




NTTは2024年5月7日、過去の学習(トレーニング)過程を再利用することで、AIモデルの再学習コストを大幅に削減する「学習転移」技術を発表した。同社によると世界初の技術で、同社の「tsuzumi」をはじめとした大規模基盤モデル(ファウンデーションモデル)の更新時や差し替え時に、各ドメインにおける再学習(ファインチューニング)が容易になることが想定されている。2025年度以降の実用化を目指す。
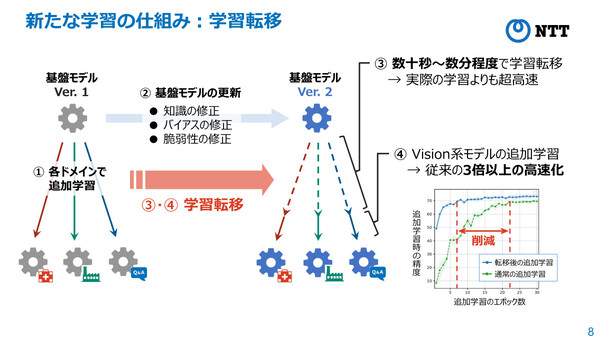
今回発表した「学習転移」技術の概要。(3)(4)の学習/追加学習処理を高速化する


NTTコンピュータ&データサイエンス研究所 革新的コンピューティングアーキテクチャ研究プロジェクト 主幹研究員の竹内亨氏、研究員の千々和大輝氏
基盤モデル更新時にドメイン特化モデルの再学習コストを削減するには?
学習転移は、深層学習(ディープラーニング)処理において、「過去の学習過程をモデル間で再利用する」新たな仕組みとなる。具体的には、ニューラルネットワークのパラメータ空間における高い対称性を活用して、過去の学習過程のパラメータ列を適切に変換することで、新たなモデルの学習結果を低コストに実行できるというもの。
これにより、生成AIの大規模基盤モデルに追加学習や定期的な更新が行われた際に、再学習や再チューニングのコストを大幅に削減することができる。
NTTコンピュータ&データサイエンス研究所 革新的コンピューティングアーキテクチャ研究プロジェクト 研究員の千々和大輝氏は、企業などにおける生成AI運用の容易化、AI適用領域の拡大、消費電力の削減などに貢献できると述べ、「次世代のAI技術開発や運用に貢献できる」と同技術の価値を説明する。
これから企業が生成AIを活用する際には、さまざまな業務ドメイン(領域)が持つそれぞれの要件に対応するため、基盤モデルをベースにドメインごとのデータセットを用いた追加学習(ファインチューニング)を行った“ドメイン特化モデル”を活用することが一般的になると見られている。
しかし、ベースとなる基盤モデル側で知識やバイアス、脆弱性の修正などが行われ、基盤モデルのバージョンが変わった際には、ドメイン特化モデルも再学習させる必要があった。ここでは多大な計算コストが生じることになるため、千々和氏は「今後の生成AIの普及に対して大きな障壁になることが予想されている」と指摘する。
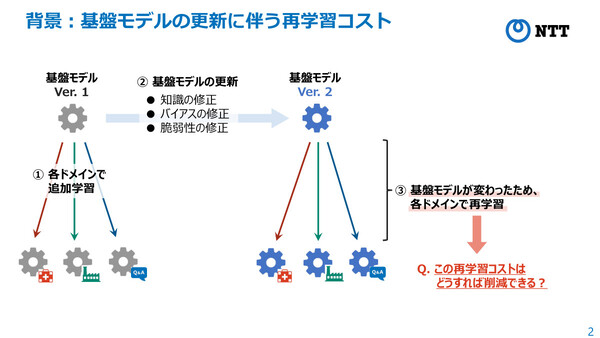
基盤モデルが更新(バージョンアップ)されると、その基盤モデルをベースに追加学習を行っていた“ドメイン特化モデル”の再学習も必要となる
「基盤モデル自体が更新されると、それをチューニングして得られていたモデル(ドメイン特化モデル)すべてに対して、再度チューニングを実施する必要がある。しかし(転移学習、継続学習、モデルマージといった)既存のアプローチは、基盤モデルの更新に伴う再学習コストの削減には適用できず、新たなパラダイムが必要になっている」(千々和氏)
同プロジェクト 主幹研究員の竹内亨氏も、「現時点では、基盤モデル更新のたびに特化モデルをファインチューニングするコスト増の課題は顕在化していないが、生成AIの普及とともにも、基盤モデルのアップデートも進み、更新時のコストが課題になるのは明らかだ」と語る。
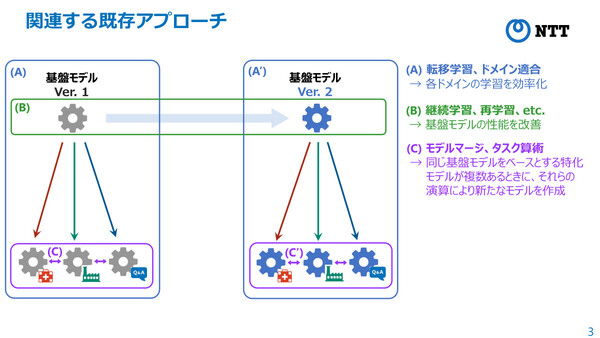
既存のアプローチでは、基盤モデル更新時の各ドメインにおける再学習の効率化は実現しない
特化モデルの「学習過程」を転移可能に、再学習なしで一定の精度を維持
今回発表した学習転移技術は、各ドメイン特化モデルの「学習過程」を別の基盤モデルに転移させることができ、高コストな再学習を行うことなく、変換のみで一定の精度を達成することができる。さらに、学習転移後に追加学習を行うことで、目標精度に早く到達することができるようになるという。
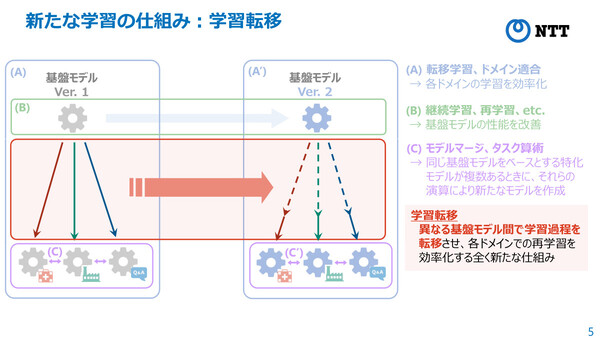
今回発表された学習転移技術が、従来アプローチでカバーできなかった各ドメインでの再学習の効率化を実現する
今回の研究では、ニューラルネットワークのパラメータ空間に存在する高い対称性に着目し、「置換変換」と呼ばれるニューロンの入れ替えに関する対称性の下で、異なるモデル間の学習過程同士を、近似的に同一視できることを発見。これに基づき、過去の学習過程を適切な置換対称性によって変換し、新たなモデルの学習過程として再利用できるという。
「Permutation変換によって、中間層のニューロンを入れ替えることができる操作に対応する。途中のニューロンを入れ替えるだけなので、最終的なニューラルネットワークの出力を変化させず、変換後も学習過程の性質が保たれる。つまり実際の学習(再学習)を行うことなく、超軽量な最適化計算によって、学習済み精度が維持できる」(千々和氏)
ビジョン(視覚情報)系モデルでの検証によると、この学習転移にかかる時間は「数十秒から数分程度」で、再学習と比べて超高速に実現できるうえ、一定の精度が維持できる。さらに、そこから精度を高める追加学習も、従来の3倍以上の高速化が可能になったという。今後、より普及している自然言語モデルについても検証を行い、実用化に向けた検討を進める計画だ。
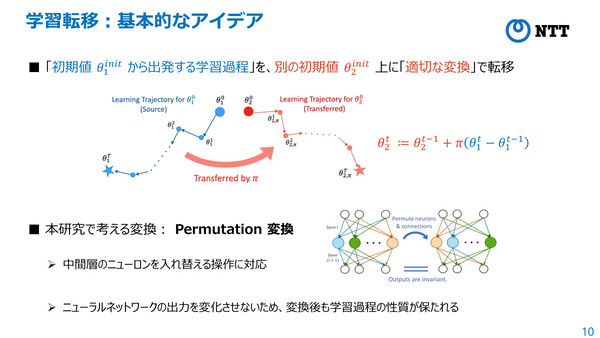
今回の学習転移技術の基本的なアイデア
NTTのLLM「tsuzumi」や「AIコンステレーション」での活用を見込む
今回の学習転移技術の実現においては、3つの技術ポイントがあるという。
ひとつめは「学習転移の定式化」である。
ここでは、2つの学習過程間の変換を最適化する枠組みを世界で初めて提案した。2つのパラメータで初期値が与えられたときに、一方の初期値に対する学習過程を変換すると、もう一方の初期値の学習過程との距離を最小化するように置換変換を求める「最適化問題」として定式化したという。
2つめは「高速なアルゴリズムの導出」だ。
定式化された最適化問題に現れるターゲットの学習過程は未知であるため、コンピューター上で扱うことはできないが、「学習過程の各ステップが勾配で近似できる」という仮定を置くことで、実際にコンピューターで扱える「非線形最適化問題」を導出。学習過程の部分的な転移と、線形最適化を交互に行うことで、効率的かつ高速に解くことが可能になったという。
3つめが「理論的分析」である。
2層ニューラルネットワークの数理モデルでは、ネットワークサイズが大きくなるほど、最適な置換変換が高い確率で存在。ソースの初期学習過程を変換することで、ターゲットの初期学習過程に近づけられることを証明した。これにより、ニューラルネットワークが大規模になるほど、学習転移が可能になることを理論的に示すことができたという。
NTTでは、今回の学習転移技術によって、深層学習における新たな学習手法の基礎理論を確立するとともに、その応用として基盤モデルの更新や変更時のチューニングコストを大幅に低減できる可能性を明らかにできたとしている。
たとえば、NTTのtsuzumiにおいては、各ドメインにファインチューニングした特化モデルの活用が想定されており、tsuzumiの更新にあわせた特化モデルの再構築に今回の技術を活用することで、再学習コストの大幅な削減が可能になると見ている。
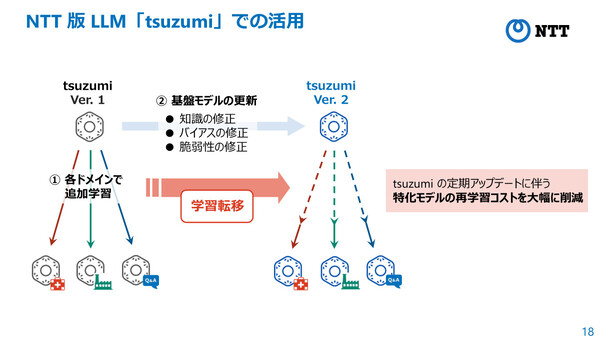
NTTが開発するLLM「tsuzumi」での活用
また、大規模AI連携技術である「AIコンステレーション」の実現にも貢献すると見ている。NTTが打ち出しているAIコンステレーション構想は、LLMなどの多様なAIモデルやルールを「環境」として与えることで、AI同士が相互に議論や訂正を行い、多様な視点から解を創出するという仕組みだ。今回の学習転移は、AIコンステレーションによって、多様なAIモデルを用意する際に必要となる大量の学習効果を効率化したり、デプロイされた大量のモデルの定期的な自動更新を効率化できたりといった効果が見込まれるという。
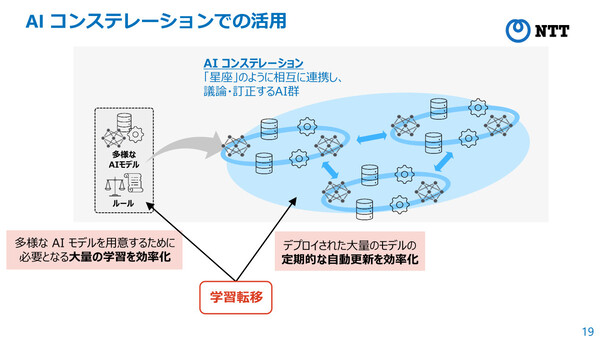
AIコンステレーションでの活用
なお同技術は、2024年5月7日からオーストリアのウイーンで開催される機械学習分野の最難関国際会議「ICLR(International Conference on Learning Representations ) 2024」で発表される。
本記事はアフィリエイトプログラムによる収益を得ている場合があります





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















