




オンラインで開催されたAWS re:Invent 2020。12月11日に開催されたのは、AWSのインフラについてディープに語るピーター・デサントス氏の基調講演。前半は高い可用性を実現するための電力システムとAZ設計、サプライチェーンの多様化などについて詳細を披露した。

AWS インフラ&サポートSVP ピーター・デサントス氏
影響範囲と複雑さと考慮した結果、スイッチギアとUPSは自作
AWSはどのようにシステムを運用しているのか? システムを構築するユーザーにとっては、AWSが果たして信頼に耐えうるプロバイダーなのかという観点で気になるトピックであり、大規模なシステム運用のノウハウを自身に取り込みたいと考えたいとユーザーも多いだろう。
デサントス氏は、「自分たちは変であることに誇りに思っている。過去10年以上にわたって、私たちのリーダーが語った言葉は書き写してある」と語り、「素晴らしいオペレーターになるための近道はない」という言葉を挙げる。運用のパフォーマンスを上げるためには、長期的なコミットメントと小さな意思決定の積み重ねが必要になるが、AWSの場合はAmazonで培ってきた物流のオペレーションのノウハウと実績とテクノロジーの組み合わせに一日の長がある。また、「Design for Failure」を謳うAWSでは、障害が起こることを前提としてシステムの設計や運営が行なわれているという。

障害前提の設計を目指すAWS
そんなデサントス氏がフォーカスしたのはデータセンターの電力供給システムだ。通常データセンターにはIT機器に電力を供給するための配電設備があり、停電などで電力供給の異常を検知したら、スイッチギアが無停電源装置(UPS)からのバッテリ供給に切り替え、予備発電機を起動する。これ自体はシンプルな仕組みだが、スイッチギアがきちんと動かなかったり、予備発電機のメンテナンスを怠ったために、停電時にうまく電源供給ができなかったという事故はよく起こる。ITの運用担当が寝られない理由だ。
システムの可用性は、障害の影響範囲とシステムの複雑さを考慮すべき事項だとデサントス氏は指摘する。たとえば、電力供給システムのコンポーネントを例にすると、電流のオンとオフを切り替えるだけのスイッチギアは複雑とはほど遠い。「大きくて、すごく重要だが、基本的には回路とブレーカーの集まり、ファームウェアと呼ばれるシンプルなソフトウェアで構成されている」とデサントス氏は指摘する。しかし、シンプルなファームウェアでも不具合は起こりえる。実際に2019年8月に起こった東京リージョンの大規模障害は冷却システムのファームウェアの障害が原因だった。

複雑なサードパーティの配電設備
サードパーティのファームウェアに障害があった場合、ベンダーは不具合を再現するためには数週間から数ヶ月が費やす。フィックスされたファームウェアはエンジニアが手動で全機に適用しなければならないため、問題解決までは概して年単位で時間がかかってしまう。しかも、ベンダー製品は顧客ごとのユースにカバーするため、ファームウェアが複雑になりがちで、障害にもつながりやすい。そのため、AWSではスイッチギアを自作し、配電システムを制御しているという。「キラキラした機能はない。しかし、非常に重要な仕事を完璧にこなすことに注力した」とデサントス氏は語る。
一方のUPSはスイッチギアに比べればかなり複雑な電気機器だ。機能的にもリッチだし、鉛電池の塊というヘビーメタルなので、専用の部屋が必要になる。障害の影響範囲はスイッチギアと同じだが、複雑さが大きく異なるというわけだ。現在、多くのデータセンターでは障害を前提に電源も二系統で供給されており、UPSも冗長化されているが、複雑で大型なUPSで障害が起こると、影響は甚大だ。
そこでAWSがとったのはラック単位で利用できるマイクロバッテリとカスタム電源の採用だ。これによりサードパーティの大型UPSに依存しないでソフトウェアを自らコントロールできる。バッテリ交換も無停止で行なえるため、障害の影響範囲も小さく抑えることが可能になるという。

マイクロUPSとも言えるラック単位でのバッテリを採用
高可用性をインフラレベルで実現するAZの再考察
「われわれはインフラの可用性を挙げるためにつねに投資を続けている。ただ、いくら設計が正しくても、運用が優れていても、どうしても障害は起こりうる」とデサントス氏は指摘する。確かに火災、台風、洪水など自然災害を想定するのであれば、可用性はサーバーやデータセンター単位で担保できない。そのため、AWSは長らくAZ(Availability Zone)という概念を取り入れている。
AZの考え方はAmazon.comでの知識とノウハウを基盤としている。シアトルにあるデータセンターと同じシステムを東海岸にも作って両者を同期させるという標準的な可用性モデルからスタートしているが、物理的な距離の制約からどうしても遅延が発生する。しかし、リアルタイム性がきわめて重要であり、わずかな遅延がトランザクションに影響してしまうため、結局データセンターを近づける必要が出てしまう。
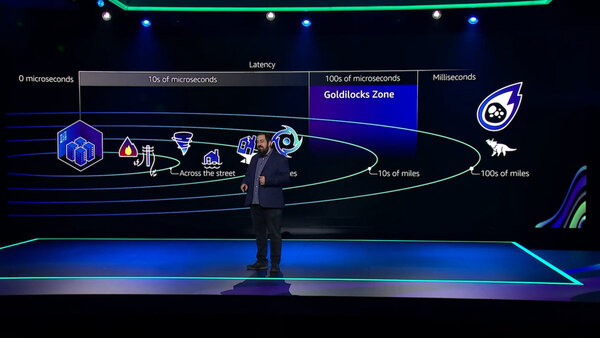
物理的な距離と遅延、災害の影響範囲を考慮
しかし、データセンターを近づけすぎると、同じ自然災害の影響を受けることになる。この距離と遅延のトレードオフを考慮した結果として、生まれたのがAZだ。複数のデータセンター群から構成されるAZは、AWSでは明確に定義されており、データセンターやAZ間の距離にもきちんと意味がある。
一方で、他のクラウド事業者はこのAZの概念がかなりあいまいだという。「“通常”や”一般的には”といった表現が散見されるし、どれくらいAZ間が離れているかも明確になっていない」とデサントス氏は指摘する。また、特定のリージョン(Selected Region)という表現もあいまい。「私が他のクラウド事業者を調べたところ、AZがあるのは12リージョンだけで、残りの40リージョンはAZはない。(その事業者では)南米、アフリカ、中東、中国、韓国などにはAZはない」とデサントス氏は語る。
現在、AWSは24の独立したリージョンがあるが、今年は南アフリカのケープタウンとイタリアのミラノに新たなリージョンが開設され。スイス、スペイン、インドネシアにも新たなリージョンが生まれる予定。また、インド、日本、オーストラリアには2つめのリージョンが予定されている。
もちろん、AWSは自然災害のみならず、人為的なミス(ヒューマンエラー)からもインフラを守るべく取り組んでいるという。「(システムにとって)人間が一番大きな問題となる場合がある。しかも悪意のない人間だ。人が触るものは、すべて人は壊せる」(デサントス氏)とのことで、各コンポーネントを完全に独立させた上で、統一された認証システムでユーザー管理を徹底している。
さらにAWSのリージョンを構成する機材の安定的な調達も重要だ。機材の調達はストライキや火事といった短期的な理由、貿易摩擦のような長期的な理由で滞ることがあり、新型コロナウイルスの影響を受けた2020年はサプライチェーンの脆弱性が浮き彫りになった。こうした事態に備え、AWSでは以前からサプライヤーの地理的な分散や多様化を進めてきたという。

サプライチェーンの多様化・地理的分散も推進
データセンターで利用する4つのコンポーネントを見てみると、以前は4カ国で29のサプライヤーだったが、2015年以降は7カ国で約3倍のサプライヤーに拡大されているという。「今年の困難な状況にあっても、地理的に多様なサプライチェーン、オペレーションのプラクティス、そしてキャパシティプランニングによって、お客さまは無停止でスケールすることができた」とデサントス氏はアピールした。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



