FIXER Tech Blog - AI/Machine Learning
実践:AIエージェントをAWSで構築する ― Strands Agentsで作り、AgentCoreにデプロイする
2026年06月08日 09時00分更新


本記事はFIXERが提供する「cloud.config Tech Blog」に掲載された「AWS AI Agent Workshopを経て」を再編集したものです(後編)。
この記事は前編からの続きです
【実践】Strands AgentsでAIエージェントを作ってみよう
理論を学んだら、実際に手を動かしてみましょう。ここでは、AWSのOSSフレームワーク「Strands Agents」を使ったエージェント構築のハンズオンを紹介します。
事前準備
・AWSアカウント(新規作成推奨)
・GitHubアカウント
・GitHub Codespaces を開発環境として使用(ローカル環境の構築不要)
まずGitHubで新規プライベートリポジトリを作成し、Codespacesを起動します。次に .env ファイルを作成してAWSの認証情報を記入します。
bash
# .env ファイルの内容 AWS_ACCESS_KEY_ID=(AWSアクセスキー) AWS_SECRET_ACCESS_KEY=(AWSシークレットアクセスキー) AWS_DEFAULT_REGION=ap-northeast-1
AWSのAmazon BedrockでAnthropicモデルを有効化し、必要な権限のみを付与した IAM ユーザーまたは IAM ロールを用意します。
ステップ1:まず3行でエージェントを動かす
python
from dotenv import load_dotenv
from strands import Agent
load_dotenv()
agent = Agent("jp.anthropic.claude-haiku-4-5-20251001-v1:0") agent("JAWS-UG主催のAI Builders Dayはどこで開催される?")
bash
pip install strands-agents python-dotenv python 1_agent.py
実行すると、エージェントは答えようとしますが、新しいイベント情報はモデルの学習データに含まれていないため「最新情報を確認できません」と返答します。これがツールなしのエージェントの限界です。
ステップ2:Web検索ツールを持たせてみる
Web検索サービス「Tavily」のAPIキーを取得し、.env に追記します。
python
import os
from dotenv import load_dotenv
from strands import Agent, tool
from tavily import TavilyClient
load_dotenv()
@tool
def search(query): """Web検索を実行するツール"""
tavily = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
return tavily.search(query)
agent = Agent(
model="apac.anthropic.claude-3-7-sonnet-20250219-v1:0",
tools=[search] )
agent("JAWS-UG主催のAI Builders Dayはどこで開催される?")
bash
pip install tavily-python python 2_tool.py
今度はエージェントが自律的に検索ツールを複数回呼び出し、イベントの開催場所を正確に答えてくれます。ReActループが実際に動いているのが確認できます。
AWSコミュニティイベントの「JAWS-UG主催のAI Builders Day」の開催場所について調べてみます。検索機能を使って情報を取得します。
Tool #1: search
検索結果からは、JAWS-UG主催のAI Builders Dayの正確な開催場所が明確に示されていません。検索結果に「AI Builders Day」についての言及はありますが、具体的な会場情報がありません。より具体的に検索してみましょう。
Tool #2: search
まだ明確な情報が見つかりません。より直接的に「AI Builders Day」のイベントページを探してみましょう。
Tool #3: search
より具体的な情報を探すため、イベントページの詳細を確認しましょう:
Tool #4: search
最初の検索結果に会場情報がありそうです。より詳細な情報を確認するためにイベントページの内容を確認します:
Tool #5: search
検索結果から情報が確認できました。JAWS-UG主催のAI Builders Dayの開催場所について以下の通りお伝えします:
JAWS-UG主催のAI Builders Dayは、「池袋サンシャインシティ ワールドインポートマートビル 展示ホールA」で開催されます。
住所:〒170-8630 東京都豊島区東池袋3-1
このイベントは、AWSで生成AIアプリを作る日本の「ビルダー」たちを盛り上げるための国内最大規模の開発者向けイベントとして開催されます。connpassのイベントページでも確認できる情報です。
ステップ3:MCPサーバーのツールを借りる
自分でツールを実装しなくても、公開されているMCPサーバーのツールをそのまま使えます。ここでは「AWS Knowledge MCPサーバー」を使ってAWSドキュメントを検索させてみます。
python
from dotenv import load_dotenv
from strands import Agent
from strands.tools.mcp import MCPClient
from mcp.client.streamable_http import streamablehttp_client
load_dotenv() # AWSが公開しているMCPサーバーに接続
mcp = MCPClient(
lambda: streamablehttp_client("https://knowledge-mcp.global.api.aws")
)
with mcp:
agent = Agent(
model="apac.anthropic.claude-3-7-sonnet-20250219-v1:0",
tools=mcp.list_tools_sync()
)
agent("Bedrock AgentCoreのランタイムってどんな機能?一言で説明して。")
エージェントはAWSドキュメントを検索・参照した上で回答してくれます。
bash
bash
pip install strands-agents-tools
python 3_mcp.py
以下のようなレスポンスが出力されます。
AWS Bedrock AgentCoreのランタイムについて調べたいですね。AWS Bedrock Agentについての情報を検索してみます。
Tool #1: aws___search_documentation
AWS Bedrock AgentCoreランタイムについての情報が見つかりましたので、詳細を確認するために主要なページを読んでみます。
Tool #2: aws___read_documentation
AWS Bedrock AgentCore Runtimeを一言で説明すると:
AWS Bedrock AgentCore Runtimeは、任意のフレームワークやモデルを使用したAIエージェントを安全かつスケーラブルに実行するための、セキュアでサーバーレスな目的特化型の実行環境です。
主な特徴は:
- フレームワークに依存しない設計(LangGraph、Strands、CrewAIなど対応)
- 最長8時間までの長時間実行サポート
- セッション分離による安全性の確保
- 100MBの大型ペイロード処理能力
- 使用量ベースの料金体系
- 組み込み認証機能
- エージェント特化の可観測性
ステップ4:マルチエージェントに挑戦
「Agent-as-Tools」パターンを使って、複数のエージェントを協調させてみます。監督者エージェントが、計算専門エージェントと俳句専門エージェントをツールとして呼び出します。
python
# 必要なライブラリをインポート
from dotenv import load_dotenv
from strands import Agent, tool
from strands_tools import calculator
# .envファイルから環境変数を読み込む
load_dotenv()
# サブエージェント1を定義
@tool
def math_agent(query: str):
agent = Agent(
model="apac.anthropic.claude-3-7-sonnet-20250219-v1:0",
system_prompt="ツールを使って計算を行ってください",
tools=[calculator]
)
return str(agent(query))
# サブエージェント2を定義
@tool
def haiku_agent(query: str):
agent = Agent(
model="jp.anthropic.claude-haiku-4-5-20251001-v1:0",
system_prompt="与えられたお題で五・七・五の俳句を詠んで"
)
return str(agent(query))
# 監督者エージェントの作成と実行
orchestrator = Agent(
model="jp.anthropic.claude-sonnet-4-5-20250929-v1:0",
system_prompt="与えられた問題を計算して、答えを俳句として詠んで",
tools=[math_agent, haiku_agent]
)
orchestrator("十円持っている太郎くんが二十円もらいました。今いくら?")
以下のコマンドを実行します。
pip install strands-agents-tools python 4_multi_agent.py
実行結果:
この問題を数学で解いた後、結果を俳句にします。
まずは計算してみましょう:
Tool #1: math_agent
太郎くんの所持金を計算しましょう。
太郎くんは最初に10円持っていて、そこに20円もらったので、合計金額を計算します。
Tool #1: calculator
太郎くんは今30円持っています。では、この答え(30円)を俳句にしてみましょう:
Tool #2: haiku_agent
## 太郎くんの三十円
三十円
夢広がる
駄菓子屋で
問題の答えは30円です。その結果を俳句にしました:
三十円
夢広がる
駄菓子屋で
監督者が役割分担を判断し、サブエージェントを呼び出して協働する様子がわかります。
【実践】AgentCoreにデプロイしてみよう
ローカルで動いたエージェントを本番環境で動作させます。AgentCoreを使えば、インフラの悩みなしにエージェントをデプロイできます。
AgentCore SDK でエージェントをAPIサーバー化
Strandsで実装したエージェントを、AgentCore SDKを用いてAPIとして呼び出せる形にします。
python
# 必要なライブラリをインポート
from strands import Agent
from strands.tools.mcp.mcp_client import MCPClient
from mcp.client.streamable_http import streamablehttp_client
from bedrock_agentcore.runtime import BedrockAgentCoreApp
# AgentCoreランタイム用のAPIサーバーを作成
app = BedrockAgentCoreApp()
# エージェント呼び出し関数を、APIサーバーのエントリーポイントに設定
@app.entrypoint
async def invoke_agent(payload, context):
# フロントエンドで入力されたプロンプトとAPIキーを取得
prompt = payload.get("prompt")
tavily_api_key = payload.get("tavily_api_key")
### この中が通常のStrandsのコード ----------------------------------
# Tavily MCPサーバーを設定
mcp = MCPClient(lambda: streamablehttp_client(
f"https://mcp.tavily.com/mcp/?tavilyApiKey={tavily_api_key}"
))
# MCPクライアントを起動したまま、エージェントを呼び出し
with mcp:
agent = Agent(
model="apac.anthropic.claude-3-7-sonnet-20250219-v1:0",
tools=mcp.list_tools_sync()
)
# エージェントの応答をストリーミングで取得
stream = agent.stream_async(prompt)
async for event in stream:
yield event
### ------------------------------------------------------------
# APIサーバーを起動
app.run()
スターターツールキットでデプロイ
AgentCore専用のCLIツール「スターターツールキット」を使えば、コマンド数回でデプロイが完了します。
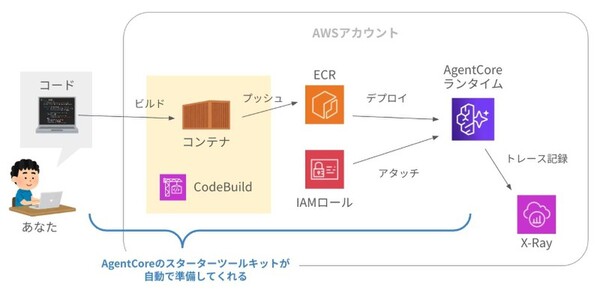
スターターツールキットのカバー範囲
デプロイに必要なライブラリを宣言し、新規作成したファイルに以下を記入します。
strands-agent bedrock-agentcore
以下のコマンドを実行します。
bash
# スターターツールキットをインストール
pip install bedrock-agentcore-starter-toolkit
# デプロイ設定(ウィザード形式、全部Enterで OK)
agentcore configure --entrypoint tavily_agent.py
# デプロイ実行(約1分でデプロイ完了)
agentcore launch
ウィザードでは以下が自動設定されます。
・ECRリポジトリの自動作成
・IAM実行ロールの自動作成
・CodeBuildによるコンテナビルド(Docker不要)
・短期メモリ(セッション内会話履歴)の自動有効化
デプロイ完了後に表示される「Agent ARN」をメモしておきます。
Streamlitでフロントエンドを作成して動作確認
PythonのUIライブラリ「Streamlit」でチャット画面を作り、デプロイしたエージェントに接続します。
python
# 必要なライブラリをインポート
import os, boto3, json
import streamlit as st
from dotenv import load_dotenv
# .envファイルから環境変数をロード
load_dotenv(override=True)
# サイドバーで設定を入力
with st.sidebar:
agent_runtime_arn = st.text_input("AgentCoreランタイムのARN")
tavily_api_key = st.text_input("Tavily APIキー", type="password")
# タイトルを描画
st.title("なんでも検索エージェント")
st.write("Strands AgentsがMCPサーバーを使って情報収集します!")
# チャットボックスを描画
if prompt := st.chat_input("メッセージを入力してね"):
# ユーザーのプロンプトを表示
with st.chat_message("user"):
st.markdown(prompt)
# エージェントの回答を表示
with st.chat_message("assistant"):
# AgentCoreランタイムを呼び出し
agentcore = boto3.client('bedrock-agentcore')
payload = json.dumps({
"prompt": prompt,
"tavily_api_key": tavily_api_key
})
response = agentcore.invoke_agent_runtime(
agentRuntimeArn=agent_runtime_arn,
payload=payload.encode()
)
### ここから下はストリーミングレスポンスの処理 ------------------------------------------
container = st.container()
text_holder = container.empty()
buffer = ""
# レスポンスを1行ずつチェック
for line in response["response"].iter_lines():
if line and line.decode("utf-8").startswith("data: "):
data = line.decode("utf-8")[6:]
# 文字列コンテンツの場合は無視
if data.startswith('"') or data.startswith("'"):
continue
# 読み込んだ行をJSONに変換
event = json.loads(data)
# ツール利用を検出
if "event" in event and "contentBlockStart" in event["event"]:
if "toolUse" in event["event"]["contentBlockStart"].get("start", {}):
# 現在のテキストを確定
if buffer:
text_holder.markdown(buffer)
buffer = ""
# ツールステータスを表示
container.info("🔍 Tavily検索ツールを利用しています")
text_holder = container.empty()
# テキストコンテンツを検出
if "data" in event and isinstance(event["data"], str):
buffer += event["data"]
text_holder.markdown(buffer)
elif "event" in event and "contentBlockDelta" in event["event"]:
buffer += event["event"]["contentBlockDelta"]["delta"].get("text", "")
text_holder.markdown(buffer)
# 最後に残ったテキストを表示
text_holder.markdown(buffer)
### ------------------------------------------------------------------------------
以下コマンドで起動できます。
bash
pip install streamlit streamlit run frontend.py
サイドバーにARNとTavily APIキーを入力すれば、クラウド上のエージェントとチャットできます。
運用監視:AgentCoreオブザーバビリティ
デプロイしたエージェントの動作はCloudWatchと連携したトレース機能で可視化できます。
AWSマネジメントコンソール → Bedrock AgentCore → エージェントランタイム → オブザーバビリティ から確認できます。各リクエストのトレースIDをクリックすると、エージェントがどのツールを何回呼び出したか、各ステップの所要時間などを細かく確認できます。LLMOpsツール(Langfuseなど)の簡易版が自動で使えるイメージです。
まとめ
本記事では、AWSのAI Agent Workshopの内容をもとに、AIエージェントの全体像を解説しました。
重要なポイントの整理:
・AIエージェントは Plan → Action → Feedback のループで自律的に動作します。
・ReAct・Reasoning・Tool Use・MCP がエージェントを支える主要技術です。
・MCPはAIのUSB Type-C — ツール接続の標準規格として急速に普及中です。
・Strands Agents なら数行のコードでエージェントが動く、GitHub Codespacesで簡単に試せます。
・@tool デコレータ一つで関数がエージェントのツールになります。
・MCPサーバーを使えば他者が公開したツールをそのまま借りられます。
・マルチエージェント(Agent-as-Tools) パターンで役割分担した協調動作が実現できます。
・Amazon Bedrock AgentCore × スターターツールキットで、インフラ知識なしでデプロイ完了できます。
・開発は 要件定義 → PoC → 本番化 → 運用改善 のサイクルで進める
2025年はAIエージェント元年と言われますが、技術の進歩は2026年以降もさらに加速することが予想されます。今こそエージェント開発の基礎を押さえ、実際に手を動かして試してみるのが最善の学習方法です。
まずはGitHub Codespacesを起動して、pip install strands-agents から始めてみてください。最初の3行エージェントが動いた瞬間の感動を、ぜひ体感してみてください🚀
柏木大空愛/FIXER
こんにちは、25卒の柏木です。趣味は本を読むことです。よろしくお願いします。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
TECH
生成AIは複雑な計算が苦手、だからExcelを使わせよう -
TECH
「AIで業務改善を!」……と走り出す前に考えるべきこと -
TECH
LLM、多すぎて迷いませんか? 「選択肢過多」と「決断疲労」の罠 -
TECH
「AIに頼んだけど、なんか違う」を卒業しよう。再現性を生むプロンプト設計のコツ -
TECH
GoogleのAIエージェント開発ツール「ADK」とは 簡単エージェントの作り方 -
TECH
AIの使いこなしに必要な「始動する力、試行力、感情を抑制する力」 AOAI Dev Dayレポート -
TECH
AI時代の「良いAPI」とは? APIとMCPの関係は? Azure OpenAI Service Dev Dayレポート -
TECH
新登場の「ChatGPT agent」は何ができる? どうすごい? -
TECH
Gemini CLIのここがすごい! Go+Vue3のアプリを作らせてみた -
TECH
アンケート分析」「トーク台本作成」を効率化、お客様サポート業務でのGaiXer活用 -
TECH
生成AIのプロンプトがうまく書けないときのアプローチ(演繹法/帰納法) - この連載の一覧へ




