

テクノロジーに興味がある人なら、身近な製品の裏側って気になるもの。そんな知的欲求を満たしてくれるセッションが、昨年の夏に行なわれたre:Union 2018 Osakaには用意されていた。Nintendo Switchの裏側にあるシステムを紹介する「Nintendo Switch向けプッシュ通知システム『NPNS』」と題して、任天堂 ネットワークシステム部の渡邉 大洋さんが語ったセッションだ。フレンド登録したユーザーのゲームプレイ通知など、見慣れたあのメッセージは、こうやって送られていたのだ。

任天堂ネットワークシステム部 渡邉 大洋さんがSwitchのプッシュ通知システムについて解説
想定同時接続数1億台のリアルタイム通信インフラをAWSに構築
「実はこのセッション、AWS Summit Tokyoでもやったので聴いたことがある人がいるかもしれません。が、そこは今日初めて聴いたようなテンションで聴いてください」(渡邉さん)
という出足で会場の笑いをさらった渡邉さんにならって私も書いておこう。実はこのイベント、記事より何ヶ月も前に開催されたものなのですでに同じ話を他で聴いたことがある人がいるかもしれない。が、そこは初めて知る情報のようなテンションで読んでいただきたい。
さて、話題の中心はセッションタイトルにある通り、Nintendo Switchのプッシュ通知システムだ。Nintendo Switchについてはいまさら紹介しなければならないような製品ではないだろう。すでに世界で2000万台以上を販売している、あのゲーム機だ。プッシュ通知は、フレンドがオンラインになったときのほか、スマートフォンやPCで購入したアプリのダウンロード開始指示、完了通知などに使われる。ちょっと面白いところでは、保護者が子どものゲーム利用状況を管理、監視できる『NintendoみまもりSwitch』からの設定変更通知などにも、同じプッシュ通知システムが使われている。Nintendo Push Notification Serviceを略して、社内では「NPNS」と呼ばれているそうだ。

プッシュ通知とはNintendo Switchの画面左上にぷちっと表示されるアレだ
「フレンドの状況などを伝えるという性質上、リアルタイム性が重視されます。そこで定期的なポーリングではなく常時接続を前提にシステムを構築しました。求めたのは、1億台の常時接続に耐えるスケーラビリティ、無停止デプロイが可能な運用性です」(渡邉さん)
リアルタイムといっても、フレンドがオンラインになったことをミリ秒単位で正確に知る必要はない。数秒以内に通知が届けば正常、システム異常時でも数分程度の遅延に抑えるという、ベストエフォート型の性能基準を採用し、インフラコストを抑えている。
ロードバランサー不使用、ヘルスチェックとスケーリングに一工夫
1億台の常時接続に耐えるスケーラビリティと聞き、ロードバランサー配下にサーバーが並んでいる構成を思い浮かべた読者は少なくないのではないだろうか。筆者もそのひとりで、こりゃ大型のロードバランサーが必要だなと反射的に考えた。が、NPNSではロードバランサーを使っていないという。
「AWSには3つのロードバランサーがありますが、いずれも今回の案件には合いませんでした。そこでRoute53に全ノードのAレコードを列記してラウンドロビンで回しています。外部向けのインターフェイスを増やしたくなかったので、ディスカバリも使っていません」(渡邉さん)
そんな装備で大丈夫か?と思ってしまったが、求める安定性をこのシステム構成で充分に確保できているそうだ。プッシュ通知に使っているのは、メッセンジャーなどにも使われるリアルタイム通信プロトコルであるXMPP。独自プロトコルを使うよりも既存プロトコルを利用した方が開発速度や費用面で有利と判断した。プッシュ通知を扱うXMPPクラスターの他に、ID管理などに使うConsumer APIとサーバー間連携などに使うProvider APIを用意した。
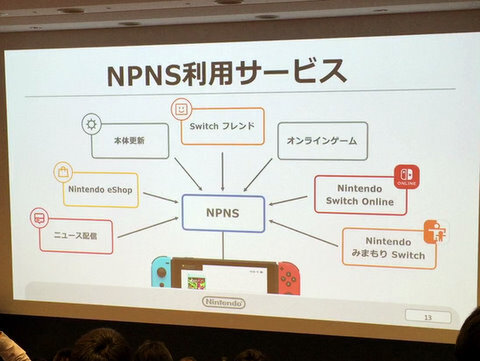
プッシュ通知以外にもAPIを通じて関連サービスと接続する
ちなみにロードバランサーを使わなかった理由は次の3つ。まずClassic Load Balancerは、常時接続には向いていないと公式にアナウンスされている。Application Load BalancerはHTTPに特化しているので、XMPPを使う今回の要件には見合わなかった。さらにNetwork Load Balancerはリリースタイミングの兼ね合いで検証時間が取れそうにないことから、採用を見送ったという。
ロードバランサーを使っていないので、ヘルスチェックや接続先の移行なども自前で構築しなければならない。NPNSではConsulとAuto Scalingを使ってサーバーのヘルスチェックを行なっている。Consulがアンヘルシーなサーバーを検知すると、Route53から該当IPアドレスを削除する。このときAuto Scaling側でもアンヘルシーな状態を検知し、同じXMPPクラスター内に新しくサーバーを立ち上げる。Consulが新しいサーバーのヘルスチェックを行い、クリアすればRoute53に新サーバーのIPアドレスが書き込まれ、旧サーバーから新サーバーへの移行が始まる。こうした段階的な移行を、任天堂では「ドリップ処理」と呼んでいる。
「ブルーグリーンデプロイを採用しているので、移行中は1つのXMPPクラスター内で新旧両方のサーバーが並行して稼動しています。その状態で、古いサーバーに接続しているユーザーを一定レートで切断すると、自動的に新しいサーバーへと再接続されます。こうして時間をかけて接続を移す『ドリップ処理』を行なうことで、一斉再接続による過負荷状態に陥ることを避けています」(渡邉さん)

アンヘルシーなサーバーから新規サーバーへ順次ユーザーを移行するドリップ処理
課題は、一時的ではあるが移行中にサーバーコストが二重にかかってしまうことと、ユーザーが増えるにしたがってドリップ処理に要する時間が長くなってしまうこと。処理自体は自動化されているが、ドリップ処理には約2時間かかっている。
既存プロトコルの良さを活かしつつ細かく通信をチューニング
XMPPクラスターを構築するために使っているのは、Erlang言語で開発されているejabberd。処理系レベルでクラスタリングに対応しており、大規模な利用実績があったことから選択された。セキュリティを確保するため、通信はXMPP on TLSで行なわれる。計算上はr3.largeで1サーバーあたり72万接続程度まで耐えられると考えたが、CPUとメモリに余裕があるのに同時接続数が伸びないという現象に見舞われた。
「調べてみたところ、Security Groupで設定されているセッション数の上限に引っかかっていました。限界まで接続数を増やすためにSecurity Groupを無効にし、代わりにNetwork ACLsで外部からのアクセスを制限することにしました」(渡邉さん)
実際に運用し始めてから悩まされたのは、TCP切断対策だ。常時接続を維持するために定期的にKeep Aliveのパケットを送信するのだが、これが多すぎると通信コストがかさみ、少なすぎると切断される端末が多くなってしまう。本番環境で探りながら最適値を求め、ピーク時の切断を40%削減できたが、ユーザーの増加と共に最適値は変わるため最適化は今も続けられている。
「本番環境で運用し始めてわかったことは、L4のKeep Aliveパケットだけでは切断されるNintendo Switchが多いということでした。恐らくプロバイダー側で通信を最適化するため、重要ではないと判断したパケットを落としているのだと思います。それに対応するため、データを入れたパケットを送信するL7のKeep Alive処理を行なうことにしました。これでピーク時の切断を50%削減できています」(渡邉さん)
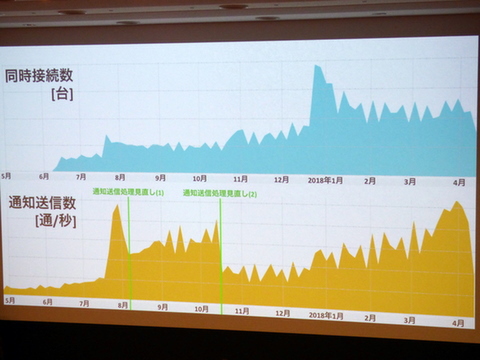
接続台数は増え続けているが、通知送信数は抑制できている
同時接続数は増え続けているが、通知送信処理の見直しにより、通知送信数は抑えられているという。同時接続数は700万台、ピーク時の通信は毎秒2万通、毎月コンスタントに約200億通の通知が送信されている。
「今後はNetwork Load Balancerの採用を検討しています。Network Load Balancerを組み込むことでConsulを外してシンプルな構成にできるのではないかと期待しています」(渡邉さん)
最後にejabberdの改造点について紹介されたが、テクニカルすぎて筆者にはさっぱり。エンジニアリング的な興味がある方は、このスライドから読み解いて欲しい。健闘を祈る。

XMPPクラスターを構成するejabberdの改造点はとても細かい
※この記事は2018年8月に大阪で開催されたJAWS-UGのイベント「re:Union 2018」のレポートです。
本記事はアフィリエイトプログラムによる収益を得ている場合があります






















