



AWSを支えるテクノロジーにディープダイブ 今年はハードウェア三昧
最強のAIインフラをAWSが披露 シリコンからAIサーバー、ネットワークまで
2024年12月06日 10時00分更新

AIはスケールアップ型のワークロード
ブラウン氏が降壇した後、紹介されたのは推論とトレーニングを行なうAIのカスタムチップについて。まずデサントス氏が指摘したのは、「AIワークロードはスケールアップのワークロード」ということだ。
生成AIの大きな成長の源泉は、やはりパラメーター数の増大。数十億、数百億、まもなく兆規模に達するパラメータの増大は、それに合わせた演算能力の拡大が必須となる。しかし、スケーリング法則によると、損失指標を半分にするためには、100万倍の処理能力が必要になる。より賢いLLMを実現するためには大幅な演算能力が必要となり、AI開発企業の莫大な投資につながっている。
では、より優れたAIインフラとはなにが必要になるのか? 最新の生成AIモデルの本質は、あるトークンを入力すると、次のトークンを予測するエンジンと言える。この予測誤差を最小化するためには、何兆ものデータでの学習が必要になり、トレーニングには途方もない時間がかかるため、まずは並列処理を模索する。
「1000年かかる演算処理を1000台のサーバーで1年で済ませよう」というわけだが、並列処理のためにはデータの分割が必要になる。グローバルバッチサイズという方法では、適当なデータに分割し、並列処理でトレーニングを行ない、他のサーバーと結果を結合し、全部終わると次のバッチになる。ただ、このグローバルバッチサイズでは、おおむね1000台が限界だという。結局、サーバーが処理したデータの同期作業に時間がかかってしまうからだ。
このスケールアウトの限界のため、大きなグローバルバッチサイズの場合は、スケールアップ型の強力なサーバーが必要になる。つまり、スケールアップのアプローチだ。強力なサーバーは高速なコンピューターとメモリをできるだけ小さなスペースに詰め込むことで実現される。コンピュートチップとメモリをなるべく近接させ、遅延を極力まで小さなければならない。
デサントス氏は、この「CPUとメモリの近接」を最小コンポーネントであるTrainium2から紹介する。パッケージは改良が続けられており、Trainium2ではコンピュートチップとメモリモジュールも近接されており、低い電圧で多くの電力を移動させるパワービアを配線し、電圧降下が起こらないように、レギュレーターが電圧を調整しているという。

Trinium2の断面図を見ると、コンピュートチップとメモリがインポーザーで接続されているのがわかる
Trainium2はCPUとGPUとは異なる
Trainium2のアクセラレーターボートとNitroカードはトレイに搭載されている。現状、ヘッドノードはアクセラレーターボートが16を超えると、ボトルネックが発生してしまう。先日発表されたTrinium2搭載のインスタンスは最大20ペタフロップスの処理能力を持つ。

20ペタフロップスを実現するTrinium2サーバー
Trainium2サーバーは1.5Tbps帯域幅を持った高速メモリを搭載する。これは最新のAIサーバーの2.5倍の帯域幅になる。また、ケーブルの数を極力抑え、配線トレースでカバーされている。さらに製造からテストまで自動製造が可能なように設計されており、他のAIサーバーより拡張が容易になっているという。

自動製造が可能なTrinium2サーバー
Trainum2自体のアーキテクチャも既存のCPUやGPUと大きく異なっているという。最新のCPUはプロセッサーとアクセラレーター、キャッシュを1つの単位をとし、メモリを共有している。そのため、メモリの帯域幅に性能が依存してしまう。また、GPUは何百~何千もの演算器が並列処理を行なうアーキテクチャとなっており、AIの処理においては高い演算性能を実現する。
一方でTrainiumはSystolic Arrayというアーキテクチャを採用し、各コンポーネントを相互に接続し、長い処理パイプラインを構成できる。CPUとGPUのようにメモリからデータを読み込んで演算を行なって、再度メモリに書き戻すという処理ではなく、Systolic Arrayは処理エンジン間で直接データを転送しており、キャッシュアクセスがメインとなる。
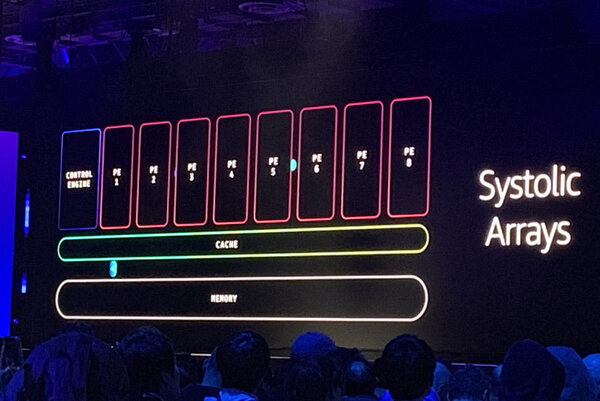
Systoric Arrayの仕組み
加えてAIの演算で利用される行・列の計算、Tensor演算に対応するレイアウトを特別に設計したことで、Trainium2では従来に比べてメモリ帯域幅を有効に活用できるようになっている。さらにNKI(Neuron Kernel Interface)という新しい言語も用意した。研究者にTrainium2を開放し、そのユニークなハードウェア機能を活用した研究を推進するプログラムもスタートさせた。「もっとも強力なAIサーバーを構築した」とデサントス氏はアピールする。
加えて、「NeuronLink」という独自のインターコネクトも開発した。2Tbpsの帯域幅と1マイクロ秒の低遅延を実現。複数のTrainiumサーバーを相互に接続することで、単一のUltraServerを構成。サーバー間でも直接メモリにアクセスできるため、要件の厳しいAIワークロードをこなすことが可能になる。デサントス氏は、ステージ上にある64ものTrainium2チップを搭載したUltraServerを披露した。

2Tbpsの帯域幅、1マイクロ秒の低遅延を実現するNeuronLink
推論には、大きくインプットを演算に必要なデータ構造に変えるための「プリフィル」と、モデルごとの「トークン生成」に別れる。プリフィルは演算能力が必要だが、トークン生成は演算能力は小さいが、メモリアクセスが必要で、ワークロードの性格はかなり異なる。裏を返せば、リソースの利用で補完関係にあるため、両者をAIサーバーで同時に処理することで、効率性を高めることが可能になっているという。
AWSとともにAIクラスターを構築するAnthropic
発表の中では、新たにBedrockの「Latency-Optimized inference Option」も発表。LlamaやAnthropicのClaudeも、他社サービスに比べて高速に処理できるという。ここでAnthropicのChief Computer Officerであるトム・ブラウン氏が登壇する。
最新のClaude 3.5 Haikuは小サイズながら、高い性能を誇る。さらにBedrock Latency-Optimized inference Optionを用いることで、Trainium2上で60%以上の性能向上を実現するという。これを実現するため、AnthropicとAWSは1年に渡って緊密に連携し、NKIを用いて低レベルでのコントロールを実現した。
ブラウン氏は、「別のAIチップでは、どの命令がカーネル処理を行なっているか見えない。これでは目隠しでテトリスをプレイするようなものだ。私が知る限り、Trainium2はすべての処理をナノ秒レベルで記録できる初めてのAIチップだ」と語る。ブラウン氏は演算の実行・ブロックの様子を披露。
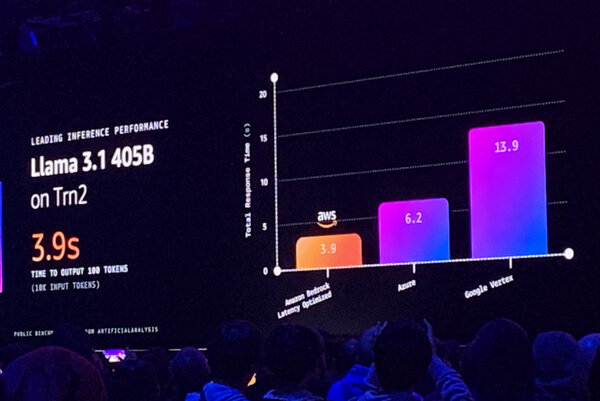
演算処理の様子が見える化されている
現在、AnthoropicはAWSとともにUltraServerのクラスタープロジェクト「Project Rainier」を推進している。ブラウン氏はこのProject Rainierを活用することで「よりインテリジェントで、より低価格なモデルを、より迅速に提供していく」とまとめた。
10ペタバイトを10マイクロ秒で伝送するAI最適化ネットワーク
AIのワークロードはスケールアップ型。しかし、AWSが長らく手がけてきたスケールアウト型のアプローチは、最強のAIインフラを構築するためにも役立っている。最後に紹介したのは、AIに最適化されたネットワーク「10p10u」のトピックだ。

AI最適化ネットワーク「10p10u」
多くのユーザーが利用するクラウドネットワークは、伝送容量が重要。しかし、AIサーバー同士を相互接続するAIネットワークは、それ以上に伝送容量は必要で、遅延にもセンシティブ。もしダウンすると、トレーニングプロセスが停止してしまい、アイドル時間が発生するため、高い可用性も必要になるという。「AWSのクラウドネットワークの可用性は99.999%だが、AIのネットワークはより厳しい要求をたたきつけてくる」とデサントス氏は語る。
そこで生み出されたのが、10マイクロ秒の遅延で数千台のサーバーに10ペタビットの帯域をを可能にする10p10uだ。見た目に鮮やかな緑色のスイッチは、サプライヤーから余った塗料をもらって着色したものだという。膨大な数のラック内のケーブルはパッチパネルで接続され、16本のファイバーを1つにまとめたトランクコネクターを用いることで、作業時間も短縮している。

16本のファイバーを1つにまとめたオリジナルのトランクコネクター
収束に時間がかかるAIネットワーク用のルーティングプロトコルも新たに開発した。この「SIDR(Scalable,Intent Driven Routing)」は、経路情報を中央に集約しつつ、ピアの経路変更にも迅速に対応できるため、10p10uネットワークでは経路障害から1秒以内で回復できるレジリエンスを持つ。「これは他のネットワークに比べて10倍速い。経路の再計算を行なっている間に、10p10uネットワークでは、すでに通信を再開している」という。
1時間半に渡って、シリコンからAIサーバー、ネットワークに至るまで最強のAIインフラを技術的に解説したセッション。クラウドイベントでありながら、ハードウェア満載の内容だったが、さまざまなテクノロジーのチャレンジが非常に新鮮だった。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



