




LINEのAIカンパニーは7月15日、国立国会図書館が保有する247万点、2億2300万枚を超えるデジタル化資料のOCRテキストデータ化プロジェクトに、CLOVA OCRが採用されたことを発表した。
公式リリースより
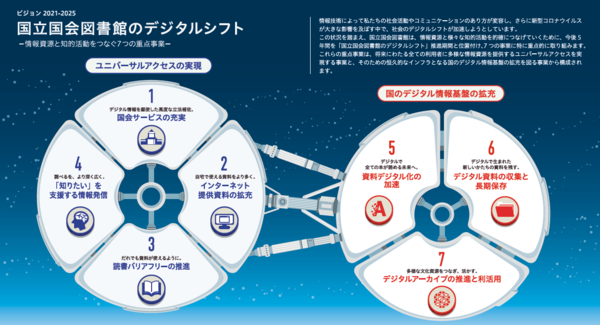
同図書館では「ビジョン2021-2025 国立国会図書館のデジタルシフト」の一環として、デジタルで全ての国内出版物が読める未来を目指し、2022年3月までに247万点のデジタル化資料をテキストデータ化する取り組みが行なわれている。
今回テキストデータ化するデジタル化資料の多くは昭和前期以前の資料であり、レイアウトも複雑なため、学習機能のない既存のOCRでは同プロジェクトに必要な精度に達しないことや、2億2300万枚を超えるデジタル化資料の処理に時間を要する点が課題だった。
CLOVA OCRは同プロジェクトで要求される項目に最適なOCRモデル(ルビ、割注、割書きといった特殊な文書に関しても人手を介さず読み取りする、等)を、スピーディーかつ高いクオリティーで開発・実現することが可能としている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















