FSR 4はRDNA 4専用として実装
RDNA 4世代の新GPU「AMD Radeon RX 9070XT/ RX 9070」の詳細が明らかになる
2025年02月28日 22時00分更新

RDNA 4ではレイトレーシングとAI処理強化に注力
RX 9070シリーズのベースとなったRDNA 4アーキテクチャーはコスパ重視のアーキテクチャーであるが、特に描画負荷の重いゲームの処理能力を向上させることに注力している。ラスタライズや性能向上にも注力している(RDNA 3比で1.5倍程度)が、特に注力しているのはレイトレーシング(同1.8倍程度)とAI性能(同2倍)の強化である。
物理的な面で注目したいのはRX 7900シリーズのようにGPUコア部分(GCD:Graphics Compute Die)とInfinity Cache&メモリーコントローラー部分(MCD:Memory and Cache Die)を物理的に分割するチップレット構造ではなく、すべてを1つに統合するモノリシック構造(TSMC 4nmプロセス)である点だ。RX 7900シリーズではGCDの数を調整することでRX 7900 GREからRX 7900 XTXまでバリエーションを増やすことができたが、GCDとMCD間のリンクの設計難度が高くRDNA 4では採用されていないのだ。
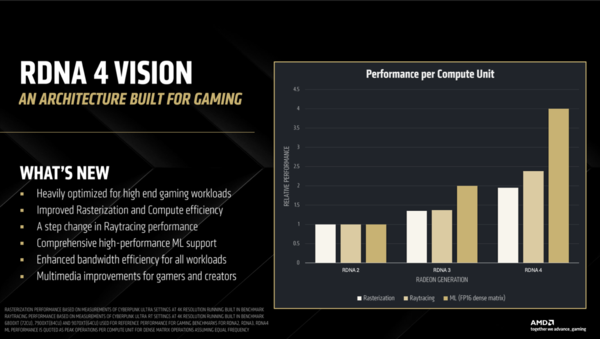
RDNA 2のCU1基における3種類の性能、すなわちラスタライズ/ レイトレーシング/ AI(FP16)性能をそれぞれ1とした場合に、RDNA 3やRDNA 4ではどの程度の性能になったか、という比較グラフ。RDNA 3から比較するとラスタライズ性能は1.5倍弱、レイトレーシング性能は1.8倍弱、AI性能は2倍と読み取れる
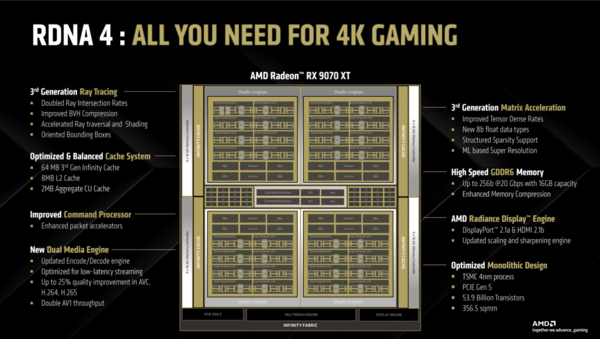
RDNA 4(RX 9070 XT)の特徴や強化された要素一覧。Ray AcceleratorとAI Accelerator(旧称AI Matrix Acclerator)はそれぞれ第3世代に更新。Infinity Cacheは合計64MB、ハードウェアエンコーダーを内包するメディアエンジンは2基搭載されている
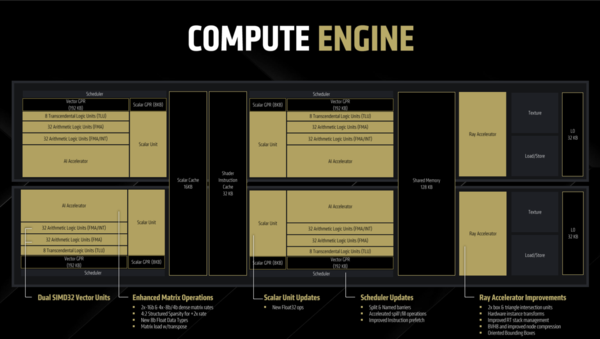
RDNA 4のCompute EngineはRDNA 3と同様に2基のCUを共有キャッシュで束ねたものである。前世代に比してCUの処理効率の向上のほか、レイトレーシング性能に影響する動的なレジスター割り当て機能の追加、メモリー圧縮効率の強化などが盛り込まれた
レイトレーシング性能の強化は複数のアプローチを組み込むことで達成された。まず単純にレイとBVHやトライアングルの交叉判定をする「Intersection Engine」を2個並列に並べることで、同じ時間で処理できるレイの数を2倍にした。さらにBVHとレイの衝突判定の無駄を省くための工夫も組み込まれた。
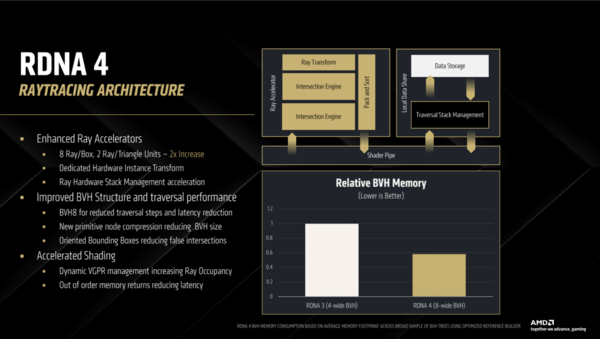
最大の強化点は第3世代のRay Acceleratorである。Intersection EngineはレイがBVHやトライアングルと交叉するか判定するためのものだが、これが従来の1基から2基に増加。これだけでCUあたりのレイトレーシング性能は従来比1.7倍程度になる
伝統的なBVHでは境界が3D世界のXYZ軸に沿って配置される。下の画像の場合、ナナメに配置されたオブジェクトに対してもBVHは軸に沿った配置になるため、レイとBVHが衝突したと判定されても実際のオブジェクトにはかすりもしないケースもままある。そこでAMDはBVHの境界をノード単位で回転させるOBB(Oriented Bounding Box)を実装することでオブジェクト周囲に誤判定を生む空間が最小限になるようにした。

RDNA 4のRay AcceleratorはBVHの境界のあり方もひと工夫した。右下のヒートマップのうち上は伝統的なBVHで構築したもので、ナナメに走っているクレーンのアーム部分において衝突判定が多数発生しているのが可視化されている。下のヒートマップはRDNA 4の機能を使った場合で、アームの周囲ギリギリまで無駄な処理が発生しないように調整されている。これだけで10%程度の性能改善が見込めるようだ

RDNA 4のRay Acceleratorの性能向上は多数の要素の集合である。貢献度において最大なのはIntersection Engineを2倍にしたことだが、その他にOOBやBVHの圧縮などさまざまな工夫も盛り込まれている
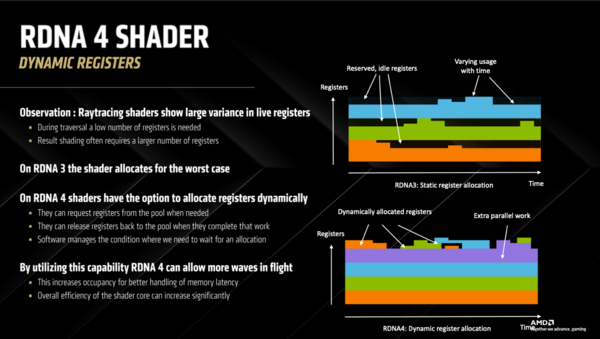
Ray Accelerator以外でもCUの処理効率を上げる試みがこれ。シェーダー内のレジスターは処理の状況によっては仕事が割り振られない時間がある。レイの衝突判定をしている最中は少ないレジスターで済むが、具体的な描画処理では多数のレジスターが必要になる。RDNA 4ではレジスターの確保や解放が必要な時に実施できるように改善された。つまり休眠している回路が減るわけで、パフォーマンス向上に大きな期待ができる

AI Accelerator(RDNA 3ではAI Matrix Accleratorと最初呼んでいたもの)は新たにFP8に対応した。FP8といえばFSR 4の処理で利用される精度であり、この点がFSR 4がRDNA 4専用たらしめていると推察される
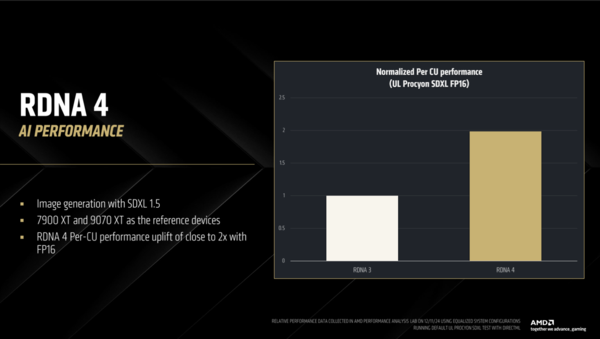
「UL Procyon」の“AI Image Generation Benchmark”からSDXL 1.5を利用したテストの結果。RX 7900 XTとRX 9070 XTを比較すると、CUあたりの性能は2倍に達するという。GPU単位で比較するとRX 9700 XTはRX 7900 XTの1.5倍程度といったところか。その理由はRX 7900 XTよりもRX 9070 XTはCUが少ないからだ
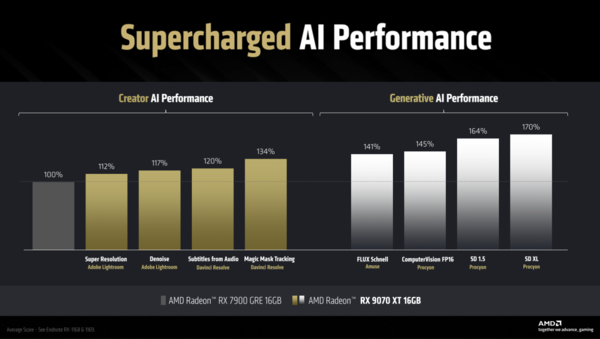
「Lightroom」や「DaVinch Resolve」などにおいて、RX 9070 XTはRX 7900 GREよりも12〜34%高速に処理できる。RX 7900 XTとの比較データはない
発売まであと数日……(国内価格は???)
AMDのRX 9070シリーズの発表資料を基にこれはと思った点をまとめたが、最新世代のGeForceと真っ向から勝負を避けてはいるものの、着実に必要な機能を実装していると感じた。特にレイトレーシングやAIに関しては完全にGeForceが先行しているが、RDNA 4の登場で最新機能をメインストリーム層に届けることが可能になる。レイトレーシングもAIも不要だと言うユーザーもまだ多数いるが、このトレンドから逃れることはできないのだ。
ただ筆者としてはFSR 4のAIを用いた処理については結局NVIDIAと同じような進化(自社で計算した学習モデルをGPU内のAI専用回路で処理する)を選び、アピールする点も同じという点には少々落胆させられた。AMDはかねてより「DLSSは特定ハードへ紐付けている。その点FSRはオープンだ」と評しておきながら、FSR 4ではRDNA 4縛りになった。言行不一致の典型例と言わざるを得ない。ただユーザーにより良い機能を提供した、という点はこのマイナス点を充分補ってくれるだろう(技術とはそういうものなのだ……)。
本記事はアフィリエイトプログラムによる収益を得ている場合があります












