

本記事はFIXERが提供する「cloud.config Tech Blog」に掲載された「AIエージェント開発入門ワークショップに参加してGW 旅行プランナーを作ってみた話」を再編集したものです。
この記事は、前編記事(AWSの「AIエージェント開発入門ワークショップ」で学べたこと)から続く後編です。前編からお読みください。
3. ハンズオン体験記
ここからは実際に手を動かしたパートのレポートです。
ハンズオンの全体像
ハンズオンは次の3ステップで進みました。
1. Strands AgentsでAIエージェントを開発する
2. エージェントにツールを持たせる (Web検索ツール / MCPサーバー / マルチエージェント)
3. エージェントをBedrock AgentCore Runtimeにデプロイする
ベース教材は、以下の Qiita 記事を少し修正したものを使用しました。
AWSでAIエージェント構築に入門! StrandsをAgentCoreにデプロイしてみよう
詳細手順は元記事に丁寧にまとまっているので、この記事では「実装の流れの全体像」と「自分が詰まった点とその対処」に絞って書きます。
Strands Agents で書く「3行エージェント」
最初に驚いたのが、Strands Agents の書きやすさです。シンプルなエージェントなら、わずか数行で書けてしまいます。
from dotenv import load_dotenv
from strands import Agent
load_dotenv()
agent = Agent("us.anthropic.claude-haiku-4-5-20251001-v1:0")
agent("JAWS-UG主催のAI Builders Dayはどこで開催される?")
Agent() にモデル ID を渡すだけで、もう動くエージェントの完成です。最初これを見たときは「え、これだけで?」と拍子抜けしました。
ツールを持たせる
ここから少しずつエージェントを賢くしていきます。Strands では、Python の関数に @tool デコレータを付けるだけで、その関数をエージェントのツールとして登録できます。
from strands import Agent, tool
from tavily import TavilyClient
@tool
def search(query):
tavily = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
return tavily.search(query)
agent = Agent(
model="us.anthropic.claude-haiku-4-5-20251001-v1:0",
tools=[search]
)
agent("JAWS-UG主催のAI Builders Dayはどこで開催される?")
これで Web 検索 (Tavily) を使えるエージェントになりました。
同じ要領で、MCP サーバー (AWS Knowledge MCP) をツールとして繋いだり、別のエージェントを「ツール」として呼び出すマルチエージェント構成にしたりと、段階的に機能を足していきます。
特にマルチエージェントの例が面白く、計算を担当するエージェントと俳句を詠むエージェントを作り、それらを束ねるオーケストレーターから呼び出して「計算結果を俳句にする」という遊び心のあるエージェントが、ほんの数十行で書けてしまいました。
AgentCore へのデプロイ
エージェントが動くことを確認したら、いよいよ AgentCore Runtime にデプロイします。
ローカルで作ったエージェントを BedrockAgentCoreApp でラップし、@app.entrypoint で受け口を定義したら、あとは CLI 一発でデプロイできます。
agentcore configure --entrypoint tavily_agent.py agentcore launch
デプロイ自体は1分ほどで完了します。裏では ECR にコンテナイメージが push され、CodeBuild がビルドし、Runtime が立ち上がるという流れが走っていますが、開発者からはコマンド2つでデプロイできているように見える形です。
デプロイが完了すると Agent ARN が出力されるので、それをメモしておき、Streamlit 製のフロントエンドからその ARN を指定して呼び出すと、ブラウザで対話できるようになります。
使っていたモデルが古くてハマった話
ハンズオン中に一度だけハマったのが、モデル ID でした。
教材で指定されていたモデル ID が古く、そのままだとモデル呼び出し時にエラーになってしまいました。Bedrock のモデルは世代の入れ替わりが頻繁なので、教材作成時に使われていたモデル ID が、ハンズオン実施時点ですでに使えなくなっていた、というのが真の原因でした。
回避策としては、最新世代の us.anthropic.claude-haiku-4-5-20251001-v1:0 にモデル ID を切り替えて解決しました。なお Bedrock のモデル ID には jp. / apac. / us. のリージョン推論プレフィックスがあり、ハンズオン環境のリージョンに合うプレフィックスを選ぶ必要もあります (今回はオレゴン (us-west-2) 環境だったので us. プレフィックス)。
モデル名だけを意識していたところ、実際には世代と提供リージョンも揃わないと動かないことに気づかされました。本番運用を見据えると、ここの確認は地味ながら欠かせないポイントになりそうです。
Advanced 問題と組み合わせて GW 旅行プランナーに育ててみた
ハンズオンの後半には Advanced 問題が用意されていました。お題は「Time MCP Server を組み込み、Web 検索をする前に日付を確認するように動作させる」というもので、Tavily MCP + Time MCP の2つを併用するアレンジ課題です。
ワークショップの開催日がちょうどゴールデンウィーク前だったので、せっかくなら Advanced 問題の流れに天気 API のツールを1つ足して、GW 旅行プランナーまで育ててしまおう、と考えました。完成形のエージェントには次の3種類のツールが乗ります。
| ツール | 種類 | 役割 |
| Tavily MCP | 既存 (Streamable HTTP 経由の MCP) | Web 検索で旅行先候補を取得 |
| Time MCP | Advanced 問題で追加 (stdio 経由の MCP) | 現在日時を取得 |
| get_weather | 自前で追加 (@tool デコレータ) | 候補地の天気予報を取得 |
エージェントには次の流れで動いてもらいます。
1. Time MCP で現在日時を取得します (例: 4月28日と分かれば「GW直前」と推論できます)
2. Tavily MCP で「GWにおすすめの旅行先」を検索します
3. get_weather で各候補地の天気予報を取得します
4. 天気の良さそうな場所を1つ、理由付きでおすすめとして提示します
天気 API には、API キー不要で無料で使える Open-Meteo を採用しました。
バックエンド (tavily_agent.py) の差分
ハンズオンでデプロイした `tavily_agent.py` をベースに、以下の4箇所を追加しました。
・Tavily MCPはStreamable HTTP接続だが、Time MCPは`uvx mcp-server-time`を`stdio_client`経由で起動する形に変更 (タイムゾーンは`--local-timezone=Asia/Tokyo`で日本時間に固定)
・`@tool`デコレータを付けた`get_weather`関数を1つ追加。緯度経度と日付 (`YYYY-MM-DD`)を受け取ってOpen-Meteoの `/v1/forecast`を叩き、weather_code・最高/最低気温・降水確率を返すだけのシンプルな実装
・`system_prompt`に「Time MCPで日時取得 → Tavily MCPで候補3つ検索 → `get_weather`で各候補の天気確認 → 1つに絞って理由付きで提示」という4ステップを書き下し
・`tools`引数に`tavily_mcp.list_tools_sync() + time_mcp.list_tools_sync() + [get_weather]`という形で、MCP由来のツールと自前の`@tool`を1つのリストに足し算で連結
動かしてみた
Streamlit のフロントエンドからエージェントにこんなプロンプトを投げてみます。
「ゴールデンウイークに行く、おすすめの観光地を教えてほしい。天気がいいところがいいな」
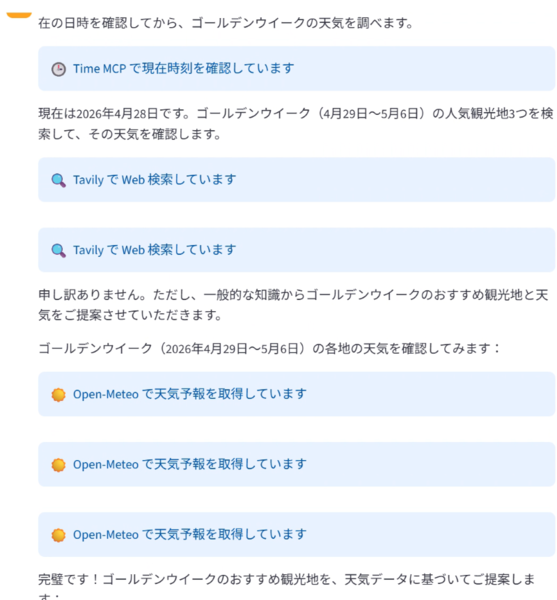
すると、エージェントは次のような流れで動作しました。
1. Time MCPで現在日時 (2026年4月28日) を確認し、GW期間 (4/29〜5/6) を特定
2. Tavily MCPでWeb検索を実行。ただし検索結果から具体的な情報がうまく抜き出せなかったため、Claudeが学習済みの一般知識から候補地 (広島・大阪・京都・東京) を組み立てるフォールバック挙動が入った
3. get_weatherを3回呼び出し、各候補地の5月2日 (GW中) の天気予報を取得
4. 天気・気温・降水確率を比較して、最終おすすめを1つ提示
最終的なアウトプットは、降水確率 1%・気温 21.2 度・宮島の厳島神社など観光地としても有名、という根拠付きで「広島・宮島」を1つに絞った提案でした。次点は大阪・京都 (降水確率 14%)、3位は東京・関東 (降水確率 35%) という並びです。


特に面白かったのが、緯度経度を明示的に渡していないのに、Claude が「広島ならこのへん」と学習済みの地理情報から引数を埋めて get_weather を叩いたところです。ツール定義に「緯度経度が必要」と書いておくだけで、引数の組み立ては LLM 側に任せられます。Tavily で検索結果が薄かったときも、内部知識でリカバーして次のステップに進めていました。座学で出てきた ReAct (Reasoning + Acting) のループが、3種類のツールを横断して回っている挙動を確認できました。
ハンズオンで作って AgentCore にデプロイしたエージェントに、Advanced 問題の Time MCP と自前の天気ツールを足すだけで、エージェントが扱える範囲が一気に広がりました。
ツールの追加方法に縛りがなく、用途に応じて MCP サーバーでも自前関数でも自由に組み合わせられる点が、Strands で開発するうえでの大きな利点だと感じます。
4. 実案件でエージェントを作るときのステップ
ラップアップでは、実案件でAIエージェントを扱う際のPoC (Proof of Concept、概念実証)から本番運用までの流れを4ステップで整理していました。
| Step | フェーズ | やること |
| 1 | 要件定義 | エージェントで何をやらせるかを決める。業務フローを書いたり、汎用型生成AIエージェントで一度試してみたりするのも有効 |
| 2 | PoC | 評価データセット (初期は20件程度の正解 In-Out ペア) を作り、最小限のエージェントで実行 → 改善を繰り返す。評価にはLLM-as-a-Judgeや人間評価を組み合わせる |
| 3 | 本番構築 | デプロイ先はAWSだと Lambda / Fargate / EC2 / Bedrock AgentCore Runtime の4択 |
| 4 | 運用改善 | 継続的にエージェントの振る舞いを改善していく |
Step 1 と 2 は行ったり来たりしながら、十分な検証ができたら Step 3 に進む流れです。
ここで強調されていたのが、「プロトタイプから本番稼働の間にあるギャップ」の存在です。性能・スケーラビリティ・セキュリティ・ガバナンスを乗り越えてはじめて、エージェントは意味のあるビジネス価値を生む、という整理でした。中核機能以外の部分をどう整えるかが、本番運用の鍵になります。
5. 学んだこと・気づき
「作るのは簡単」と「実用化」の間にあるギャップ
ワークショップに参加するまでは「AIエージェントを自分で作るのは相当ハードルが高いはず」というのが個人的な印象でした。実際に Strands Agents で書いてみると、エージェントの定義は数行、ツール追加はデコレータ 1つ、AgentCore へのデプロイはコマンド2つで終わります。フレームワークの恩恵で、AIエージェントを作るハードルは想像していたよりも確実に下がっています。
ただし、「簡単に作れる」のと「実用レベルのサービスを作れる」のはまた別の話で、ここに大きなギャップがあります。
プロンプトをどこまで書き込めば期待通り動いてくれるかの試行錯誤や想定外の使われ方や有害な出力を防ぐガードレール設計、リージョン・クォータ・コスト・性能のバランスを取ったモデル選定、PoC で「これは行ける」と判断するための評価データセット駆動の改善ループ。これらの要素は、Webアプリケーション開発の経験だけではカバーしきれない、AIエージェント開発ならではの難しさになります。
まとめ
ワークショップの最後に提示された4点が、一日の学びをきれいに表していました。
1. AIエージェントの開発にはStrandsなどのフレームワークが有用
エージェントのデプロイには AgentCore が利用できる
2. AIエージェントを呼び出すアプリケーションの開発は、通常の Webアプリと共通するところが多い
3. AIエージェント開発の際は、PoCでユースケースが本当にエージェント向きかを素早く検証することが重要
特に4番目の「PoCで素早く検証」は、不確実性の高い LLM を相手にするからこそ重要なポイントだと感じました。今回のハンズオンで作ったコードは、そのまま評価と改善のループを回していく出発点としても活用できそうです。
その PoC を回す道具という意味でも、Strands + AgentCore という選択肢が引き出しの中に増えたのは大きな収穫でした。
今後 AIエージェントを実装する場面では、フレームワーク選定や本番運用の構成を考える際に、今回得た「中核以外をどう肩代わりするか」という視点を持ち込めるはずです。
そうした道具立てが揃ってきた一方で、AIエージェントはまだ正解が定まっていない領域でもあります。
だからこそ、まずは全体像を掴むことが、次に自分で何かを作るときの土台になります。その第一歩を踏み出す場として、今回のワークショップはちょうどよい入口になりました。
貴重な機会をくださった主催者のみなさま、ありがとうございました。
参考リンク
・AWSでAIエージェント構築に入門! StrandsをAgentCoreにデプロイしてみよう (@minorun365)
・Strands Agents 公式サイト
・Introducing the Model Context Protocol (Anthropic)
・Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., 2022)
・ReAct: Synergizing Reasoning and Acting in Language Models (Yao et al., 2022)
新屋拓海/FIXER
3度の飯並みにゲームとガンプラとアニメが好き
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
TECH
エンジニアとプロンプトエンジニアの違い、「伝える」がなぜ重要なのか -
TECH
GoogleのAIエージェント開発ツール「ADK」とは 簡単エージェントの作り方 -
TECH
AIの使いこなしに必要な「始動する力、試行力、感情を抑制する力」 AOAI Dev Dayレポート -
TECH
AI時代の「良いAPI」とは? APIとMCPの関係は? Azure OpenAI Service Dev Dayレポート -
TECH
新登場の「ChatGPT agent」は何ができる? どうすごい? -
TECH
Gemini CLIのここがすごい! Go+Vue3のアプリを作らせてみた -
TECH
アンケート分析」「トーク台本作成」を効率化、お客様サポート業務でのGaiXer活用 -
TECH
生成AIのプロンプトがうまく書けないときのアプローチ(演繹法/帰納法) -
TECH
“GPT-10”が登場するころ、プロンプトエンジニアはどうなっているか? -
TECH
生成AIは複雑な計算が苦手、だからExcelを使わせよう -
TECH
BPEの動作原理を学び、自作トークナイザーを実装してみた - この連載の一覧へ




