



AWSを支えるテクノロジーにディープダイブ 今年はハードウェア三昧
最強のAIインフラをAWSが披露 シリコンからAIサーバー、ネットワークまで
2024年12月06日 10時00分更新

AWS re:Invent 2024の基調講演の前夜祭にあたる「Monday Night Live」には、今年もピーター・デサントス氏が登壇。クラウドサービスを支えるAWSのテクノロジーを余すことなく披露するテクニカルなセッションだが、今年はAIインフラにフォーカス。カスタムシリコンからAIサーバー、ネットワークまで幅広いトピックをディープに掘り下げた。

AWS ユーティリティコンピューティング SVP ピーター・デサントス氏
実ワークロードにこだわったGraviton開発秘話
登壇したデサントス氏は、AWSを支える技術にディープダイブするMonday Night Liveについて説明。複雑な問題に対して、迅速に意思決定できるメカニズムやユーザーを支える幅広いイノベーションとそれを支えるカルチャーについて紹介。続いて登壇したAWS Compute & Networking VPのデイブ・ブラウン氏はカスタムシリコンの開発について説明した。
ブラウン氏は18年前にAWSに入社。14人ほどのチームは、南アフリカのケープタウンに拠点をかまえ、後のEC2にあたるサービスを開発していたという。その後、耐障害性やパフォーマンス、エネルギー効率を最大化するクラウド基盤のオーケストレーションレイヤーの構築を続け、行き着いたのがカスタムシリコンの開発だ。
2018年に発表されたARMベースのオリジナルプロセッサーであるGravitonは、最速のチップを作るというより、「市場に信号を送る」という意味合いが強かった。ブラウン氏は「開発者が利用できるハードウェアを開発し、データセンターにおけるARM活用の業界コラボレーションに火をつけたかった」と振り返る。Graviton2はWebサービスやコンテナ化されたマイクロサービス、データ分析などスケールアウトワークロードをターゲットに完全なオリジナル設計されたという。
続くGraviton3は高い性能を必要とするワークロードまでその適用範囲を拡大。AIの推論やトランスコーディング、暗号化処理まで、性能を2倍にしてきた。最新のGraviton4はクラウドコンピューティングで学んだことの集大成となったという。マルチソケットを対応し、データベースやWeb、Javaアプリなどの性能はGraviton3と比べた30%向上を実現した。

世代ごとに確実に性能向上を図ってきたGraviton
Gravitonはアプリケーションごとの性能にこだわっている。最新のCPUはフロントエンドで命令セットをデコードして、バックエンドで処理を実行するという構成になる。このCPUのマイクロアーキテクチャー開発でAWSが用いてきたのが、CPU全体のパフォーマンスではなく、ワークロードごとにCPUパイプライン内の負荷を評価する「マイクロベンチマーク」という手法。「これは短距離走でマラソンのトレーニングをしているようなもの。整然としたベンチマークと異なり、混沌としており、予測不可能。でもはるかに面白い」とブラウン氏は語る。
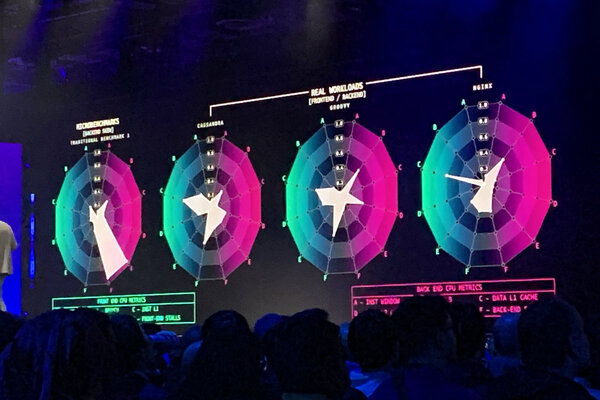
マイクロベンチマークでアプリケーションごとの性能を測定
実際にGravitonでCassandraやGroovy、NGINXを動作させると、アプリケーションごとに負荷のかかる箇所はそれぞれ異なる。フロントエンドで命令セットの分岐予測アルゴリズムの精度が低かったり、バックエンドのL1、L2、L3キャッシュやTLB(Translation Lookaside Buffer)の利用効率が悪いと、ボトルネックが発生する。実ワークロードでベンチマークを行ない、改善を続けた結果、特定のアプリケーションでの性能強化が実現した。
Graviton3では前バージョンに比べて30%の性能向上が見られたが、特にNGINXでは分岐予測の向上で60%の性能向上となったという。そしてGraviton4ではMySQLワークロードで40%の性能向上を達成。「これは大規模なデータベースを運用する場合に、なにを意味するのでしょう。実際の改善を実感してくれているから、お客さまはGraviton4を気に入ってくださる」とブラウン氏は語る。

アプリケーションごとの性能向上が異なる
改善は性能のみではなく、価格性能比にも表れる。AuroraやRedshift、ElastiCacheなどをGravitonベースのインスタンスで動かすと、40~50%の価格性能比メリットを得られる。「世界最大級のAmazon PrimeDayでは、20万個以上のGraviton4が稼働していた」(ブラウン氏)とのこと。過去2年間でAWSのCPU容量の約半数以上がGravitonとなり、すでに大きな成長を遂げていることがわかる。
チップレベルでのセキュリティを確保するAWS Nitro System
実はAWSがシリコンレベルでの革新を行なったのはGravitonが最初ではない。AWSが長らく提供してきたEC2インスタンスの性能とセキュリティを実現するため、Gravitonに先んじて開発されてきたのが「AWS Nitro System」だ。「増え続けるEC2において、世界クラスのパフォーマンスとセキュリティを実現するには、スタック全体でイノベーションが必要だった」とブラウン氏は語る。
カスタムシリコンNitroチップをベースに構築された仮想化基盤のAWS Nitro Systemでは、クラウドでの利用を前提にサーバーアーキテクチャを従来から大きく変更している。仮想化のコストを排除しつつ、さまざまなコンピューター上でEC2インスタンスを立ち上げることができる。Macインスタンスを立ち上げられるのも、AWS Nitroの柔軟性があるからだ。
AWS Nitroはすべてのシステムが期待通り動作していることをセキュアに証明する仕組みが盛り込まれている。「単にセキュリティを確保するだけではなく、ハードウェアサプライチェーンを革命的に一新してる」とブラウン氏。ハードウェアはROMから起動し、ファームウェアをロードし、ブートローダーからOSを立ち上げる。このプロセスで不正なコードが実行されることがないよう、Nitroチップには製造時に固有の秘密鍵が埋め込まれている。公開鍵暗号方式における正当な認証プロセスを経なければ、システムのアクセスが制限される。また、チップの製造品質からファームウェアのバージョン管理までを署名を用いて一貫性のある形で検証しているという。

秘密鍵をハードウェアに実装
このNitroの仕組みは、Gravitonにまで拡大されており、システム間の相互信頼を可能にしている。2つのGravitonが連携する場合は、お互いで認証を行ない、暗号化通信を行なう。これはNitroとGraviton間も同じ。つまり、AWS NitroやGravitonをベースにしたインフラでは、ハードウェアベースのセキュリティが実現される。「チップの製造時から稼働まですべての瞬間で暗号化されたやりとりが用いられており、検証されたハードウェア上でお客さまのワークロードが実行される。従来のサーバーやデータセンターでは実現できないセキュリティ」とブラウン氏は語る。
ストレージの収容密度を追求し続けたら2トンになった
AWS Nitroによって解決したのは、仮想化やセキュリティだけではなく、ストレージの課題にもおよぶ。2006年当時、AWSは500GB程度のドライブを採用していたが、現在は20TBのドライブを導入している。一方で製造過程の革新もあり、テラバイト単価でのストレージの価格は過去20年で大きく下落。そのため、こうした技術革新に対応し、ストレージを効率的に利用するのがAWSにとって大きな課題になった。
Amazon S3やEBSのようなストレージサービスでは、大きく3つの構成要素がある。APIコールを処理して、リクエストを認証し、顧客にユーザーインターフェイスを提供するフロントのWebサーバー、インフラ全体でデータの位置を特定するための頭脳にあたるインデックスやマッピングサーバー、そして実際のデータが保存されるストレージサーバーになる。
このうちストレージサーバーは、従来ヘッドノードアーキテクチャを採用していた。標準コンピューターであるヘッドノードには、I/O処理やデータ完全性、ドライブの耐久性などをすべて管理する専用ソフトウェアが搭載されており、束ねられたドライブにデータを読み書きするという構成だ。ブラウン氏は、「ここで課題になるのは、コンピューティングとストレージの比率が固定されてしまうことだ」と指摘する。
AWSはストレージ容量の拡大に向けて、ディスク単体の容量と台数を増やすことで対応をしてきた。最初はホスト1台に対して、24台のディスクという控えめな構成だったが、ドライブとデータ管理のテクノロジー向上で搭載密度はどんどん上がる。36台となり、72台となり、最終的には1台のホストに288台のディスクを搭載する「Barge」という産物に至る。20TBのディスクが288台なので、最大容量は6PB。これはAWS初期のデータセンターよりも大きい容量だ。

288台のディスクを搭載するBerge
搭載密度を追求したエンジニアリングの取り組みとしては成功したBargeだったが、いくつかの限界点に突き当たった。まず物理的な制約。Bargeの1つのラックは2トン以上もあるため、データセンターの床荷重が耐えられず、移動も専用の機器が必要になる。また、288台ものドライブの回転は大きな振動を生むため、信頼性とパフォーマンスにも悪影響を与えてしまう。さらに288台のディスクを単一ホストから管理するソフトウェアは複雑さを極める。なにより故障したときに影響が甚大すぎる。「私たちはBergeにここでさよならを言わなければならなくなった」とブラウン氏は語る。
高いパフォーマンスを確保しながら、運用性を向上し、俊敏性を得るためにはどうしたらよいか。開発チームはEBS、EFSなどのストレージサービスに目を向け始めた。ここで行き着いたのが、AWS Nitroを用いたコンピュートとストレージの分離というコンセプトだ。具体的にはAWS Nitroカードがディスクアクセスを切り替えるスイッチのように機能し、故障したディスクはAPIコールで迅速に分離できる。
一方、ヘッドノードはどうか? このような非集約型のストレージの場合、単一障害の影響が大きいヘッドノードの故障という問題から開放される。AWSの場合は、ディスクに対して個別にアドレスを指定でき、インスタンスを起動し、ディスクを再接続するだけで利用できる。

Nitroとストレージは物理的に分離されている
また、コンピュートとストレージを分離したことで、固定比率から脱却し、それぞれ独立して拡張できるのも大きなメリットとなった。障害の影響範囲も限定的になり、サービスをかつてないほど強靱にすることが可能になったという。「AWSのサービスはハードウェアの制約だけではなく、実際のニーズに基づいてコンピューティングリソース適正化することができる。メンテナンスも容易になり、キャパシティプランニングも迅速にできるようになった」とブラウン氏は語る。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



