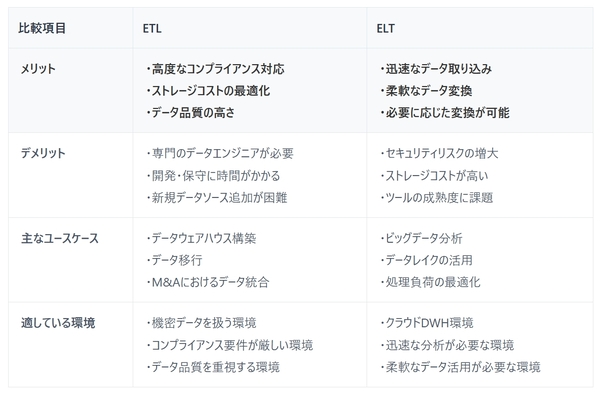
最近ではELT は近年人気のある手法ですが、必ずしも優れたソリューションというわけではありません。それぞれ長所と短所があり、ユースケースによって適した手法は変わってきます。ということで、ETL とELT のメリット・デメリット・ユースケースを比較してみましょう。
以下で詳しく説明していきます。
■ETL のメリット
ETL は、特に機密データの保護に関する規制要件への対応が必要な企業や、大規模なデータを扱う組織にとって優れたソリューションとなります。
・高度なコンプライアンス対応:GDPR(EU一般データ保護規則)、HIPAA(米国医療保険の携行性と責任に関する法律)、日本の個人情報保護法など、現代の企業はさまざまなデータプライバシー規制に対応する必要があります。対象となる企業には、顧客のプライバシー保護のため、特定のデータフィールドの削除、マスキング、暗号化が求められます。ETL では、データを格納する前に機密データの保護処理を実行できるため、より高度なデータセキュリティを担保できます。例えば、システム管理者がデータウェアハウスのログを通じて機密情報にアクセスすることを防止できます。
・ストレージコストの最適化:ETL では変換済みのデータのみをデータウェアハウスに転送するため、必要なデータのみを保存することでストレージコストを削減できます。一方ELT では、不要なデータも含めすべてのデータをDWH に格納する必要があります。
■ETL のデメリット
ETL の変換処理は、エンドユーザー(アナリスト)の分析ニーズに合わせた高度な変換を実行するため、コーディングと保守・運用を担当する専門のデータエンジニアチームが不可欠です。
例えば、以下のような異なるシステムからの顧客データを統合する場合を考えてみましょう。
// CRMシステムからのデータ
{
"customer_id": "A123",
"first_name": "Taro",
"last_name": "Yamada",
"birth_date": "1990-01-01",
"phone": "090-1234-5678"
}
// ECサイトからのデータ
{
"user_id": "U456",
"full_name": "Hanako Suzuki",
"dob": "1985/12/31",
"tel": "08012345678"
}
このような場合、データエンジニアチームは以下のような変換処理を(Python やSQL などを使って)実装・保守する必要があります。
・異なる形式の顧客ID の統一
・分割された姓名とフルネームの形式統一
・日付形式の標準化(YYYY-MM-DD 形式など)
・電話番号の形式統一(ハイフンの有無など)
・重複顧客の検出とマージ
このような開発には多大な時間を要し、新規データソースの追加も容易ではなく、スケールもしません。また、この処理には脆弱性があり、上流のスキーマや下流のデータモデルの変更によってパイプラインが破綻し、カスタムコードの修正が必要となることがあります。
■ETL のユースケース
ETL 処理は、最終的なシステムにおけるデータの形式と構造が重要視される場合に特に有効です。
・データウェアハウス:ETL はデータウェアハウスの構築時に広く採用されています。多様なデータソースからデータを抽出し、データウェアハウスのスキーマに適合するように変換してからロードすることで、効率的なレポーティングと分析を実現します。
・データ移行:企業が既存システムから新システムへデータを移行する際、ETL 処理を活用して旧システムからデータを抽出し、新システムの要件に合わせて変換した上でロードします。
・企業の合併や買収(M&A)におけるデータ統合:企業の合併や買収の際には、ETL を活用して異なるデータシステムを統合し、新組織全体で一貫性のあるデータエコシステムを構築します。
■ELT のメリット
ELT には、高い柔軟性、シンプルな構造、迅速なデータ取り込み、必要に応じたデータ変換など、多くの利点があります。
・迅速なデータ取り込み:ETL と異なり、ELT ではデータ取り込み前に複雑なパイプラインを開発する必要がありません。データの事前変換や構造化を行わずに、すべてのデータをデータウェアハウスに保存して、すぐにデータを活用できます
・データ変換を柔軟に実現:多くのDWH には、データの検索や操作のために豊富な機能が組み込まれています。CData Sync をはじめとするモダンなELT ソリューションでは、DWH のネイティブ機能を活用して、データのロード後に変換を実行できます。これにより、データエンジニアチームはDWH に実装されているSQL 処理を用いて、効率的にデータ変換を管理できます。また、dbt(data build tool)のようなモダンなデータ変換ツールを活用することで、SQL ベースのデータモデリングやテスト、ドキュメント生成をGit 管理下で実施でき、より堅牢なデータパイプラインを構築することができます。バージョン管理されたSQL ファイルを通じて、再現性の高いデータ変換を実現できます。
・必要に応じた変換:ELT では、特定の分析に必要なデータのみを変換すればよく、様々な方法で柔軟にデータを加工して、目的に応じたメトリクス、予測、レポートを作成できます。一方、ETL では既存の構造で新しい分析要件に対応できない場合、パイプライン全体の変更が必要となります。
■ELT のデメリット
ELT は大量の非構造化データを扱う企業にとって優れたソリューションですが、ETL と比較するとコンプライアンスや信頼性の面で課題があります。
・セキュリティリスクの増大:ELT では機密データを変換前にアップロードするため、システム管理者がアクセス可能なログに機密情報が露出するリスクがあります。また、データウェアハウスやデータレイクへのアップロード時にコンプライアンスに準拠していないデータがEU 圏外に移動することで、意図せずGDPR コンプライアンスに違反する可能性があります。
・成熟度の課題:ELT のツールやシステムは発展途上の段階にあり、ETL と比較して信頼性が十分とは言えません。ETL は初期設定に多くの工数を要するものの、そのデータ変換処理はELT よりも精度の高い分析を可能にします。
■ELT のユースケース
ELT 処理は、データの迅速な提供が優先される場合に特に効果を発揮します。代表的なユースケースは以下の通りです。
・ビッグデータ分析:ELT は、Snowflake、BigQuery、Databricks などのクラウドDWH を活用したビッグデータ活用に最適です。これらのプラットフォームの強力な処理能力を活用して、大量のデータをロードし、必要に応じて変換を行うことができます。
・データレイクの効率的な活用:ELT は、生データをそのままロードし、後続の分析やレポート作成のニーズに応じて変換を行うデータレイク環境で特に有効です。これにより、データの柔軟な利用と探索が可能となります。
・処理負荷の最適化:変換処理を高性能なクラウドデータウェアハウスやビッグデータプラットフォームに移行することで、ELT はソースシステムの負荷を軽減できます。これは、パフォーマンスの低下が許容されない本番システムにとって大きな利点となります。
データ統合のハイブリッドアプローチ(ETLT)
これまで説明してきたように、ETL は信頼性とコンプライアンスが重視されるユースケースに適しており、一方でELT は高速かつ柔軟なデータ変換が求められる場合に効果的です。
しかし、状況によってはETL とELT を組み合わせることが有効な場合があります。例えば、ELT の迅速なデータ取り込み機能を活用してアナリストに迅速なデータアクセスを提供し、分析対象のデータをリアルタイムで調整できるようにしたいが、同時に、データウェアハウスへの移行前にPII(個人識別情報)のマスキング、削除、暗号化を行い、セキュリティやコンプライアンス要件を確実に満たす必要がある場合が考えられます。
ETLT(抽出、変換、ロード、変換)は、両者の利点を組み合わせた新しいフレームワークで、以下の手順でデータをDWH やデータレイクに統合します。
・業務システムから生データを抽出し、ステージング領域に配置
・ステージング領域で軽微な変換を実行し、機密データの保護処理を実施(削除、マスキング、暗号化)。この変換は各データソースに対して個別に行われるため、迅速な処理が可能
・処理済みデータをデータウェアハウスにロード
・データウェアハウス内で本格的な変換・統合処理を実行し、データベースやSQL を活用してトランザクションを処理。この第二段階の変換では、複数のデータソースからのデータを統合するために必要な処理を実施
このようなハイブリッドアプローチにより、データエンジニアの方はより柔軟かつ効果的にデータ統合のニーズに対応することができます。
CData Sync:ETL・ELT・ETLT-どんな構成でも扱えます
ETL / ELT ツールのCData Sync なら、本記事で扱ったいずれの構成でも対応できます。400を超える主要なデータベースや業務システムに対応し、任意のデータウェアハウスやデータレイクへのレプリケーションを実現。ETL ならSQL でのデータ変換に対応し、ELT ならSQL での変換の他dbt 連携をサポートします。
詳しくは、CData Syncの製品デモや30日間の無料トライアルをぜひお試しください。
本記事はアフィリエイトプログラムによる収益を得ている場合があります